 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning for Strategy Identification
Jul 31, 2021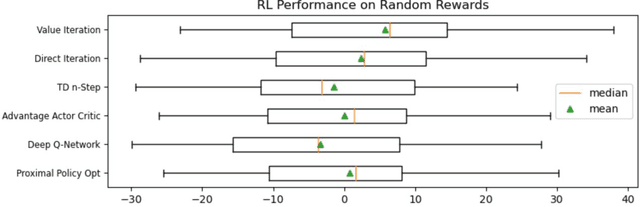
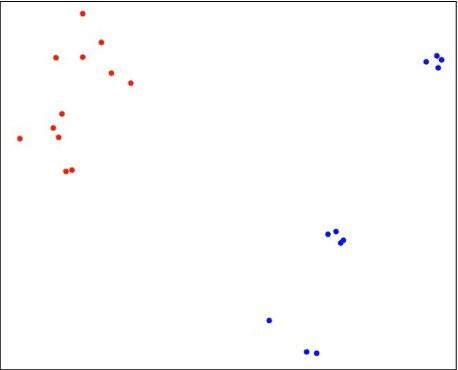
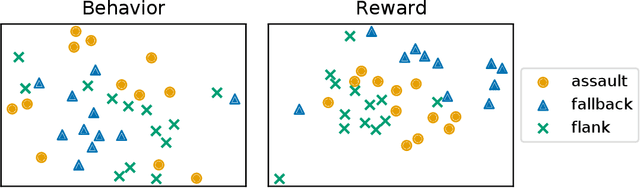

In adversarial environments, one side could gain an advantage by identifying the opponent's strategy. For example, in combat games, if an opponents strategy is identified as overly aggressive, one could lay a trap that exploits the opponent's aggressive nature. However, an opponent's strategy is not always apparent and may need to be estimated from observations of their actions. This paper proposes to use inverse reinforcement learning (IRL) to identify strategies in adversarial environments. Specifically, the contributions of this work are 1) the demonstration of this concept on gaming combat data generated from three pre-defined strategies and 2) the framework for using IRL to achieve strategy identification. The numerical experiments demonstrate that the recovered rewards can be identified using a variety of techniques. In this paper, the recovered reward are visually displayed, clustered using unsupervised learning, and classified using a supervised learner.
Empirically Measuring Transfer Distance for System Design and Operation
Jul 02, 2021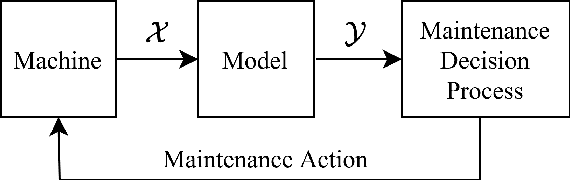
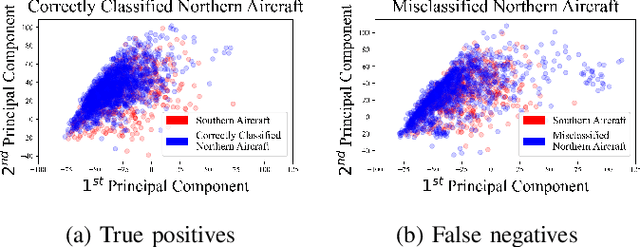
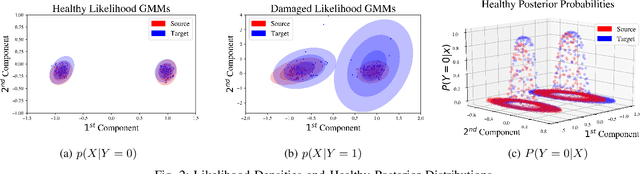
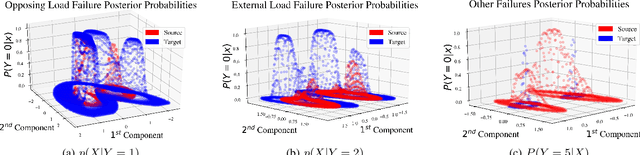
Classical machine learning approaches are sensitive to non-stationarity. Transfer learning can address non-stationarity by sharing knowledge from one system to another, however, in areas like machine prognostics and defense, data is fundamentally limited. Therefore, transfer learning algorithms have little, if any, examples from which to learn. Herein, we suggest that these constraints on algorithmic learning can be addressed by systems engineering. We formally define transfer distance in general terms and demonstrate its use in empirically quantifying the transferability of models. We consider the use of transfer distance in the design of machine rebuild procedures to allow for transferable prognostic models. We also consider the use of transfer distance in predicting operational performance in computer vision. Practitioners can use the presented methodology to design and operate systems with consideration for the learning theoretic challenges faced by component learning systems.
Value-Decomposition Multi-Agent Actor-Critics
Aug 01, 2020
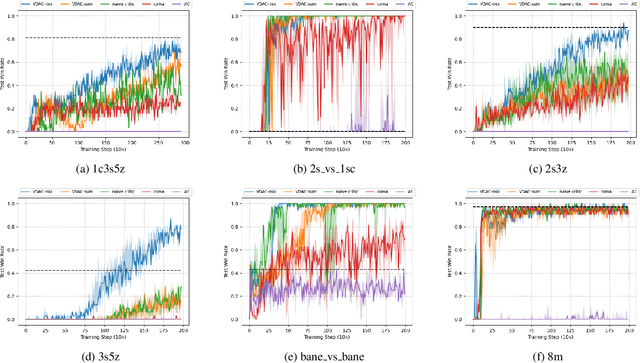

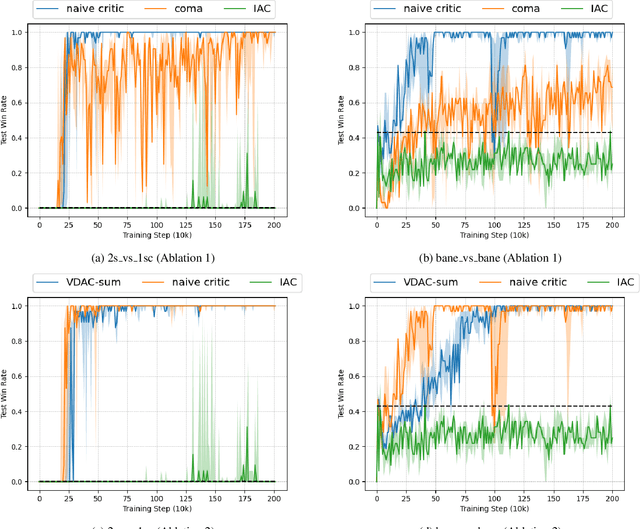
The exploitation of extra state information has been an active research area in multi-agent reinforcement learning (MARL). QMIX represents the joint action-value using a non-negative function approximator and achieves the best performance, by far, on multi-agent benchmarks, StarCraft II micromanagement tasks. However, our experiments show that, in some cases, QMIX is incompatible with A2C, a training paradigm that promotes algorithm training efficiency. To obtain a reasonable trade-off between training efficiency and algorithm performance, we extend value-decomposition to actor-critics that are compatible with A2C and propose a novel actor-critic framework, value-decomposition actor-critics (VDACs). We evaluate VDACs on the testbed of StarCraft II micromanagement tasks and demonstrate that the proposed framework improves median performance over other actor-critic methods. Furthermore, we use a set of ablation experiments to identify the key factors that contribute to the performance of VDACs.
Counterfactual Multi-Agent Reinforcement Learning with Graph Convolution Communication
Apr 01, 2020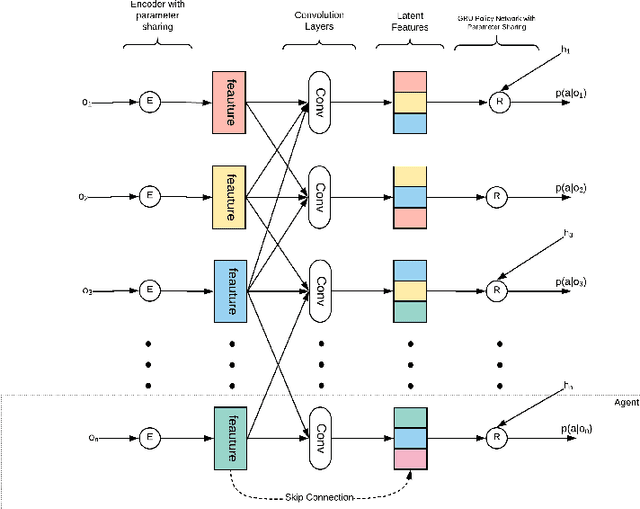

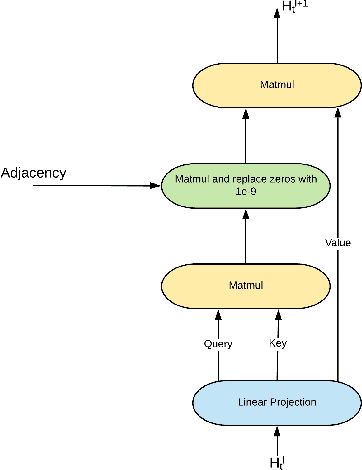
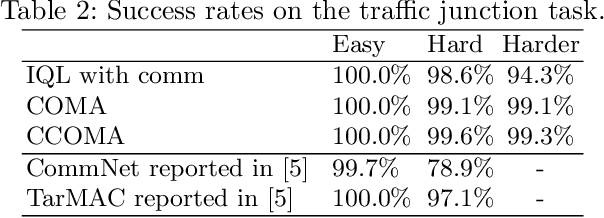
We consider a fully cooperative multi-agent system where agents cooperate to maximize a system's utility in a partial-observable environment. We propose that multi-agent systems must have the ability to (1) communicate and understand the inter-plays between agents and (2) correctly distribute rewards based on an individual agent's contribution. In contrast, most work in this setting considers only one of the above abilities. In this study, we develop an architecture that allows for communication among agents and tailors the system's reward for each individual agent. Our architecture represents agent communication through graph convolution and applies an existing credit assignment structure, counterfactual multi-agent policy gradient (COMA), to assist agents to learn communication by back-propagation. The flexibility of the graph structure enables our method to be applicable to a variety of multi-agent systems, e.g. dynamic systems that consist of varying numbers of agents and static systems with a fixed number of agents. We evaluate our method on a range of tasks, demonstrating the advantage of marrying communication with credit assignment. In the experiments, our proposed method yields better performance than the state-of-art methods, including COMA. Moreover, we show that the communication strategies offers us insights and interpretability of the system's cooperative policies.