 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvocation-driven Neural Approximate Computing with a Multiclass-Classifier and Multiple Approximators
Paper and Code
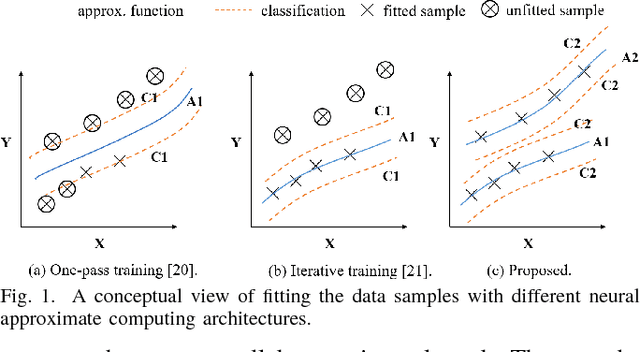
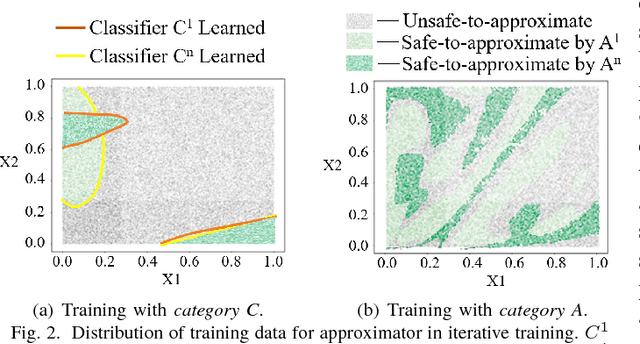
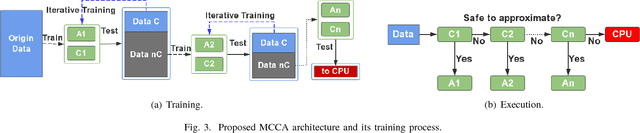
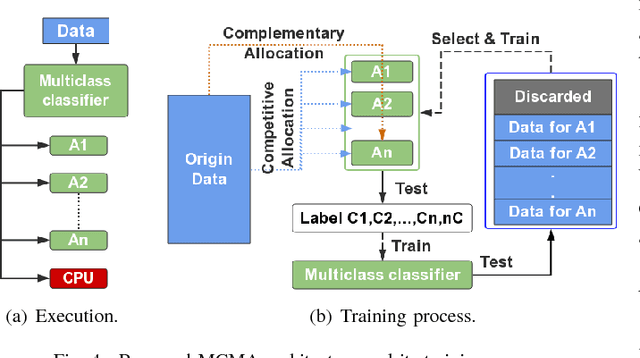
Neural approximate computing gains enormous energy-efficiency at the cost of tolerable quality-loss. A neural approximator can map the input data to output while a classifier determines whether the input data are safe to approximate with quality guarantee. However, existing works cannot maximize the invocation of the approximator, resulting in limited speedup and energy saving. By exploring the mapping space of those target functions, in this paper, we observe a nonuniform distribution of the approximation error incurred by the same approximator. We thus propose a novel approximate computing architecture with a Multiclass-Classifier and Multiple Approximators (MCMA). These approximators have identical network topologies and thus can share the same hardware resource in a neural processing unit(NPU) clip. In the runtime, MCMA can swap in the invoked approximator by merely shipping the synapse weights from the on-chip memory to the buffers near MAC within a cycle. We also propose efficient co-training methods for such MCMA architecture. Experimental results show a more substantial invocation of MCMA as well as the gain of energy-efficiency.