 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEDI: Trustworthy and Ethical Dataset Indicators to Analyze and Compare Dataset Documentation
May 23, 2025



Dataset transparency is a key enabler of responsible AI, but insights into multimodal dataset attributes that impact trustworthy and ethical aspects of AI applications remain scarce and are difficult to compare across datasets. To address this challenge, we introduce Trustworthy and Ethical Dataset Indicators (TEDI) that facilitate the systematic, empirical analysis of dataset documentation. TEDI encompasses 143 fine-grained indicators that characterize trustworthy and ethical attributes of multimodal datasets and their collection processes. The indicators are framed to extract verifiable information from dataset documentation. Using TEDI, we manually annotated and analyzed over 100 multimodal datasets that include human voices. We further annotated data sourcing, size, and modality details to gain insights into the factors that shape trustworthy and ethical dimensions across datasets. We find that only a select few datasets have documented attributes and practices pertaining to consent, privacy, and harmful content indicators. The extent to which these and other ethical indicators are addressed varies based on the data collection method, with documentation of datasets collected via crowdsourced and direct collection approaches being more likely to mention them. Scraping dominates scale at the cost of ethical indicators, but is not the only viable collection method. Our approach and empirical insights contribute to increasing dataset transparency along trustworthy and ethical dimensions and pave the way for automating the tedious task of extracting information from dataset documentation in future.
Neighbourhood Consensus Networks
Oct 24, 2018
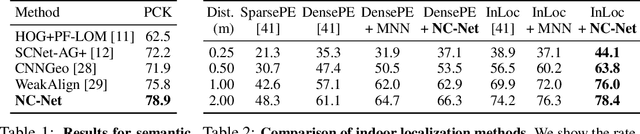


We address the problem of finding reliable dense correspondences between a pair of images. This is a challenging task due to strong appearance differences between the corresponding scene elements and ambiguities generated by repetitive patterns. The contributions of this work are threefold. First, inspired by the classic idea of disambiguating feature matches using semi-local constraints, we develop an end-to-end trainable convolutional neural network architecture that identifies sets of spatially consistent matches by analyzing neighbourhood consensus patterns in the 4D space of all possible correspondences between a pair of images without the need for a global geometric model. Second, we demonstrate that the model can be trained effectively from weak supervision in the form of matching and non-matching image pairs without the need for costly manual annotation of point to point correspondences. Third, we show the proposed neighbourhood consensus network can be applied to a range of matching tasks including both category- and instance-level matching, obtaining the state-of-the-art results on the PF Pascal dataset and the InLoc indoor visual localization benchmark.
InLoc: Indoor Visual Localization with Dense Matching and View Synthesis
Apr 08, 2018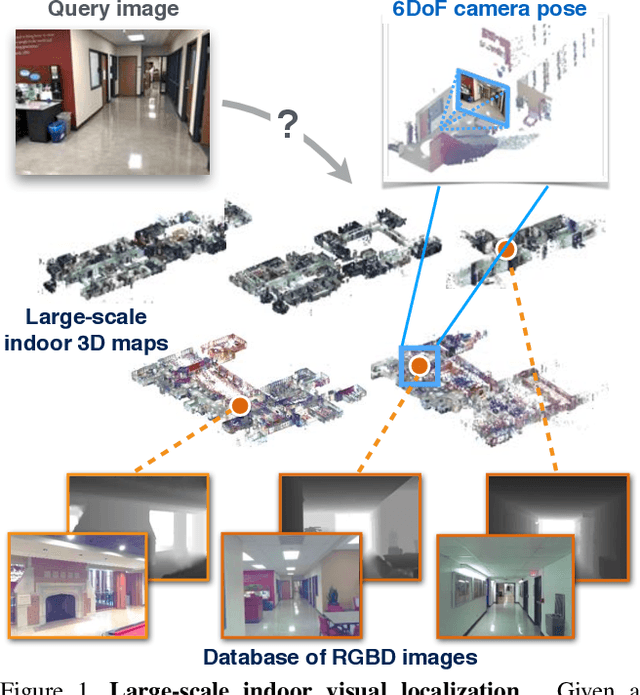

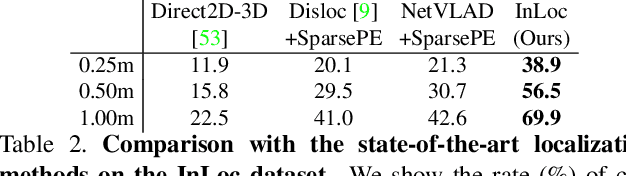

We seek to predict the 6 degree-of-freedom (6DoF) pose of a query photograph with respect to a large indoor 3D map. The contributions of this work are three-fold. First, we develop a new large-scale visual localization method targeted for indoor environments. The method proceeds along three steps: (i) efficient retrieval of candidate poses that ensures scalability to large-scale environments, (ii) pose estimation using dense matching rather than local features to deal with textureless indoor scenes, and (iii) pose verification by virtual view synthesis to cope with significant changes in viewpoint, scene layout, and occluders. Second, we collect a new dataset with reference 6DoF poses for large-scale indoor localization. Query photographs are captured by mobile phones at a different time than the reference 3D map, thus presenting a realistic indoor localization scenario. Third, we demonstrate that our method significantly outperforms current state-of-the-art indoor localization approaches on this new challenging data.
Deep filter banks for texture recognition, description, and segmentation
Nov 18, 2015



Visual textures have played a key role in image understanding because they convey important semantics of images, and because texture representations that pool local image descriptors in an orderless manner have had a tremendous impact in diverse applications. In this paper we make several contributions to texture understanding. First, instead of focusing on texture instance and material category recognition, we propose a human-interpretable vocabulary of texture attributes to describe common texture patterns, complemented by a new describable texture dataset for benchmarking. Second, we look at the problem of recognizing materials and texture attributes in realistic imaging conditions, including when textures appear in clutter, developing corresponding benchmarks on top of the recently proposed OpenSurfaces dataset. Third, we revisit classic texture representations, including bag-of-visual-words and the Fisher vectors, in the context of deep learning and show that these have excellent efficiency and generalization properties if the convolutional layers of a deep model are used as filter banks. We obtain in this manner state-of-the-art performance in numerous datasets well beyond textures, an efficient method to apply deep features to image regions, as well as benefit in transferring features from one domain to another.
Deep convolutional filter banks for texture recognition and segmentation
Jul 09, 2015
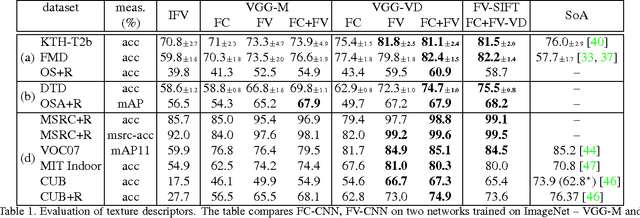


Research in texture recognition often concentrates on the problem of material recognition in uncluttered conditions, an assumption rarely met by applications. In this work we conduct a first study of material and describable texture at- tributes recognition in clutter, using a new dataset derived from the OpenSurface texture repository. Motivated by the challenge posed by this problem, we propose a new texture descriptor, D-CNN, obtained by Fisher Vector pooling of a Convolutional Neural Network (CNN) filter bank. D-CNN substantially improves the state-of-the-art in texture, mate- rial and scene recognition. Our approach achieves 82.3% accuracy on Flickr material dataset and 81.1% accuracy on MIT indoor scenes, providing absolute gains of more than 10% over existing approaches. D-CNN easily trans- fers across domains without requiring feature adaptation as for methods that build on the fully-connected layers of CNNs. Furthermore, D-CNN can seamlessly incorporate multi-scale information and describe regions of arbitrary shapes and sizes. Our approach is particularly suited at lo- calizing stuff categories and obtains state-of-the-art re- sults on MSRC segmentation dataset, as well as promising results on recognizing materials and surface attributes in clutter on the OpenSurfaces dataset.
Describing Textures in the Wild
Nov 15, 2013



Patterns and textures are defining characteristics of many natural objects: a shirt can be striped, the wings of a butterfly can be veined, and the skin of an animal can be scaly. Aiming at supporting this analytical dimension in image understanding, we address the challenging problem of describing textures with semantic attributes. We identify a rich vocabulary of forty-seven texture terms and use them to describe a large dataset of patterns collected in the wild.The resulting Describable Textures Dataset (DTD) is the basis to seek for the best texture representation for recognizing describable texture attributes in images. We port from object recognition to texture recognition the Improved Fisher Vector (IFV) and show that, surprisingly, it outperforms specialized texture descriptors not only on our problem, but also in established material recognition datasets. We also show that the describable attributes are excellent texture descriptors, transferring between datasets and tasks; in particular, combined with IFV, they significantly outperform the state-of-the-art by more than 8 percent on both FMD and KTHTIPS-2b benchmarks. We also demonstrate that they produce intuitive descriptions of materials and Internet images.