 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the quality of information extraction
Apr 05, 2024Advances in large language models have notably enhanced the efficiency of information extraction from unstructured and semi-structured data sources. As these technologies become integral to various applications, establishing an objective measure for the quality of information extraction becomes imperative. However, the scarcity of labeled data presents significant challenges to this endeavor. In this paper, we introduce an automatic framework to assess the quality of the information extraction and its completeness. The framework focuses on information extraction in the form of entity and its properties. We discuss how to handle the input/output size limitations of the large language models and analyze their performance when iteratively extracting the information. Finally, we introduce metrics to evaluate the quality of the extraction and provide an extensive discussion on how to interpret the metrics.
NetVLAD: CNN architecture for weakly supervised place recognition
May 02, 2016
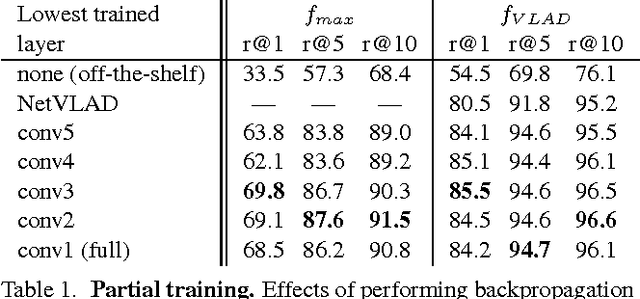

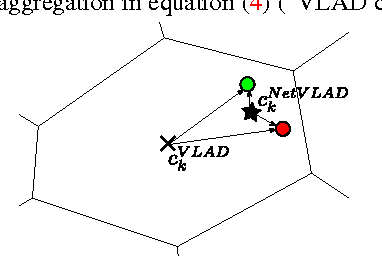
We tackle the problem of large scale visual place recognition, where the task is to quickly and accurately recognize the location of a given query photograph. We present the following three principal contributions. First, we develop a convolutional neural network (CNN) architecture that is trainable in an end-to-end manner directly for the place recognition task. The main component of this architecture, NetVLAD, is a new generalized VLAD layer, inspired by the "Vector of Locally Aggregated Descriptors" image representation commonly used in image retrieval. The layer is readily pluggable into any CNN architecture and amenable to training via backpropagation. Second, we develop a training procedure, based on a new weakly supervised ranking loss, to learn parameters of the architecture in an end-to-end manner from images depicting the same places over time downloaded from Google Street View Time Machine. Finally, we show that the proposed architecture significantly outperforms non-learnt image representations and off-the-shelf CNN descriptors on two challenging place recognition benchmarks, and improves over current state-of-the-art compact image representations on standard image retrieval benchmarks.