 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Stacked Hourglass Networks for 3D Human Pose Estimation
Paper and Code
Mar 30, 2021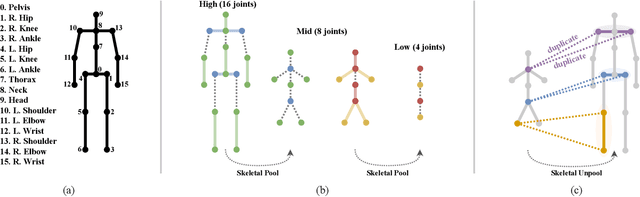
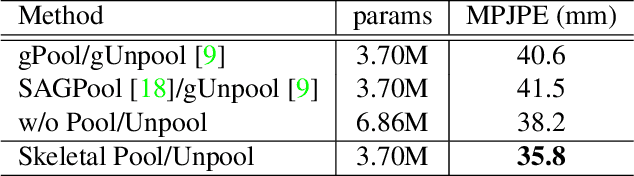
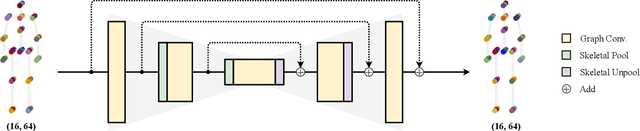
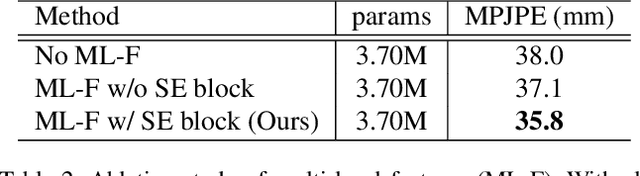
In this paper, we propose a novel graph convolutional network architecture, Graph Stacked Hourglass Networks, for 2D-to-3D human pose estimation tasks. The proposed architecture consists of repeated encoder-decoder, in which graph-structured features are processed across three different scales of human skeletal representations. This multi-scale architecture enables the model to learn both local and global feature representations, which are critical for 3D human pose estimation. We also introduce a multi-level feature learning approach using different-depth intermediate features and show the performance improvements that result from exploiting multi-scale, multi-level feature representations. Extensive experiments are conducted to validate our approach, and the results show that our model outperforms the state-of-the-art.