 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Structured Neural Networks to Control the Steering Dynamics of Autonomous Race Cars
Jul 27, 2025Autonomous racing has gained increasing attention in recent years, as a safe environment to accelerate the development of motion planning and control methods for autonomous driving. Deep learning models, predominantly based on neural networks (NNs), have demonstrated significant potential in modeling the vehicle dynamics and in performing various tasks in autonomous driving. However, their black-box nature is critical in the context of autonomous racing, where safety and robustness demand a thorough understanding of the decision-making algorithms. To address this challenge, this paper proposes MS-NN-steer, a new Model-Structured Neural Network for vehicle steering control, integrating the prior knowledge of the nonlinear vehicle dynamics into the neural architecture. The proposed controller is validated using real-world data from the Abu Dhabi Autonomous Racing League (A2RL) competition, with full-scale autonomous race cars. In comparison with general-purpose NNs, MS-NN-steer is shown to achieve better accuracy and generalization with small training datasets, while being less sensitive to the weights' initialization. Also, MS-NN-steer outperforms the steering controller used by the A2RL winning team. Our implementation is available open-source in a GitHub repository.
CACTO-SL: Using Sobolev Learning to improve Continuous Actor-Critic with Trajectory Optimization
Dec 17, 2023



Trajectory Optimization (TO) and Reinforcement Learning (RL) are powerful and complementary tools to solve optimal control problems. On the one hand, TO can efficiently compute locally-optimal solutions, but it tends to get stuck in local minima if the problem is not convex. On the other hand, RL is typically less sensitive to non-convexity, but it requires a much higher computational effort. Recently, we have proposed CACTO (Continuous Actor-Critic with Trajectory Optimization), an algorithm that uses TO to guide the exploration of an actor-critic RL algorithm. In turns, the policy encoded by the actor is used to warm-start TO, closing the loop between TO and RL. In this work, we present an extension of CACTO exploiting the idea of Sobolev learning. To make the training of the critic network faster and more data efficient, we enrich it with the gradient of the Value function, computed via a backward pass of the differential dynamic programming algorithm. Our results show that the new algorithm is more efficient than the original CACTO, reducing the number of TO episodes by a factor ranging from 3 to 10, and consequently the computation time. Moreover, we show that CACTO-SL helps TO to find better minima and to produce more consistent results.
Generating Reliable and Efficient Predictions of Human Motion: A Promising Encounter between Physics and Neural Networks
Jun 15, 2020
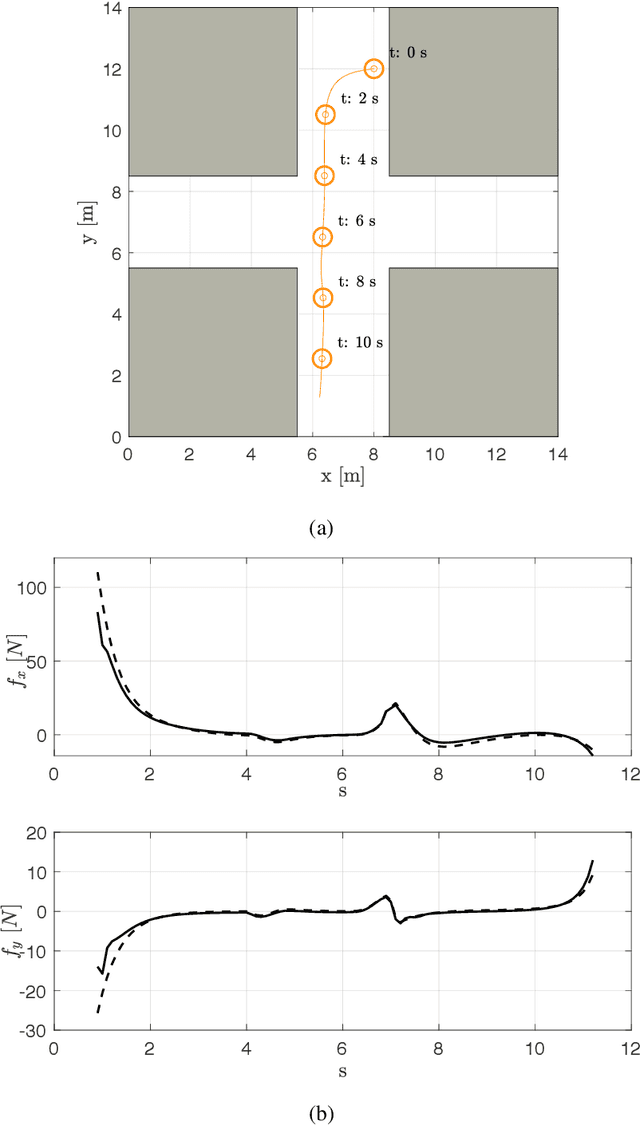
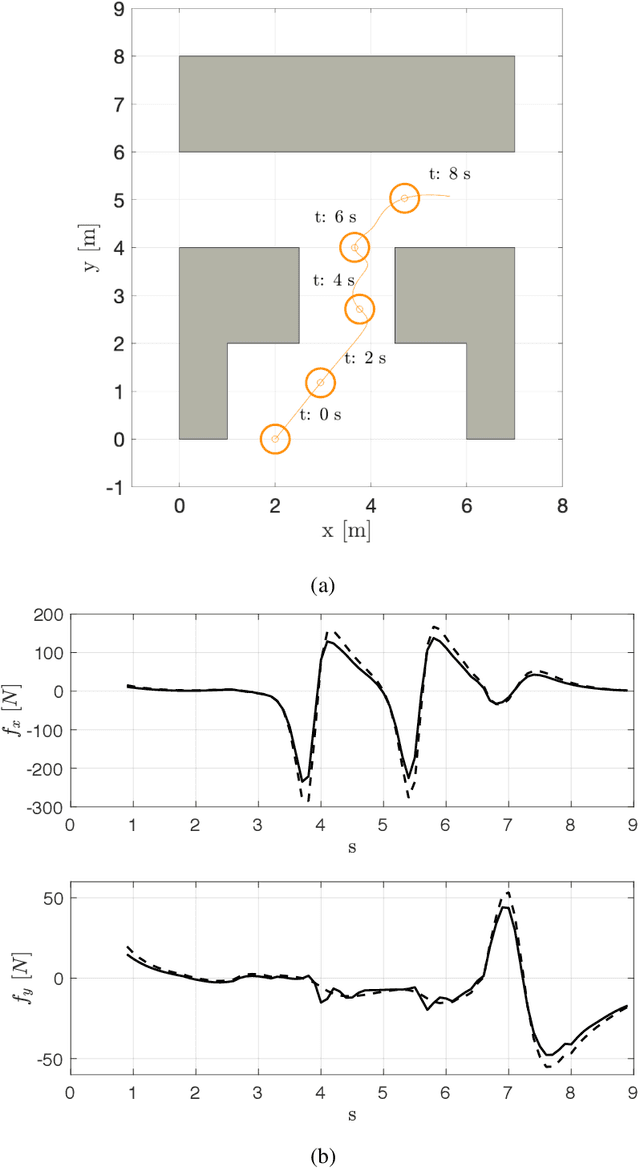
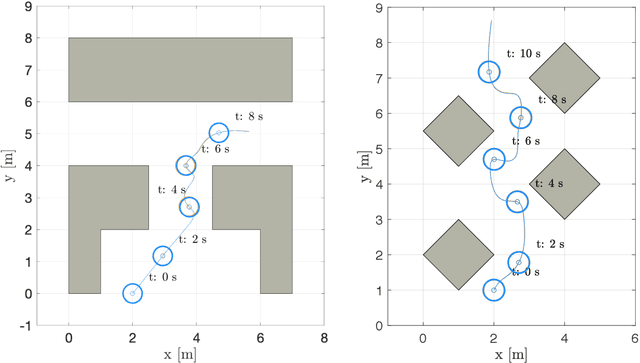
Generating accurate and efficient predictions for the motion of the humans present in the scene is key to the development of effective motion planning algorithms for robots moving in promiscuous areas, where wrong planning decisions could generate safety hazard or simply make the presence of the robot "socially" unacceptable. Our approach to predict human motion is based on a neural network of a peculiar kind. Contrary to conventional deep neural networks, our network embeds in its structure the popular Social Force Model, a dynamic equation describing the motion in physical terms. This choice allows us to concentrate the learning phase in the aspects, which are really unknown (i.e., the model's parameters) and to keep the structure of the network simple and manageable. As a result, we are able to obtain a good prediction accuracy with a small synthetically generated training set, and the accuracy remains acceptable even when the network is applied in scenarios quite different from those for which it was trained. Finally, the choices of the network are "explainable", as they can be interpreted in physical terms. Comparative and experimental results prove the effectiveness of the proposed approach.