 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Ego-Motion Estimation Based on Multi-Layer Fusion of RGB and Inferred Depth
Paper and Code

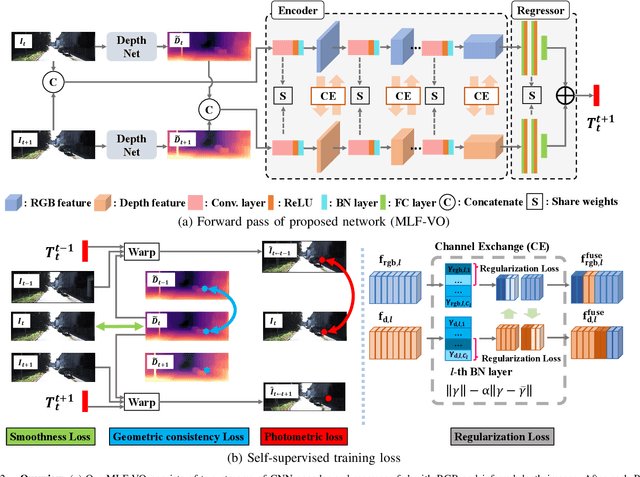
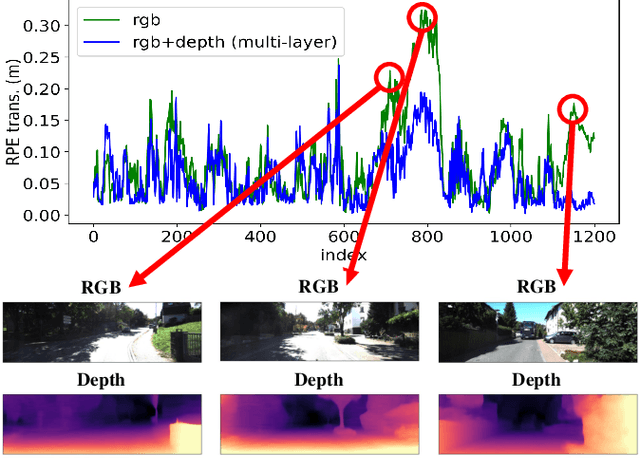

In existing self-supervised depth and ego-motion estimation methods, ego-motion estimation is usually limited to only leveraging RGB information. Recently, several methods have been proposed to further improve the accuracy of self-supervised ego-motion estimation by fusing information from other modalities, e.g., depth, acceleration, and angular velocity. However, they rarely focus on how different fusion strategies affect performance. In this paper, we investigate the effect of different fusion strategies for ego-motion estimation and propose a new framework for self-supervised learning of depth and ego-motion estimation, which performs ego-motion estimation by leveraging RGB and inferred depth information in a Multi-Layer Fusion manner. As a result, we have achieved state-of-the-art performance among learning-based methods on the KITTI odometry benchmark. Detailed studies on the design choices of leveraging inferred depth information and fusion strategies have also been carried out, which clearly demonstrate the advantages of our proposed framework.