 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectively Contextual Bandits
May 09, 2022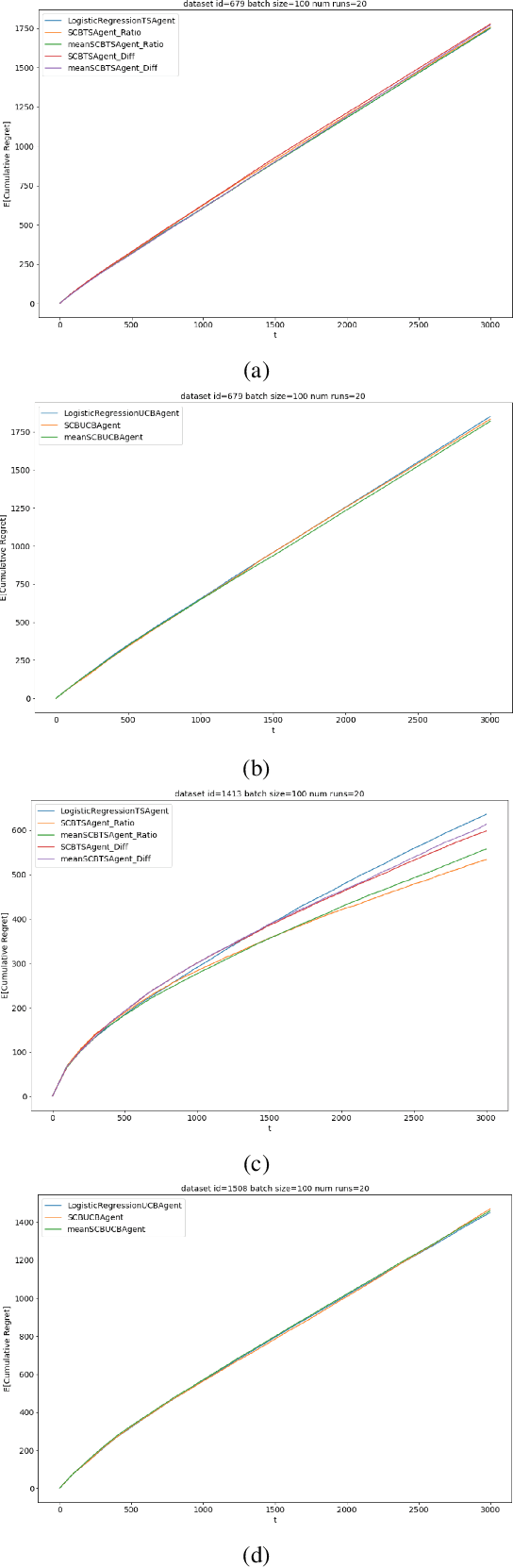
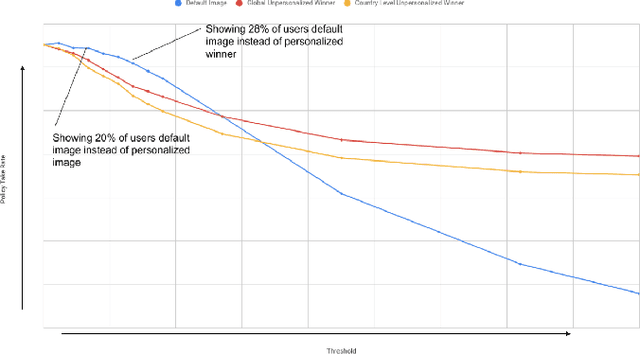
Contextual bandits are widely used in industrial personalization systems. These online learning frameworks learn a treatment assignment policy in the presence of treatment effects that vary with the observed contextual features of the users. While personalization creates a rich user experience that reflect individual interests, there are benefits of a shared experience across a community that enable participation in the zeitgeist. Such benefits are emergent through network effects and are not captured in regret metrics typically employed in evaluating bandits. To balance these needs, we propose a new online learning algorithm that preserves benefits of personalization while increasing the commonality in treatments across users. Our approach selectively interpolates between a contextual bandit algorithm and a context-free multi-arm bandit and leverages the contextual information for a treatment decision only if it promises significant gains. Apart from helping users of personalization systems balance their experience between the individualized and shared, simplifying the treatment assignment policy by making it selectively reliant on the context can help improve the rate of learning in some cases. We evaluate our approach in a classification setting using public datasets and show the benefits of the hybrid policy.
Risk Minimization from Adaptively Collected Data: Guarantees for Supervised and Policy Learning
Jun 03, 2021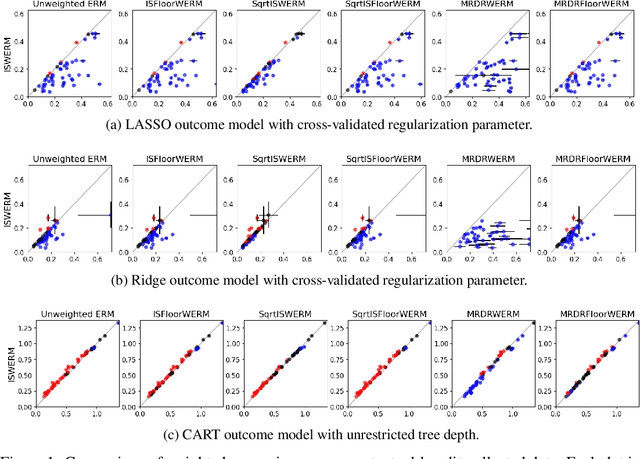

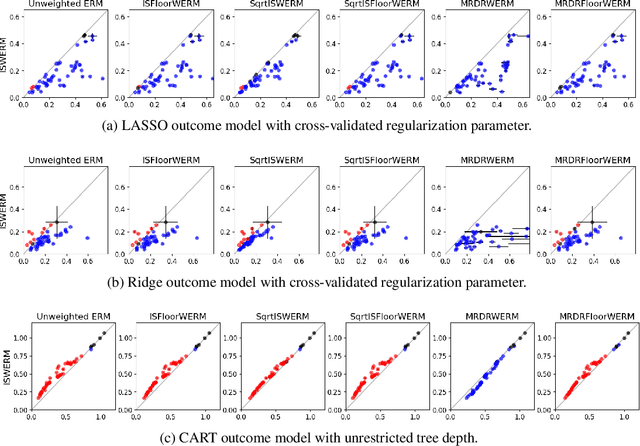
Empirical risk minimization (ERM) is the workhorse of machine learning, whether for classification and regression or for off-policy policy learning, but its model-agnostic guarantees can fail when we use adaptively collected data, such as the result of running a contextual bandit algorithm. We study a generic importance sampling weighted ERM algorithm for using adaptively collected data to minimize the average of a loss function over a hypothesis class and provide first-of-their-kind generalization guarantees and fast convergence rates. Our results are based on a new maximal inequality that carefully leverages the importance sampling structure to obtain rates with the right dependence on the exploration rate in the data. For regression, we provide fast rates that leverage the strong convexity of squared-error loss. For policy learning, we provide rate-optimal regret guarantees that close an open gap in the existing literature whenever exploration decays to zero, as is the case for bandit-collected data. An empirical investigation validates our theory.
Post-Contextual-Bandit Inference
Jun 01, 2021
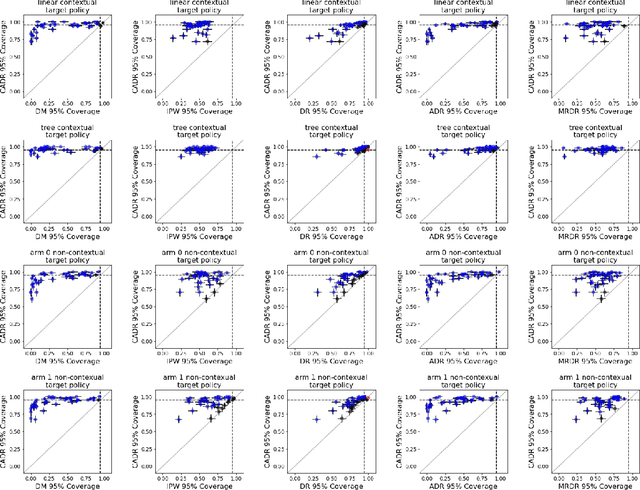
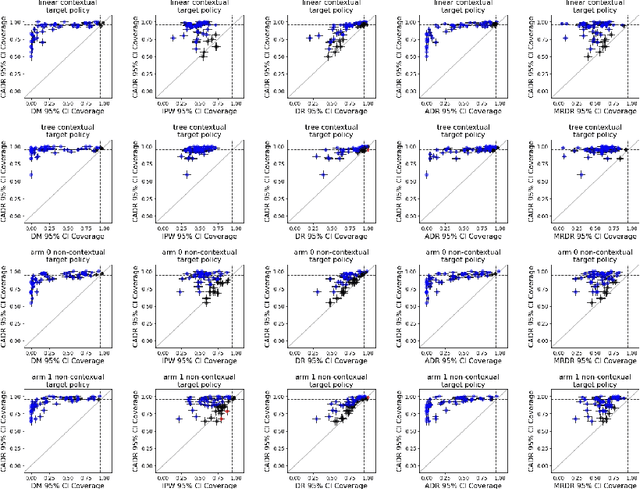
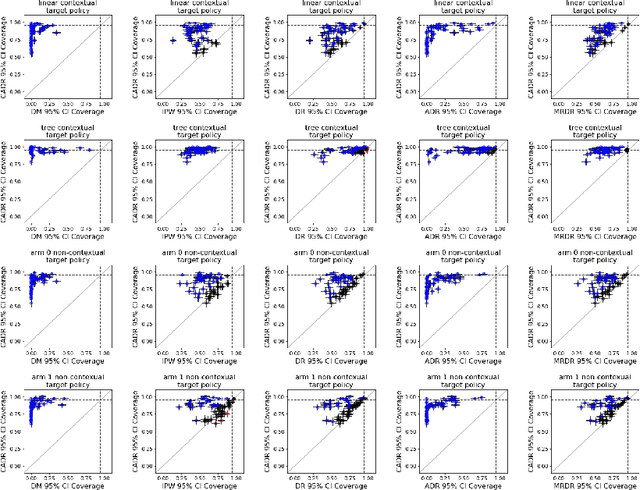
Contextual bandit algorithms are increasingly replacing non-adaptive A/B tests in e-commerce, healthcare, and policymaking because they can both improve outcomes for study participants and increase the chance of identifying good or even best policies. To support credible inference on novel interventions at the end of the study, nonetheless, we still want to construct valid confidence intervals on average treatment effects, subgroup effects, or value of new policies. The adaptive nature of the data collected by contextual bandit algorithms, however, makes this difficult: standard estimators are no longer asymptotically normally distributed and classic confidence intervals fail to provide correct coverage. While this has been addressed in non-contextual settings by using stabilized estimators, the contextual setting poses unique challenges that we tackle for the first time in this paper. We propose the Contextual Adaptive Doubly Robust (CADR) estimator, the first estimator for policy value that is asymptotically normal under contextual adaptive data collection. The main technical challenge in constructing CADR is designing adaptive and consistent conditional standard deviation estimators for stabilization. Extensive numerical experiments using 57 OpenML datasets demonstrate that confidence intervals based on CADR uniquely provide correct coverage.
Doubly-Adaptive Thompson Sampling for Multi-Armed and Contextual Bandits
Feb 25, 2021
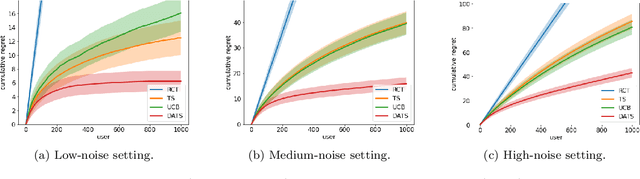
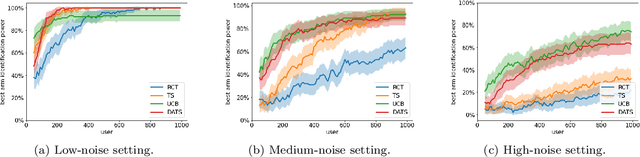
To balance exploration and exploitation, multi-armed bandit algorithms need to conduct inference on the true mean reward of each arm in every time step using the data collected so far. However, the history of arms and rewards observed up to that time step is adaptively collected and there are known challenges in conducting inference with non-iid data. In particular, sample averages, which play a prominent role in traditional upper confidence bound algorithms and traditional Thompson sampling algorithms, are neither unbiased nor asymptotically normal. We propose a variant of a Thompson sampling based algorithm that leverages recent advances in the causal inference literature and adaptively re-weighs the terms of a doubly robust estimator on the true mean reward of each arm -- hence its name doubly-adaptive Thompson sampling. The regret of the proposed algorithm matches the optimal (minimax) regret rate and its empirical evaluation in a semi-synthetic experiment based on data from a randomized control trial of a web service is performed: we see that the proposed doubly-adaptive Thompson sampling has superior empirical performance to existing baselines in terms of cumulative regret and statistical power in identifying the best arm. Further, we extend this approach to contextual bandits, where there are more sources of bias present apart from the adaptive data collection -- such as the mismatch between the true data generating process and the reward model assumptions or the unequal representations of certain regions of the context space in initial stages of learning -- and propose the linear contextual doubly-adaptive Thompson sampling and the non-parametric contextual doubly-adaptive Thompson sampling extensions of our approach.
Doubly robust off-policy evaluation with shrinkage
Jul 22, 2019

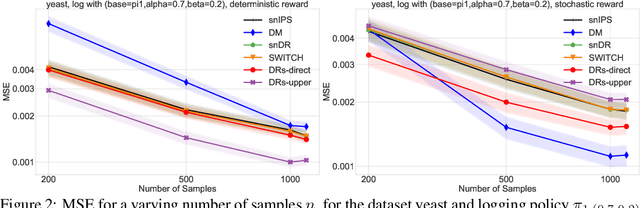
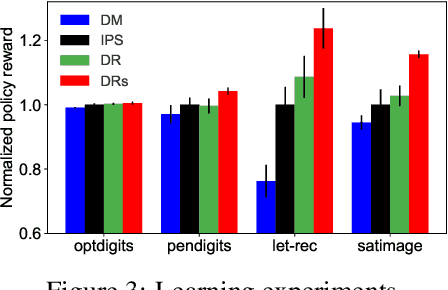
We design a new family of estimators for off-policy evaluation in contextual bandits. Our estimators are based on the asymptotically optimal approach of doubly robust estimation, but they shrink importance weights to obtain a better bias-variance tradeoff in finite samples. Our approach adapts importance weights to the quality of a reward predictor, interpolating between doubly robust estimation and direct modeling. When the reward predictor is poor, we recover previously studied weight clipping, but when the reward predictor is good, we obtain a new form of shrinkage. To navigate between these regimes and tune the shrinkage coefficient, we design a model selection procedure, which we prove is never worse than the doubly robust estimator. Extensive experiments on bandit benchmark problems show that our estimators are highly adaptive and typically outperform state-of-the-art methods.
Balanced Linear Contextual Bandits
Dec 15, 2018



Contextual bandit algorithms are sensitive to the estimation method of the outcome model as well as the exploration method used, particularly in the presence of rich heterogeneity or complex outcome models, which can lead to difficult estimation problems along the path of learning. We develop algorithms for contextual bandits with linear payoffs that integrate balancing methods from the causal inference literature in their estimation to make it less prone to problems of estimation bias. We provide the first regret bound analyses for linear contextual bandits with balancing and show that our algorithms match the state of the art theoretical guarantees. We demonstrate the strong practical advantage of balanced contextual bandits on a large number of supervised learning datasets and on a synthetic example that simulates model misspecification and prejudice in the initial training data.
Estimation Considerations in Contextual Bandits
Jul 13, 2018
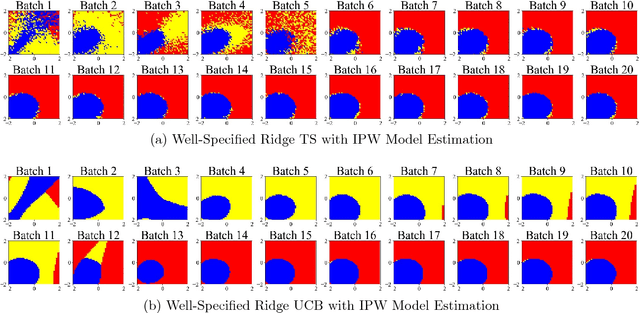
Although many contextual bandit algorithms have similar theoretical guarantees, the characteristics of real-world applications oftentimes result in large performance dissimilarities across algorithms. We study a consideration for the exploration vs. exploitation framework that does not arise in non-contextual bandits: the way exploration is conducted in the present may affect the bias and variance in the potential outcome model estimation in subsequent stages of learning. We show that contextual bandit algorithms are sensitive to the estimation method of the outcome model as well as the exploration method used, particularly in the presence of rich heterogeneity or complex outcome models, which can lead to difficult estimation problems along the path of learning. We propose new contextual bandit designs, combining parametric and non-parametric statistical estimation methods with causal inference methods in order to reduce the estimation bias that results from adaptive treatment assignment. We provide empirical evidence that guides the choice among the alternatives in different scenarios, such as prejudice (non-representative user contexts) in the initial training data.
Scalable Coordinated Exploration in Concurrent Reinforcement Learning
May 23, 2018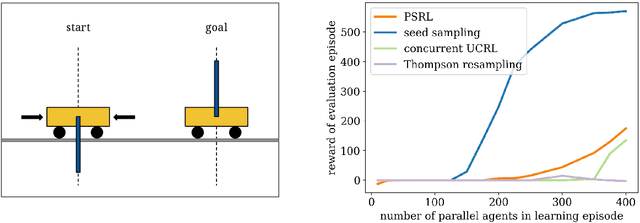

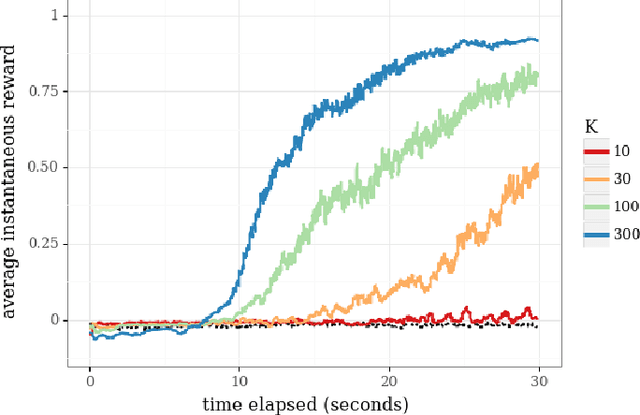
We consider a team of reinforcement learning agents that concurrently operate in a common environment, and we develop an approach to efficient coordinated exploration that is suitable for problems of practical scale. Our approach builds on seed sampling (Dimakopoulou and Van Roy, 2018) and randomized value function learning (Osband et al., 2016). We demonstrate that, for simple tabular contexts, the approach is competitive with previously proposed tabular model learning methods (Dimakopoulou and Van Roy, 2018). With a higher-dimensional problem and a neural network value function representation, the approach learns quickly with far fewer agents than alternative exploration schemes.
Coordinated Exploration in Concurrent Reinforcement Learning
Feb 05, 2018


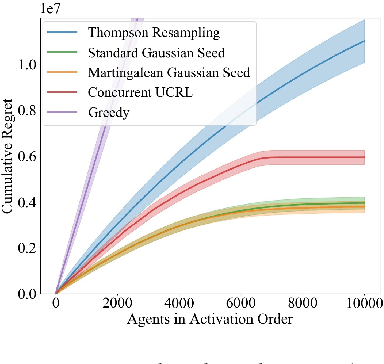
We consider a team of reinforcement learning agents that concurrently learn to operate in a common environment. We identify three properties - adaptivity, commitment, and diversity - which are necessary for efficient coordinated exploration and demonstrate that straightforward extensions to single-agent optimistic and posterior sampling approaches fail to satisfy them. As an alternative, we propose seed sampling, which extends posterior sampling in a manner that meets these requirements. Simulation results investigate how per-agent regret decreases as the number of agents grows, establishing substantial advantages of seed sampling over alternative exploration schemes.