 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range Multimodal Pretraining for Movie Understanding
Aug 18, 2023Learning computer vision models from (and for) movies has a long-standing history. While great progress has been attained, there is still a need for a pretrained multimodal model that can perform well in the ever-growing set of movie understanding tasks the community has been establishing. In this work, we introduce Long-range Multimodal Pretraining, a strategy, and a model that leverages movie data to train transferable multimodal and cross-modal encoders. Our key idea is to learn from all modalities in a movie by observing and extracting relationships over a long-range. After pretraining, we run ablation studies on the LVU benchmark and validate our modeling choices and the importance of learning from long-range time spans. Our model achieves state-of-the-art on several LVU tasks while being much more data efficient than previous works. Finally, we evaluate our model's transferability by setting a new state-of-the-art in five different benchmarks.
The Anatomy of Video Editing: A Dataset and Benchmark Suite for AI-Assisted Video Editing
Jul 21, 2022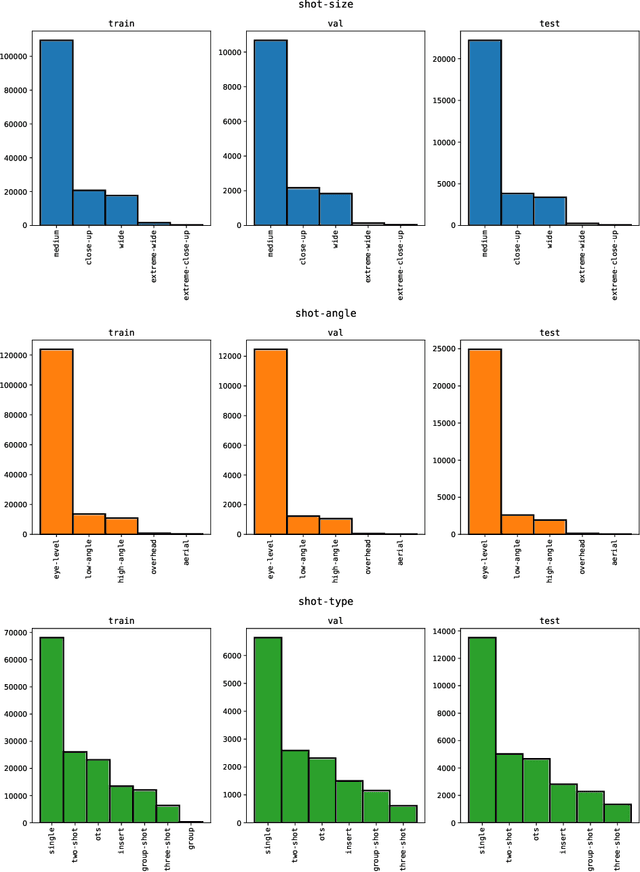
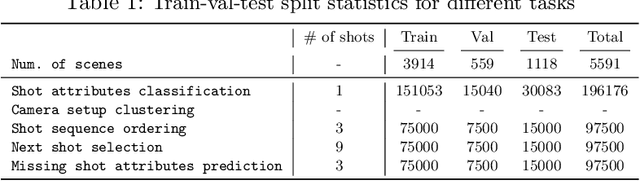
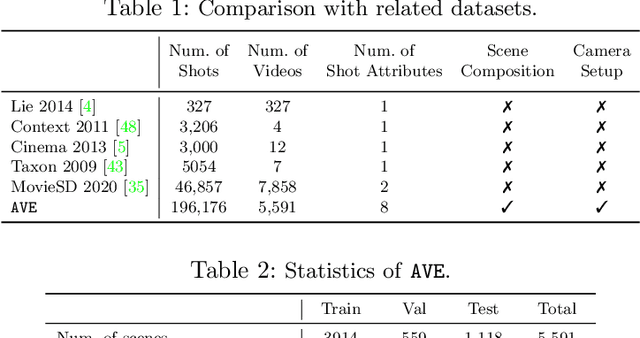
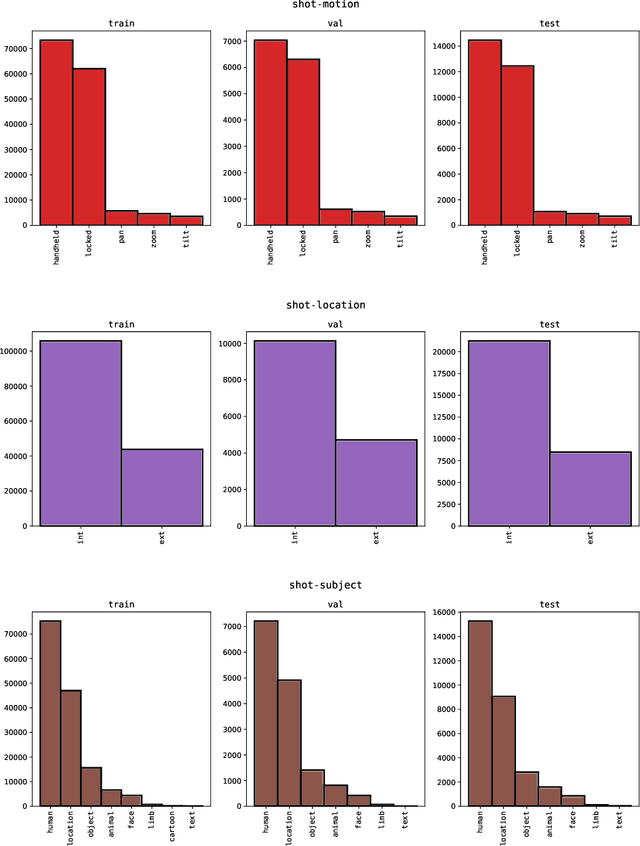
Machine learning is transforming the video editing industry. Recent advances in computer vision have leveled-up video editing tasks such as intelligent reframing, rotoscoping, color grading, or applying digital makeups. However, most of the solutions have focused on video manipulation and VFX. This work introduces the Anatomy of Video Editing, a dataset, and benchmark, to foster research in AI-assisted video editing. Our benchmark suite focuses on video editing tasks, beyond visual effects, such as automatic footage organization and assisted video assembling. To enable research on these fronts, we annotate more than 1.5M tags, with relevant concepts to cinematography, from 196176 shots sampled from movie scenes. We establish competitive baseline methods and detailed analyses for each of the tasks. We hope our work sparks innovative research towards underexplored areas of AI-assisted video editing.
Video-ReTime: Learning Temporally Varying Speediness for Time Remapping
May 11, 2022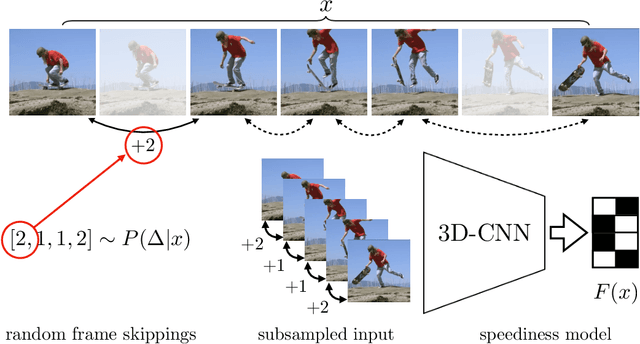
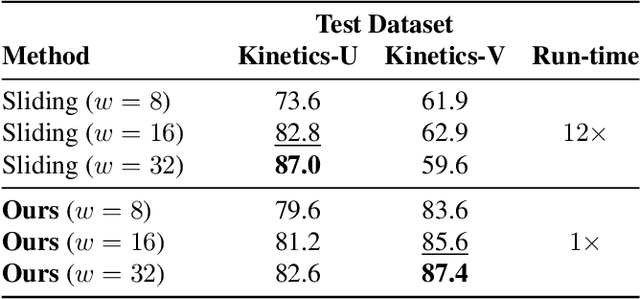

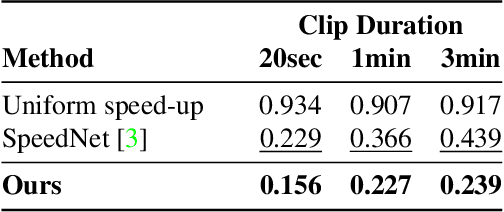
We propose a method for generating a temporally remapped video that matches the desired target duration while maximally preserving natural video dynamics. Our approach trains a neural network through self-supervision to recognize and accurately localize temporally varying changes in the video playback speed. To re-time videos, we 1. use the model to infer the slowness of individual video frames, and 2. optimize the temporal frame sub-sampling to be consistent with the model's slowness predictions. We demonstrate that this model can detect playback speed variations more accurately while also being orders of magnitude more efficient than prior approaches. Furthermore, we propose an optimization for video re-timing that enables precise control over the target duration and performs more robustly on longer videos than prior methods. We evaluate the model quantitatively on artificially speed-up videos, through transfer to action recognition, and qualitatively through user studies.