 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly robust off-policy evaluation with shrinkage
Paper and Code
Jul 22, 2019

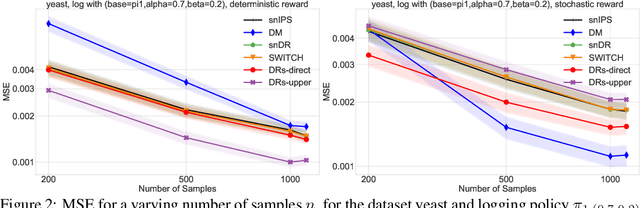
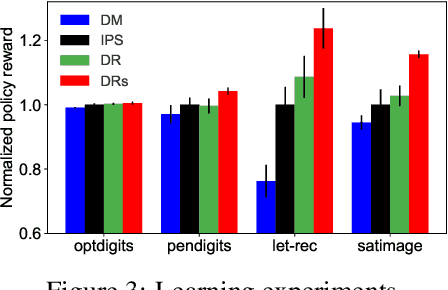
We design a new family of estimators for off-policy evaluation in contextual bandits. Our estimators are based on the asymptotically optimal approach of doubly robust estimation, but they shrink importance weights to obtain a better bias-variance tradeoff in finite samples. Our approach adapts importance weights to the quality of a reward predictor, interpolating between doubly robust estimation and direct modeling. When the reward predictor is poor, we recover previously studied weight clipping, but when the reward predictor is good, we obtain a new form of shrinkage. To navigate between these regimes and tune the shrinkage coefficient, we design a model selection procedure, which we prove is never worse than the doubly robust estimator. Extensive experiments on bandit benchmark problems show that our estimators are highly adaptive and typically outperform state-of-the-art methods.