 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unbiased and Robust Spatio-Temporal Scene Graph Generation and Anticipation
Nov 20, 2024Spatio-Temporal Scene Graphs (STSGs) provide a concise and expressive representation of dynamic scenes by modelling objects and their evolving relationships over time. However, real-world visual relationships often exhibit a long-tailed distribution, causing existing methods for tasks like Video Scene Graph Generation (VidSGG) and Scene Graph Anticipation (SGA) to produce biased scene graphs. To this end, we propose ImparTail, a novel training framework that leverages curriculum learning and loss masking to mitigate bias in the generation and anticipation of spatio-temporal scene graphs. Our approach gradually decreases the dominance of the head relationship classes during training and focuses more on tail classes, leading to more balanced training. Furthermore, we introduce two new tasks, Robust Spatio-Temporal Scene Graph Generation and Robust Scene Graph Anticipation, designed to evaluate the robustness of STSG models against distribution shifts. Extensive experiments on the Action Genome dataset demonstrate that our framework significantly enhances the unbiased performance and robustness of STSG models compared to existing methods.
Grasping Trajectory Optimization with Point Clouds
Mar 08, 2024We introduce a new trajectory optimization method for robotic grasping based on a point-cloud representation of robots and task spaces. In our method, robots are represented by 3D points on their link surfaces. The task space of a robot is represented by a point cloud that can be obtained from depth sensors. Using the point-cloud representation, goal reaching in grasping can be formulated as point matching, while collision avoidance can be efficiently achieved by querying the signed distance values of the robot points in the signed distance field of the scene points. Consequently, a constrained non-linear optimization problem is formulated to solve the joint motion and grasp planning problem. The advantage of our method is that the point-cloud representation is general to be used with any robot in any environment. We demonstrate the effectiveness of our method by conducting experiments on a tabletop scene and a shelf scene for grasping with a Fetch mobile manipulator and a Franka Panda arm.
Towards Scene Graph Anticipation
Mar 07, 2024Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
CaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023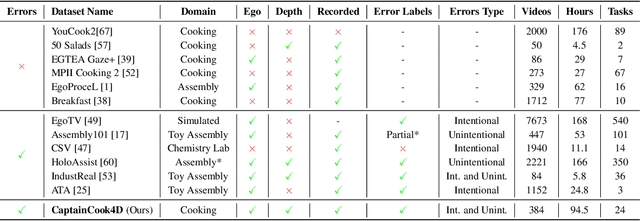


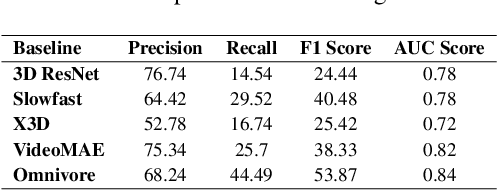
Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning