 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation Considerations in Contextual Bandits
Paper and Code
Jul 13, 2018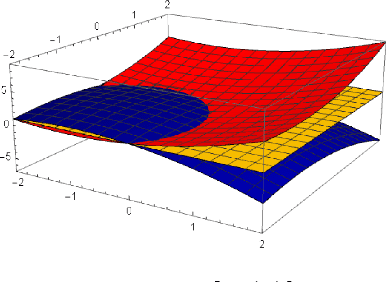
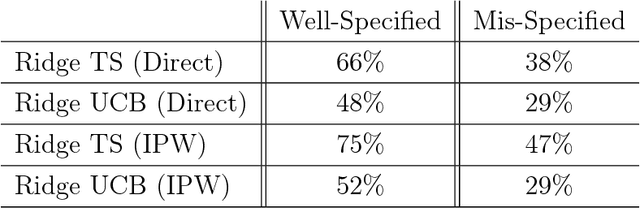
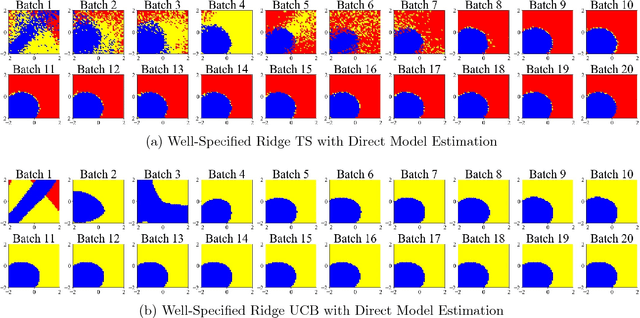
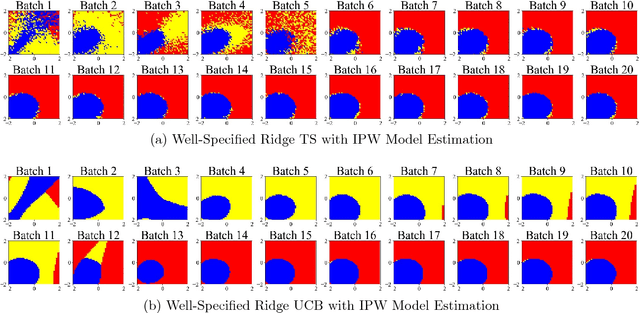
Although many contextual bandit algorithms have similar theoretical guarantees, the characteristics of real-world applications oftentimes result in large performance dissimilarities across algorithms. We study a consideration for the exploration vs. exploitation framework that does not arise in non-contextual bandits: the way exploration is conducted in the present may affect the bias and variance in the potential outcome model estimation in subsequent stages of learning. We show that contextual bandit algorithms are sensitive to the estimation method of the outcome model as well as the exploration method used, particularly in the presence of rich heterogeneity or complex outcome models, which can lead to difficult estimation problems along the path of learning. We propose new contextual bandit designs, combining parametric and non-parametric statistical estimation methods with causal inference methods in order to reduce the estimation bias that results from adaptive treatment assignment. We provide empirical evidence that guides the choice among the alternatives in different scenarios, such as prejudice (non-representative user contexts) in the initial training data.