 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Moments from Near-Duplicate Photos
May 12, 2022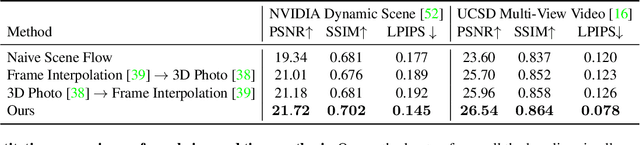
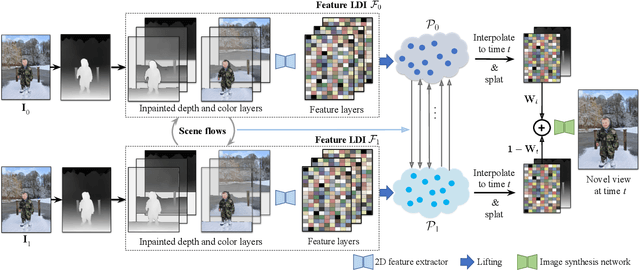
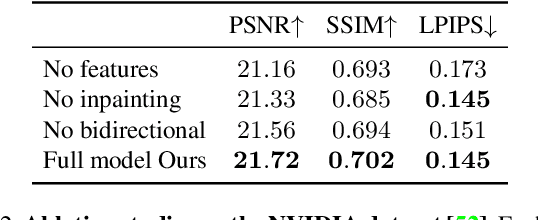
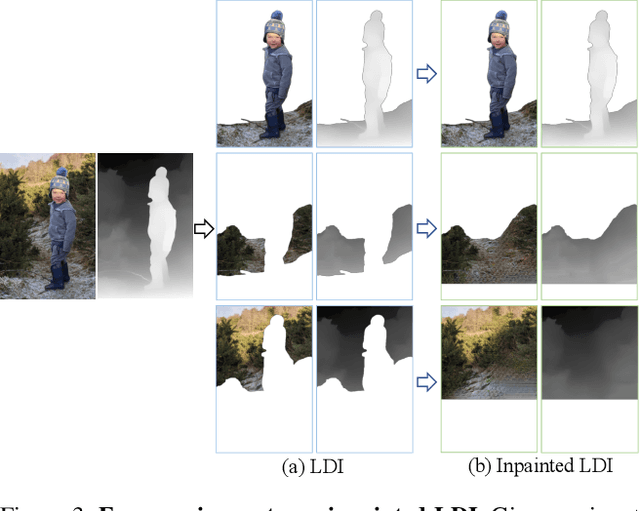
We introduce 3D Moments, a new computational photography effect. As input we take a pair of near-duplicate photos, i.e., photos of moving subjects from similar viewpoints, common in people's photo collections. As output, we produce a video that smoothly interpolates the scene motion from the first photo to the second, while also producing camera motion with parallax that gives a heightened sense of 3D. To achieve this effect, we represent the scene as a pair of feature-based layered depth images augmented with scene flow. This representation enables motion interpolation along with independent control of the camera viewpoint. Our system produces photorealistic space-time videos with motion parallax and scene dynamics, while plausibly recovering regions occluded in the original views. We conduct extensive experiments demonstrating superior performance over baselines on public datasets and in-the-wild photos. Project page: https://3d-moments.github.io/
SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting
Sep 02, 2021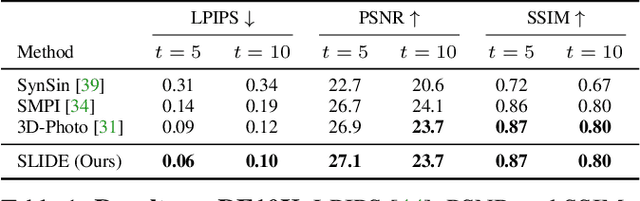
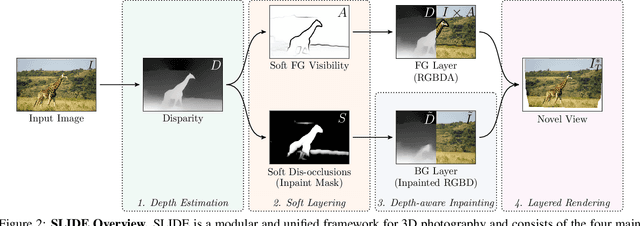
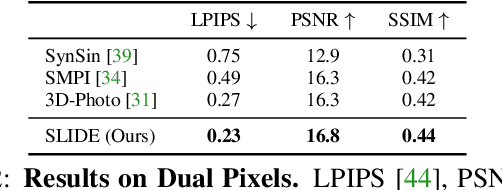

Single image 3D photography enables viewers to view a still image from novel viewpoints. Recent approaches combine monocular depth networks with inpainting networks to achieve compelling results. A drawback of these techniques is the use of hard depth layering, making them unable to model intricate appearance details such as thin hair-like structures. We present SLIDE, a modular and unified system for single image 3D photography that uses a simple yet effective soft layering strategy to better preserve appearance details in novel views. In addition, we propose a novel depth-aware training strategy for our inpainting module, better suited for the 3D photography task. The resulting SLIDE approach is modular, enabling the use of other components such as segmentation and matting for improved layering. At the same time, SLIDE uses an efficient layered depth formulation that only requires a single forward pass through the component networks to produce high quality 3D photos. Extensive experimental analysis on three view-synthesis datasets, in combination with user studies on in-the-wild image collections, demonstrate superior performance of our technique in comparison to existing strong baselines while being conceptually much simpler. Project page: https://varunjampani.github.io/slide
Layered Neural Rendering for Retiming People in Video
Sep 16, 2020
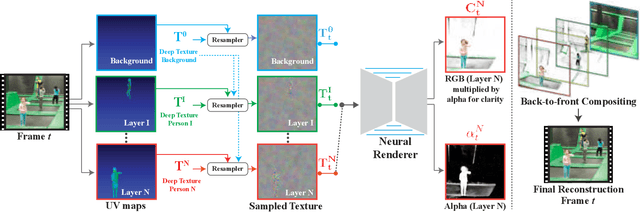

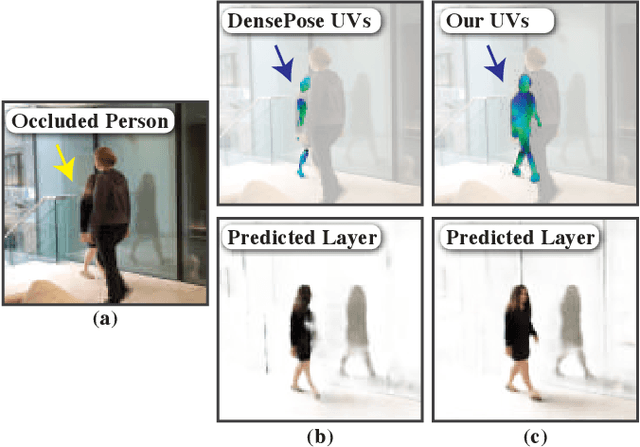
We present a method for retiming people in an ordinary, natural video---manipulating and editing the time in which different motions of individuals in the video occur. We can temporally align different motions, change the speed of certain actions (speeding up/slowing down, or entirely "freezing" people), or "erase" selected people from the video altogether. We achieve these effects computationally via a dedicated learning-based layered video representation, where each frame in the video is decomposed into separate RGBA layers, representing the appearance of different people in the video. A key property of our model is that it not only disentangles the direct motions of each person in the input video, but also correlates each person automatically with the scene changes they generate---e.g., shadows, reflections, and motion of loose clothing. The layers can be individually retimed and recombined into a new video, allowing us to achieve realistic, high-quality renderings of retiming effects for real-world videos depicting complex actions and involving multiple individuals, including dancing, trampoline jumping, or group running.