 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Decomposition Multi-Agent Actor-Critics
Aug 01, 2020
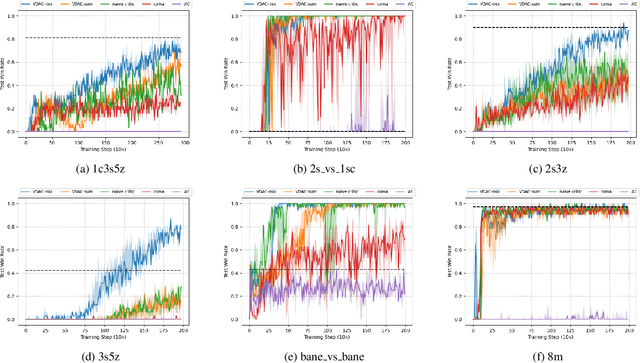

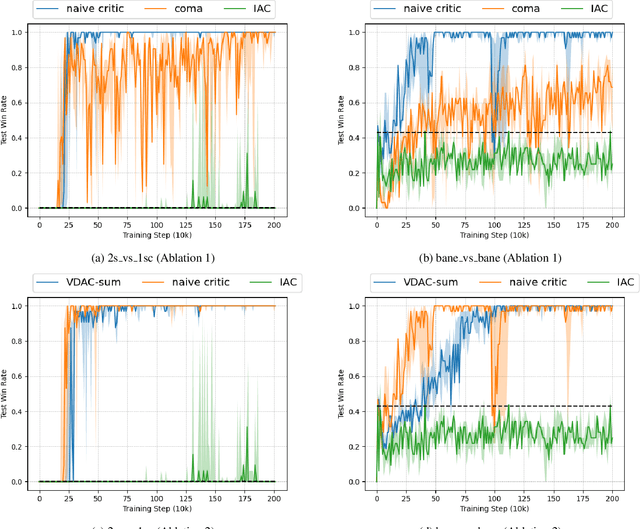
The exploitation of extra state information has been an active research area in multi-agent reinforcement learning (MARL). QMIX represents the joint action-value using a non-negative function approximator and achieves the best performance, by far, on multi-agent benchmarks, StarCraft II micromanagement tasks. However, our experiments show that, in some cases, QMIX is incompatible with A2C, a training paradigm that promotes algorithm training efficiency. To obtain a reasonable trade-off between training efficiency and algorithm performance, we extend value-decomposition to actor-critics that are compatible with A2C and propose a novel actor-critic framework, value-decomposition actor-critics (VDACs). We evaluate VDACs on the testbed of StarCraft II micromanagement tasks and demonstrate that the proposed framework improves median performance over other actor-critic methods. Furthermore, we use a set of ablation experiments to identify the key factors that contribute to the performance of VDACs.
Counterfactual Multi-Agent Reinforcement Learning with Graph Convolution Communication
Apr 01, 2020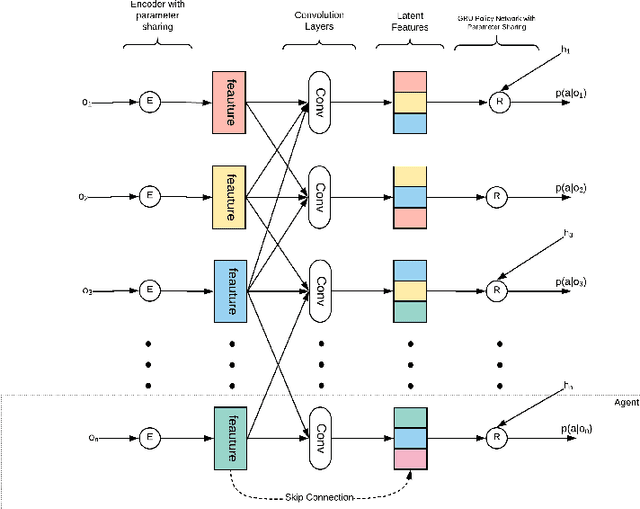

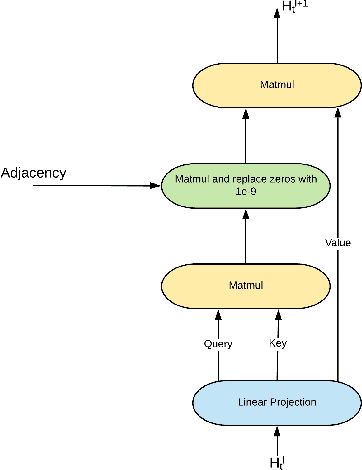
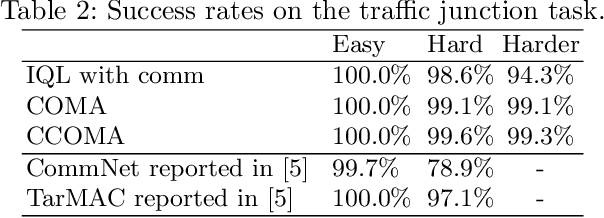
We consider a fully cooperative multi-agent system where agents cooperate to maximize a system's utility in a partial-observable environment. We propose that multi-agent systems must have the ability to (1) communicate and understand the inter-plays between agents and (2) correctly distribute rewards based on an individual agent's contribution. In contrast, most work in this setting considers only one of the above abilities. In this study, we develop an architecture that allows for communication among agents and tailors the system's reward for each individual agent. Our architecture represents agent communication through graph convolution and applies an existing credit assignment structure, counterfactual multi-agent policy gradient (COMA), to assist agents to learn communication by back-propagation. The flexibility of the graph structure enables our method to be applicable to a variety of multi-agent systems, e.g. dynamic systems that consist of varying numbers of agents and static systems with a fixed number of agents. We evaluate our method on a range of tasks, demonstrating the advantage of marrying communication with credit assignment. In the experiments, our proposed method yields better performance than the state-of-art methods, including COMA. Moreover, we show that the communication strategies offers us insights and interpretability of the system's cooperative policies.
Graph Convolution Networks for Probabilistic Modeling of Driving Acceleration
Nov 22, 2019
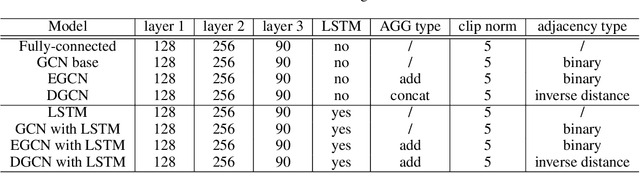
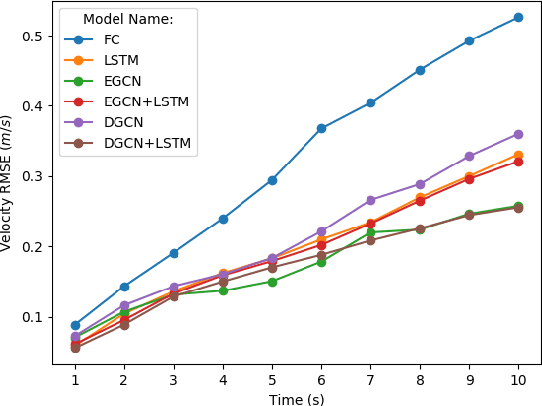
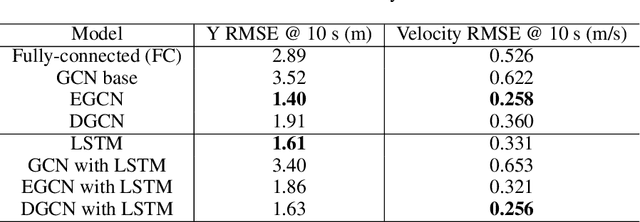
The ability to model and predict ego-vehicle's surrounding traffic is crucial for autonomous pilots and intelligent driver-assistance systems. Acceleration prediction is important as one of the major components of traffic prediction. This paper proposes novel approaches to the acceleration prediction problem. By representing spatial relationships between vehicles with a graph model, we build a generalized acceleration prediction framework. This paper studies the effectiveness of proposed Graph Convolution Networks, which operate on graphs predicting the acceleration distribution for vehicles driving on highways. We further investigate prediction improvement through integrating of Recurrent Neural Networks to disentangle the temporal complexity inherent in the traffic data. Results from simulation studies using comprehensive performance metrics support the conclusion that our proposed networks outperform state-of-the-art methods in generating realistic trajectories over a prediction horizon.