 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Inverse Reinforcement Learning for Zero-sum Games
Apr 10, 2014
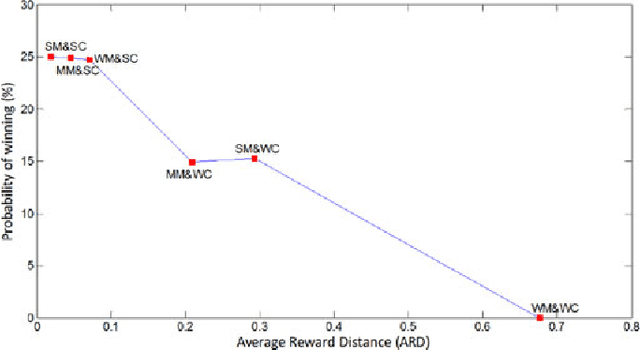
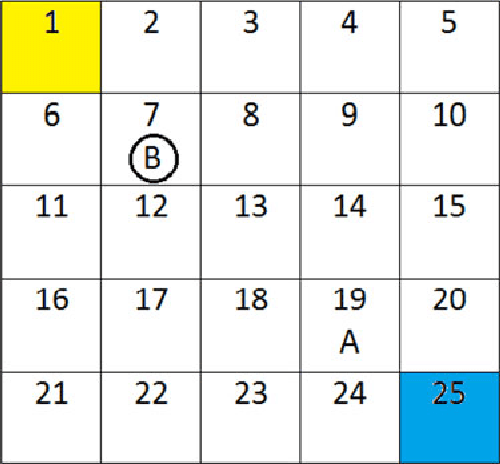

In this paper we introduce a Bayesian framework for solving a class of problems termed Multi-agent Inverse Reinforcement Learning (MIRL). Compared to the well-known Inverse Reinforcement Learning (IRL) problem, MIRL is formalized in the context of a stochastic game rather than a Markov decision process (MDP). Games bring two primary challenges: First, the concept of optimality, central to MDPs, loses its meaning and must be replaced with a more general solution concept, such as the Nash equilibrium. Second, the non-uniqueness of equilibria means that in MIRL, in addition to multiple reasonable solutions for a given inversion model, there may be multiple inversion models that are all equally sensible approaches to solving the problem. We establish a theoretical foundation for competitive two-agent MIRL problems and propose a Bayesian optimization algorithm to solve the problem. We focus on the case of two-person zero-sum stochastic games, developing a generative model for the likelihood of unknown rewards of agents given observed game play assuming that the two agents follow a minimax bipolicy. As a numerical illustration, we apply our method in the context of an abstract soccer game. For the soccer game, we investigate relationships between the extent of prior information and the quality of learned rewards. Results suggest that covariance structure is more important than mean value in reward priors.
Comparison of Multi-agent and Single-agent Inverse Learning on a Simulated Soccer Example
Mar 26, 2014



We compare the performance of Inverse Reinforcement Learning (IRL) with the relative new model of Multi-agent Inverse Reinforcement Learning (MIRL). Before comparing the methods, we extend a published Bayesian IRL approach that is only applicable to the case where the reward is only state dependent to a general one capable of tackling the case where the reward depends on both state and action. Comparison between IRL and MIRL is made in the context of an abstract soccer game, using both a game model in which the reward depends only on state and one in which it depends on both state and action. Results suggest that the IRL approach performs much worse than the MIRL approach. We speculate that the underperformance of IRL is because it fails to capture equilibrium information in the manner possible in MIRL.