 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFT-MSF: Self-Supervised Monocular Scene Flow using Recurrent Optimizer
Paper and Code
May 03, 2022
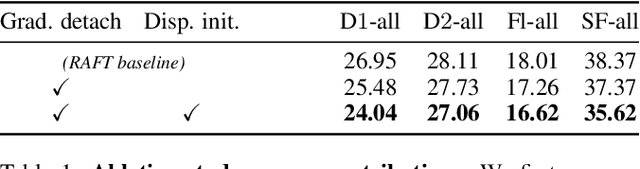
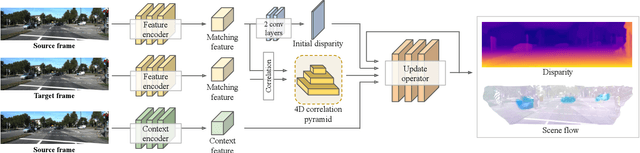
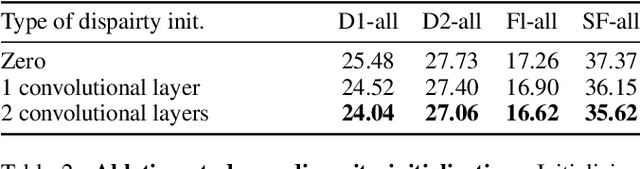
Learning scene flow from a monocular camera still remains a challenging task due to its ill-posedness as well as lack of annotated data. Self-supervised methods demonstrate learning scene flow estimation from unlabeled data, yet their accuracy lags behind (semi-)supervised methods. In this paper, we introduce a self-supervised monocular scene flow method that substantially improves the accuracy over the previous approaches. Based on RAFT, a state-of-the-art optical flow model, we design a new decoder to iteratively update 3D motion fields and disparity maps simultaneously. Furthermore, we propose an enhanced upsampling layer and a disparity initialization technique, which overall further improves accuracy up to 7.2%. Our method achieves state-of-the-art accuracy among all self-supervised monocular scene flow methods, improving accuracy by 34.2%. Our fine-tuned model outperforms the best previous semi-supervised method with 228 times faster runtime. Code will be publicly available.