 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectively Contextual Bandits
May 09, 2022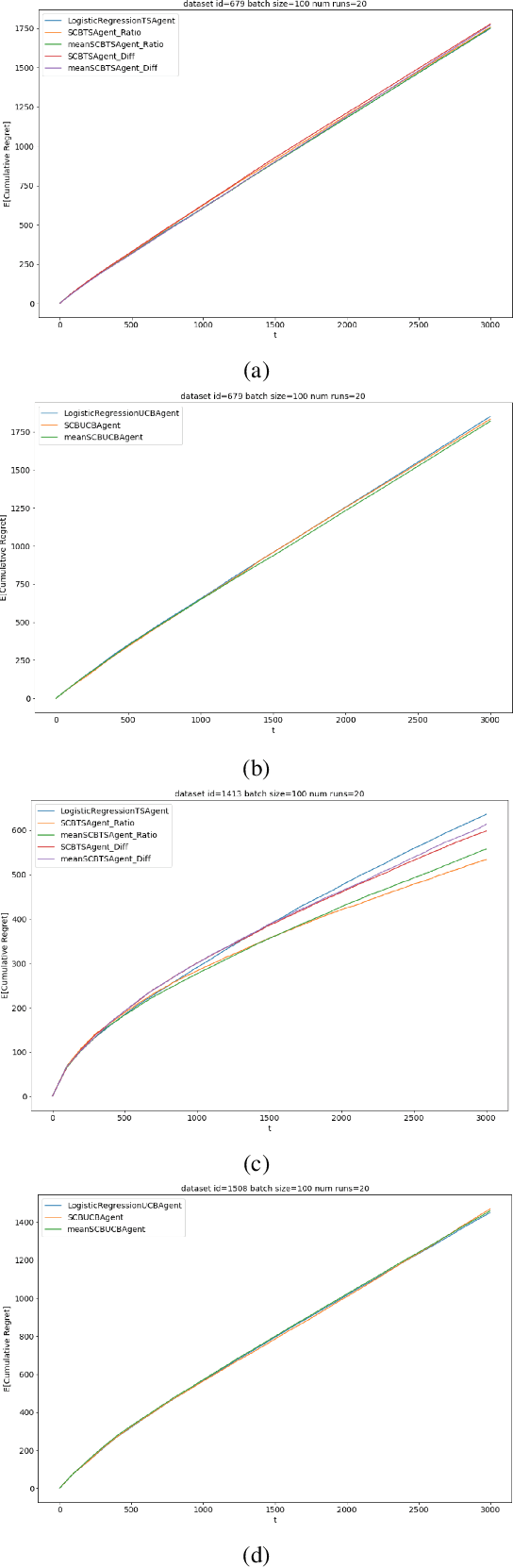
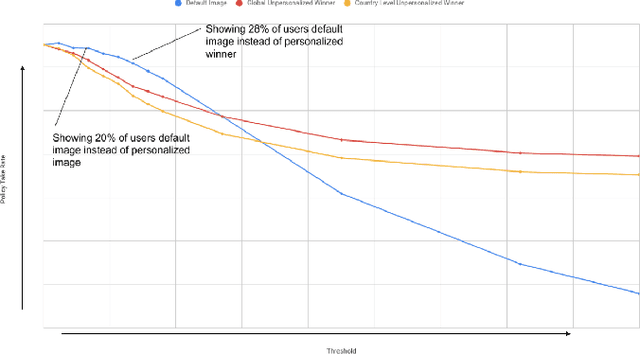
Contextual bandits are widely used in industrial personalization systems. These online learning frameworks learn a treatment assignment policy in the presence of treatment effects that vary with the observed contextual features of the users. While personalization creates a rich user experience that reflect individual interests, there are benefits of a shared experience across a community that enable participation in the zeitgeist. Such benefits are emergent through network effects and are not captured in regret metrics typically employed in evaluating bandits. To balance these needs, we propose a new online learning algorithm that preserves benefits of personalization while increasing the commonality in treatments across users. Our approach selectively interpolates between a contextual bandit algorithm and a context-free multi-arm bandit and leverages the contextual information for a treatment decision only if it promises significant gains. Apart from helping users of personalization systems balance their experience between the individualized and shared, simplifying the treatment assignment policy by making it selectively reliant on the context can help improve the rate of learning in some cases. We evaluate our approach in a classification setting using public datasets and show the benefits of the hybrid policy.
Classroom Video Assessment and Retrieval via Multiple Instance Learning
Mar 25, 2014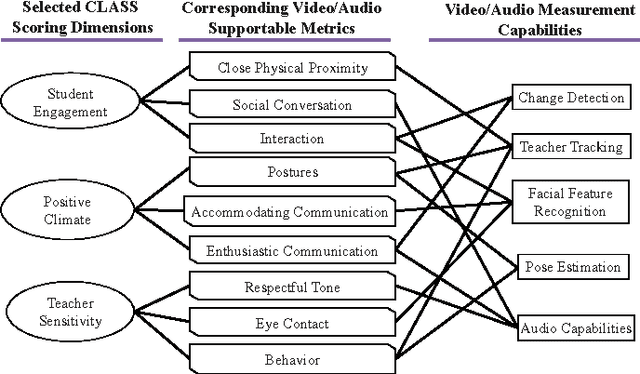
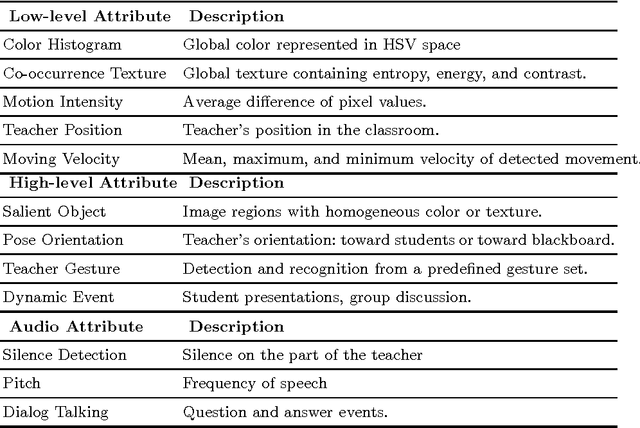


We propose a multiple instance learning approach to content-based retrieval of classroom video for the purpose of supporting human assessing the learning environment. The key element of our approach is a mapping between the semantic concepts of the assessment system and features of the video that can be measured using techniques from the fields of computer vision and speech analysis. We report on a formative experiment in content-based video retrieval involving trained experts in the Classroom Assessment Scoring System, a widely used framework for assessment and improvement of learning environments. The results of this experiment suggest that our approach has potential application to productivity enhancement in assessment and to broader retrieval tasks.
Behavior Pattern Recognition using A New Representation Model
Mar 20, 2013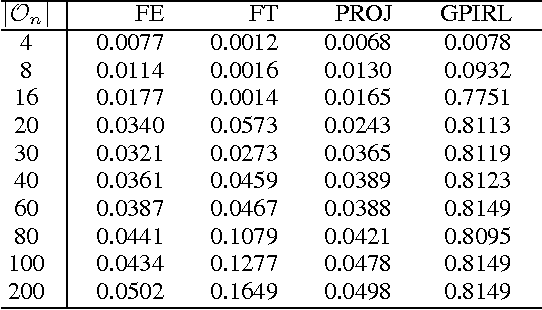
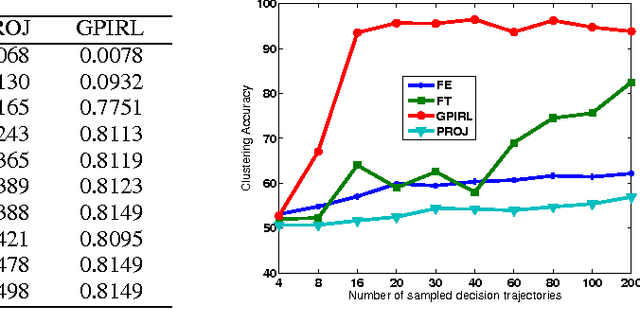
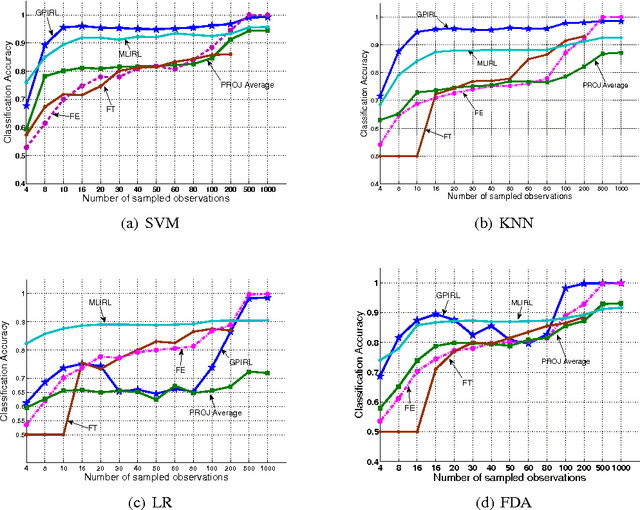
We study the use of inverse reinforcement learning (IRL) as a tool for the recognition of agents' behavior on the basis of observation of their sequential decision behavior interacting with the environment. We model the problem faced by the agents as a Markov decision process (MDP) and model the observed behavior of the agents in terms of forward planning for the MDP. We use IRL to learn reward functions and then use these reward functions as the basis for clustering or classification models. Experimental studies with GridWorld, a navigation problem, and the secretary problem, an optimal stopping problem, suggest reward vectors found from IRL can be a good basis for behavior pattern recognition problems. Empirical comparisons of our method with several existing IRL algorithms and with direct methods that use feature statistics observed in state-action space suggest it may be superior for recognition problems.
Inverse Reinforcement Learning with Gaussian Process
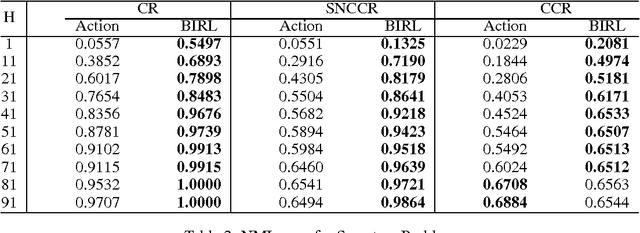
Jan 21, 2013

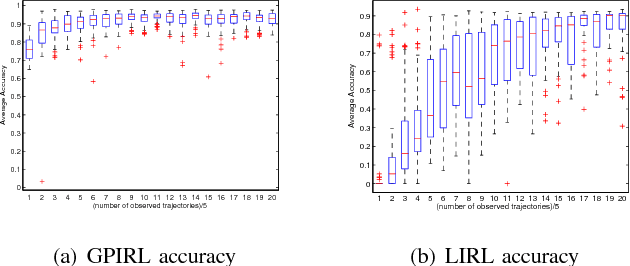

We present new algorithms for inverse reinforcement learning (IRL, or inverse optimal control) in convex optimization settings. We argue that finite-space IRL can be posed as a convex quadratic program under a Bayesian inference framework with the objective of maximum a posterior estimation. To deal with problems in large or even infinite state space, we propose a Gaussian process model and use preference graphs to represent observations of decision trajectories. Our method is distinguished from other approaches to IRL in that it makes no assumptions about the form of the reward function and yet it retains the promise of computationally manageable implementations for potential real-world applications. In comparison with an establish algorithm on small-scale numerical problems, our method demonstrated better accuracy in apprenticeship learning and a more robust dependence on the number of observations.