 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
Sep 09, 2025Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.
A Systems Theoretic Approach to Online Machine Learning
Apr 04, 2024The machine learning formulation of online learning is incomplete from a systems theoretic perspective. Typically, machine learning research emphasizes domains and tasks, and a problem solving worldview. It focuses on algorithm parameters, features, and samples, and neglects the perspective offered by considering system structure and system behavior or dynamics. Online learning is an active field of research and has been widely explored in terms of statistical theory and computational algorithms, however, in general, the literature still lacks formal system theoretical frameworks for modeling online learning systems and resolving systems-related concept drift issues. Furthermore, while the machine learning formulation serves to classify methods and literature, the systems theoretic formulation presented herein serves to provide a framework for the top-down design of online learning systems, including a novel definition of online learning and the identification of key design parameters. The framework is formulated in terms of input-output systems and is further divided into system structure and system behavior. Concept drift is a critical challenge faced in online learning, and this work formally approaches it as part of the system behavior characteristics. Healthcare provider fraud detection using machine learning is used as a case study throughout the paper to ground the discussion in a real-world online learning challenge.
On Extending the Automatic Test Markup Language (ATML) for Machine Learning
Apr 04, 2024This paper addresses the urgent need for messaging standards in the operational test and evaluation (T&E) of machine learning (ML) applications, particularly in edge ML applications embedded in systems like robots, satellites, and unmanned vehicles. It examines the suitability of the IEEE Standard 1671 (IEEE Std 1671), known as the Automatic Test Markup Language (ATML), an XML-based standard originally developed for electronic systems, for ML application testing. The paper explores extending IEEE Std 1671 to encompass the unique challenges of ML applications, including the use of datasets and dependencies on software. Through modeling various tests such as adversarial robustness and drift detection, this paper offers a framework adaptable to specific applications, suggesting that minor modifications to ATML might suffice to address the novelties of ML. This paper differentiates ATML's focus on testing from other ML standards like Predictive Model Markup Language (PMML) or Open Neural Network Exchange (ONNX), which concentrate on ML model specification. We conclude that ATML is a promising tool for effective, near real-time operational T&E of ML applications, an essential aspect of AI lifecycle management, safety, and governance.
Inverse Reinforcement Learning for Strategy Identification
Jul 31, 2021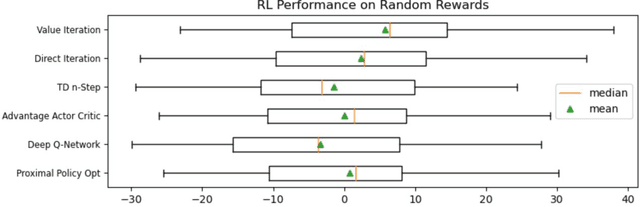
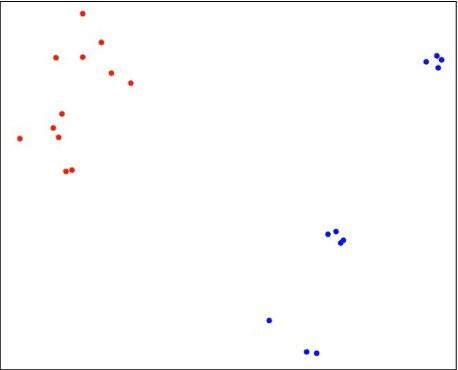
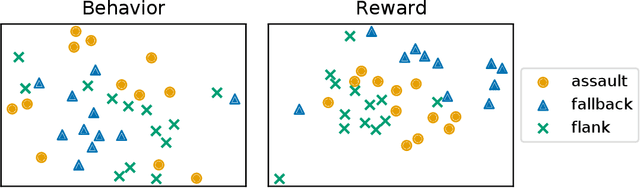

In adversarial environments, one side could gain an advantage by identifying the opponent's strategy. For example, in combat games, if an opponents strategy is identified as overly aggressive, one could lay a trap that exploits the opponent's aggressive nature. However, an opponent's strategy is not always apparent and may need to be estimated from observations of their actions. This paper proposes to use inverse reinforcement learning (IRL) to identify strategies in adversarial environments. Specifically, the contributions of this work are 1) the demonstration of this concept on gaming combat data generated from three pre-defined strategies and 2) the framework for using IRL to achieve strategy identification. The numerical experiments demonstrate that the recovered rewards can be identified using a variety of techniques. In this paper, the recovered reward are visually displayed, clustered using unsupervised learning, and classified using a supervised learner.
A Systems Theory of Transfer Learning
Jul 02, 2021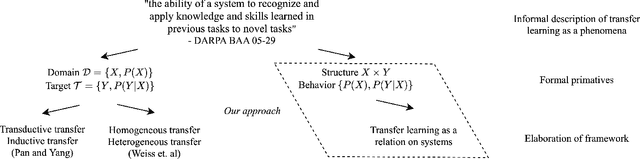
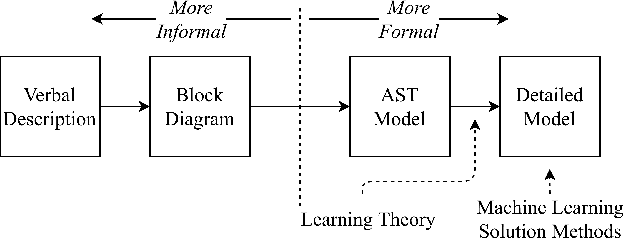
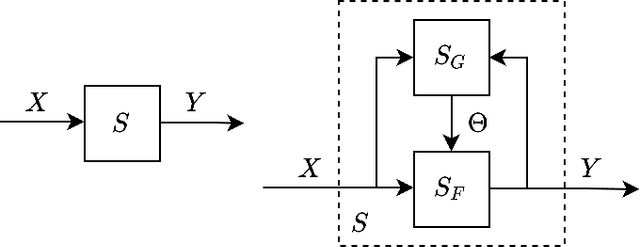
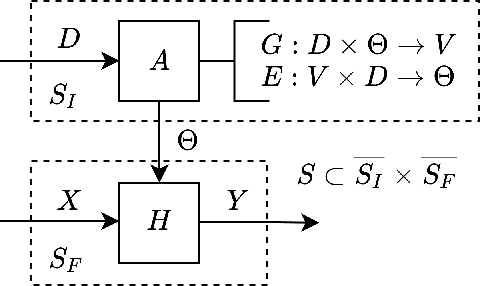
Existing frameworks for transfer learning are incomplete from a systems theoretic perspective. They place emphasis on notions of domain and task, and neglect notions of structure and behavior. In doing so, they limit the extent to which formalism can be carried through into the elaboration of their frameworks. Herein, we use Mesarovician systems theory to define transfer learning as a relation on sets and subsequently characterize the general nature of transfer learning as a mathematical construct. We interpret existing frameworks in terms of ours and go beyond existing frameworks to define notions of transferability, transfer roughness, and transfer distance. Importantly, despite its formalism, our framework avoids the detailed mathematics of learning theory or machine learning solution methods without excluding their consideration. As such, we provide a formal, general systems framework for modeling transfer learning that offers a rigorous foundation for system design and analysis.
Empirically Measuring Transfer Distance for System Design and Operation
Jul 02, 2021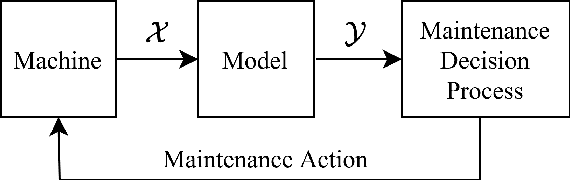
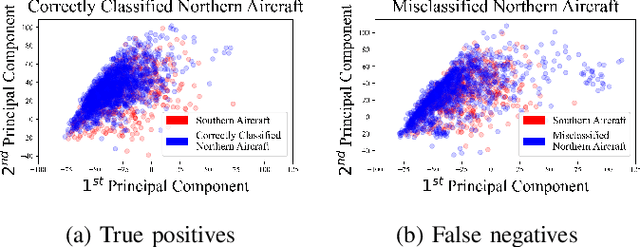
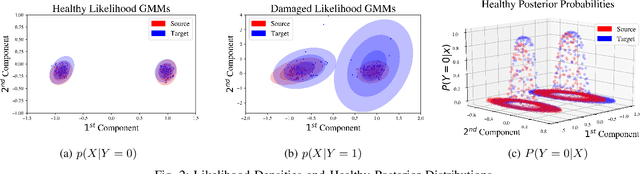
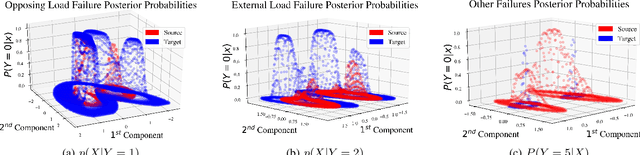
Classical machine learning approaches are sensitive to non-stationarity. Transfer learning can address non-stationarity by sharing knowledge from one system to another, however, in areas like machine prognostics and defense, data is fundamentally limited. Therefore, transfer learning algorithms have little, if any, examples from which to learn. Herein, we suggest that these constraints on algorithmic learning can be addressed by systems engineering. We formally define transfer distance in general terms and demonstrate its use in empirically quantifying the transferability of models. We consider the use of transfer distance in the design of machine rebuild procedures to allow for transferable prognostic models. We also consider the use of transfer distance in predicting operational performance in computer vision. Practitioners can use the presented methodology to design and operate systems with consideration for the learning theoretic challenges faced by component learning systems.
Value-Decomposition Multi-Agent Actor-Critics
Aug 01, 2020
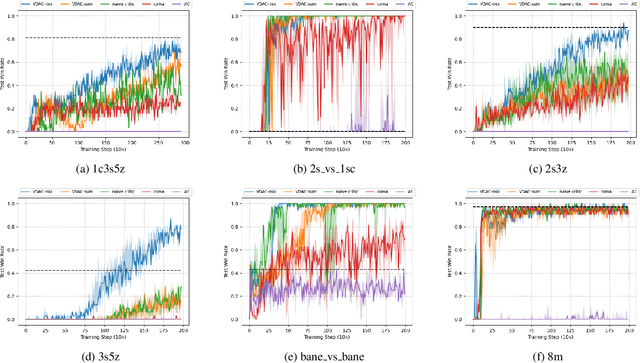

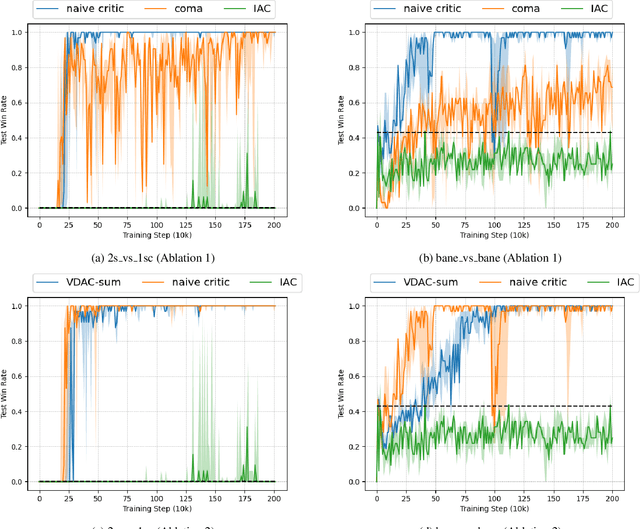
The exploitation of extra state information has been an active research area in multi-agent reinforcement learning (MARL). QMIX represents the joint action-value using a non-negative function approximator and achieves the best performance, by far, on multi-agent benchmarks, StarCraft II micromanagement tasks. However, our experiments show that, in some cases, QMIX is incompatible with A2C, a training paradigm that promotes algorithm training efficiency. To obtain a reasonable trade-off between training efficiency and algorithm performance, we extend value-decomposition to actor-critics that are compatible with A2C and propose a novel actor-critic framework, value-decomposition actor-critics (VDACs). We evaluate VDACs on the testbed of StarCraft II micromanagement tasks and demonstrate that the proposed framework improves median performance over other actor-critic methods. Furthermore, we use a set of ablation experiments to identify the key factors that contribute to the performance of VDACs.
Counterfactual Multi-Agent Reinforcement Learning with Graph Convolution Communication
Apr 01, 2020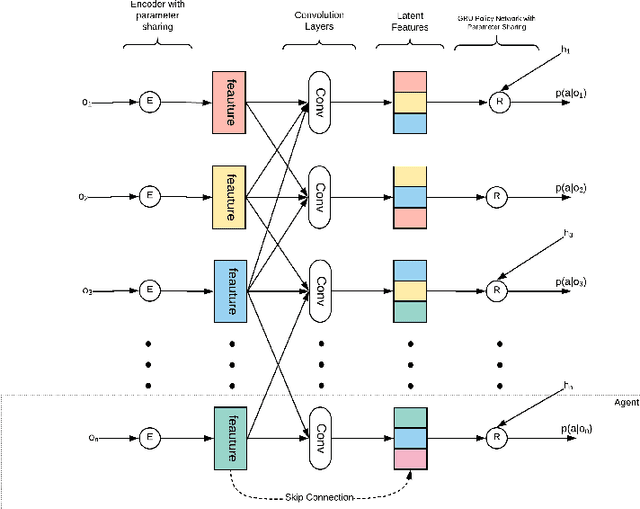

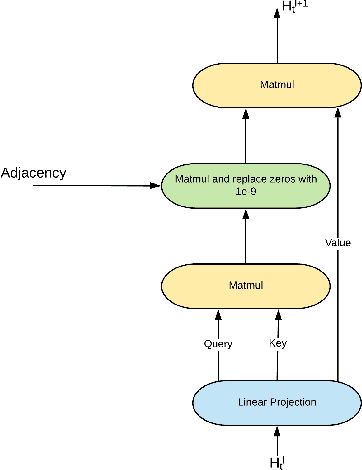
We consider a fully cooperative multi-agent system where agents cooperate to maximize a system's utility in a partial-observable environment. We propose that multi-agent systems must have the ability to (1) communicate and understand the inter-plays between agents and (2) correctly distribute rewards based on an individual agent's contribution. In contrast, most work in this setting considers only one of the above abilities. In this study, we develop an architecture that allows for communication among agents and tailors the system's reward for each individual agent. Our architecture represents agent communication through graph convolution and applies an existing credit assignment structure, counterfactual multi-agent policy gradient (COMA), to assist agents to learn communication by back-propagation. The flexibility of the graph structure enables our method to be applicable to a variety of multi-agent systems, e.g. dynamic systems that consist of varying numbers of agents and static systems with a fixed number of agents. We evaluate our method on a range of tasks, demonstrating the advantage of marrying communication with credit assignment. In the experiments, our proposed method yields better performance than the state-of-art methods, including COMA. Moreover, we show that the communication strategies offers us insights and interpretability of the system's cooperative policies.
Graph Convolution Networks for Probabilistic Modeling of Driving Acceleration
Nov 22, 2019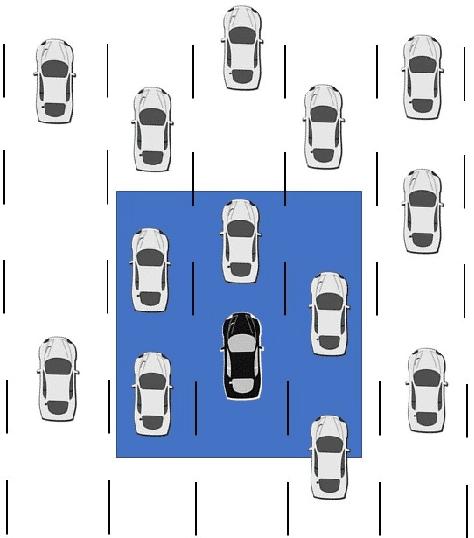
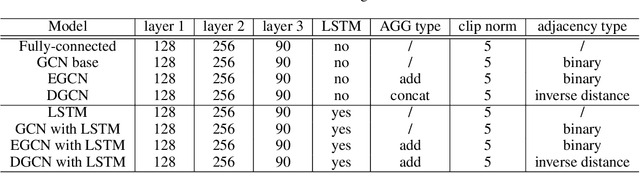
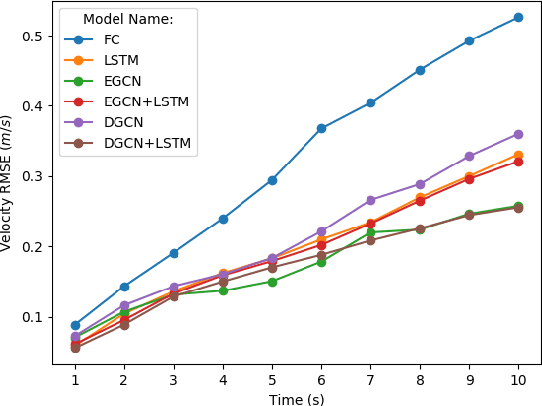
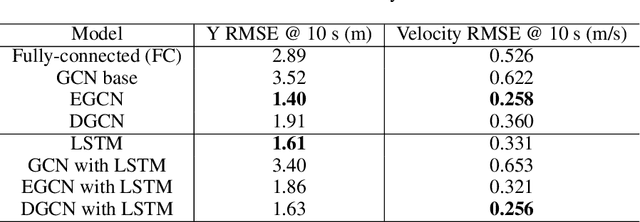
The ability to model and predict ego-vehicle's surrounding traffic is crucial for autonomous pilots and intelligent driver-assistance systems. Acceleration prediction is important as one of the major components of traffic prediction. This paper proposes novel approaches to the acceleration prediction problem. By representing spatial relationships between vehicles with a graph model, we build a generalized acceleration prediction framework. This paper studies the effectiveness of proposed Graph Convolution Networks, which operate on graphs predicting the acceleration distribution for vehicles driving on highways. We further investigate prediction improvement through integrating of Recurrent Neural Networks to disentangle the temporal complexity inherent in the traffic data. Results from simulation studies using comprehensive performance metrics support the conclusion that our proposed networks outperform state-of-the-art methods in generating realistic trajectories over a prediction horizon.
Multi-agent Inverse Reinforcement Learning for General-sum Stochastic Games
Jun 26, 2018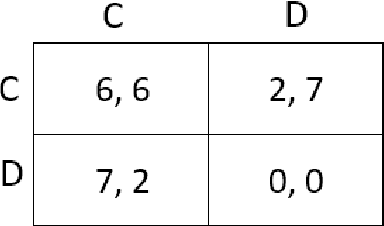
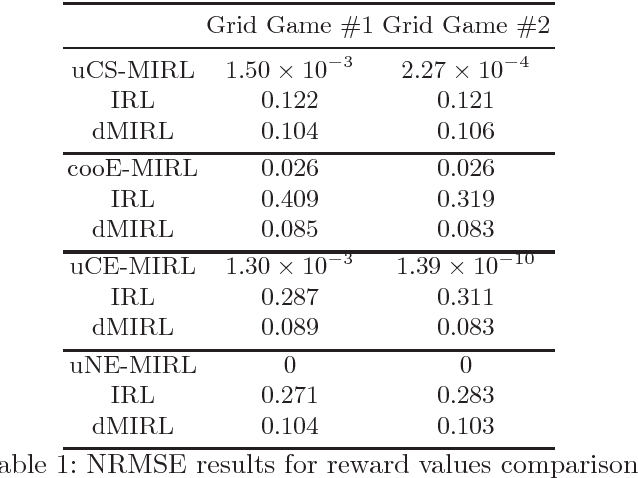

This paper addresses the problem of multi-agent inverse reinforcement learning (MIRL) in a two-player general-sum stochastic game framework. Five variants of MIRL are considered: uCS-MIRL, advE-MIRL, cooE-MIRL, uCE-MIRL, and uNE-MIRL, each distinguished by its solution concept. Problem uCS-MIRL is a cooperative game in which the agents employ cooperative strategies that aim to maximize the total game value. In problem uCE-MIRL, agents are assumed to follow strategies that constitute a correlated equilibrium while maximizing total game value. Problem uNE-MIRL is similar to uCE-MIRL in total game value maximization, but it is assumed that the agents are playing a Nash equilibrium. Problems advE-MIRL and cooE-MIRL assume agents are playing an adversarial equilibrium and a coordination equilibrium, respectively. We propose novel approaches to address these five problems under the assumption that the game observer either knows or is able to accurate estimate the policies and solution concepts for players. For uCS-MIRL, we first develop a characteristic set of solutions ensuring that the observed bi-policy is a uCS and then apply a Bayesian inverse learning method. For uCE-MIRL, we develop a linear programming problem subject to constraints that define necessary and sufficient conditions for the observed policies to be correlated equilibria. The objective is to choose a solution that not only minimizes the total game value difference between the observed bi-policy and a local uCS, but also maximizes the scale of the solution. We apply a similar treatment to the problem of uNE-MIRL. The remaining two problems can be solved efficiently by taking advantage of solution uniqueness and setting up a convex optimization problem. Results are validated on various benchmark grid-world games.