 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel and Proximal Linear-Quadratic Methods for Real-Time Constrained Model-Predictive Control
May 15, 2024


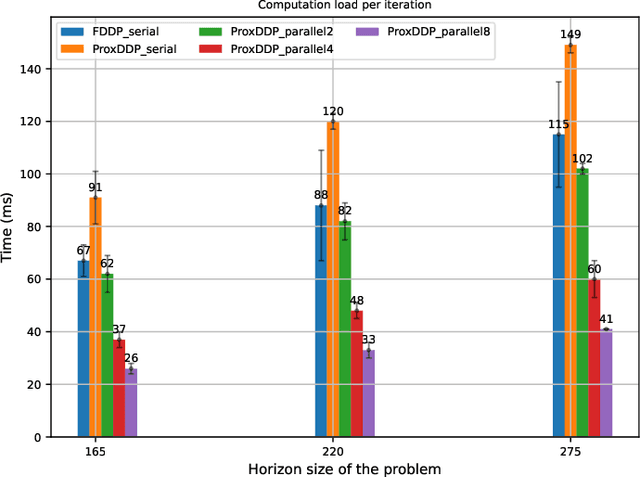
-Recent strides in model predictive control (MPC)underscore a dependence on numerical advancements to efficientlyand accurately solve large-scale problems. Given the substantialnumber of variables characterizing typical whole-body optimalcontrol (OC) problems -often numbering in the thousands-exploiting the sparse structure of the numerical problem becomescrucial to meet computational demands, typically in the range ofa few milliseconds. A fundamental building block for computingNewton or Sequential Quadratic Programming (SQP) steps indirect optimal control methods involves addressing the linearquadratic regulator (LQR) problem. This paper concentrateson equality-constrained problems featuring implicit systemdynamics and dual regularization, a characteristic found inadvanced interior-point or augmented Lagrangian solvers. Here,we introduce a parallel algorithm designed for solving an LQRproblem with dual regularization. Leveraging a rewriting of theLQR recursion through block elimination, we first enhanced theefficiency of the serial algorithm, then subsequently generalized itto handle parametric problems. This extension enables us to splitdecision variables and solve multiple subproblems concurrently.Our algorithm is implemented in our nonlinear numerical optimalcontrol library ALIGATOR. It showcases improved performanceover previous serial formulations and we validate its efficacy bydeploying it in the model predictive control of a real quadrupedrobot. This paper follows up from our prior work on augmentedLagrangian methods for numerical optimal control with implicitdynamics and constraints.
Robust Visual Sim-to-Real Transfer for Robotic Manipulation
Jul 28, 2023

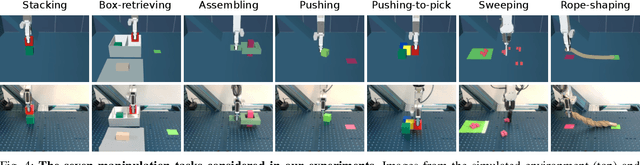

Learning visuomotor policies in simulation is much safer and cheaper than in the real world. However, due to discrepancies between the simulated and real data, simulator-trained policies often fail when transferred to real robots. One common approach to bridge the visual sim-to-real domain gap is domain randomization (DR). While previous work mainly evaluates DR for disembodied tasks, such as pose estimation and object detection, here we systematically explore visual domain randomization methods and benchmark them on a rich set of challenging robotic manipulation tasks. In particular, we propose an off-line proxy task of cube localization to select DR parameters for texture randomization, lighting randomization, variations of object colors and camera parameters. Notably, we demonstrate that DR parameters have similar impact on our off-line proxy task and on-line policies. We, hence, use off-line optimized DR parameters to train visuomotor policies in simulation and directly apply such policies to a real robot. Our approach achieves 93% success rate on average when tested on a diverse set of challenging manipulation tasks. Moreover, we evaluate the robustness of policies to visual variations in real scenes and show that our simulator-trained policies outperform policies learned using real but limited data. Code, simulation environment, real robot datasets and trained models are available at https://www.di.ens.fr/willow/research/robust_s2r/.
Risk-Sensitive Extended Kalman Filter
May 19, 2023



In robotics, designing robust algorithms in the face of estimation uncertainty is a challenging task. Indeed, controllers often do not consider the estimation uncertainty and only rely on the most likely estimated state. Consequently, sudden changes in the environment or the robot's dynamics can lead to catastrophic behaviors. In this work, we present a risk-sensitive Extended Kalman Filter that allows doing output-feedback Model Predictive Control (MPC) safely. This filter adapts its estimation to the control objective. By taking a pessimistic estimate concerning the value function resulting from the MPC controller, the filter provides increased robustness to the controller in phases of uncertainty as compared to a standard Extended Kalman Filter (EKF). Moreover, the filter has the same complexity as an EKF, so that it can be used for real-time model-predictive control. The paper evaluates the risk-sensitive behavior of the proposed filter when used in a nonlinear model-predictive control loop on a planar drone and industrial manipulator in simulation, as well as on an external force estimation task on a real quadruped robot. These experiments demonstrate the abilities of the approach to improve performance in the face of uncertainties significantly.
Assembly Planning from Observations under Physical Constraints
Apr 20, 2022
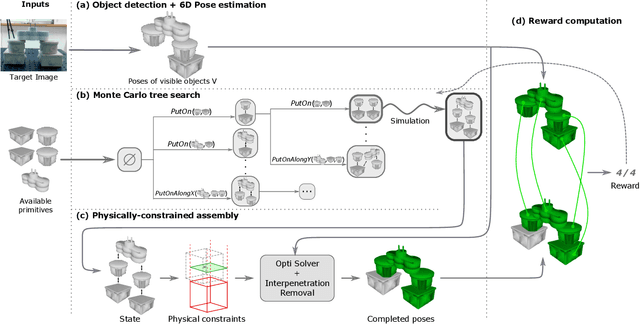


This paper addresses the problem of copying an unknown assembly of primitives with known shape and appearance using information extracted from a single photograph by an off-the-shelf procedure for object detection and pose estimation. The proposed algorithm uses a simple combination of physical stability constraints, convex optimization and Monte Carlo tree search to plan assemblies as sequences of pick-and-place operations represented by STRIPS operators. It is efficient and, most importantly, robust to the errors in object detection and pose estimation unavoidable in any real robotic system. The proposed approach is demonstrated with thorough experiments on a UR5 manipulator.