 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
Paper and Code
Mar 09, 2022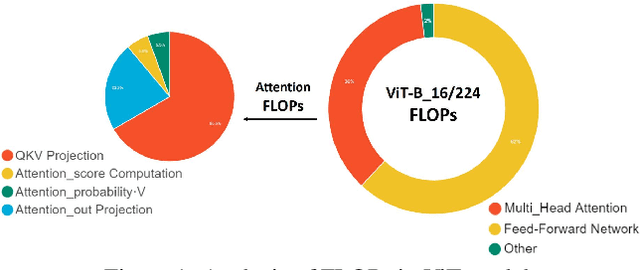
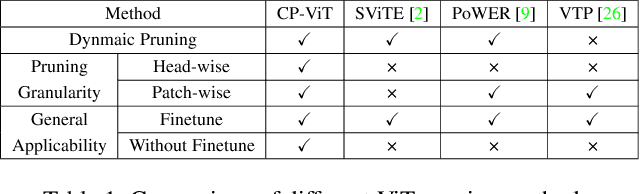
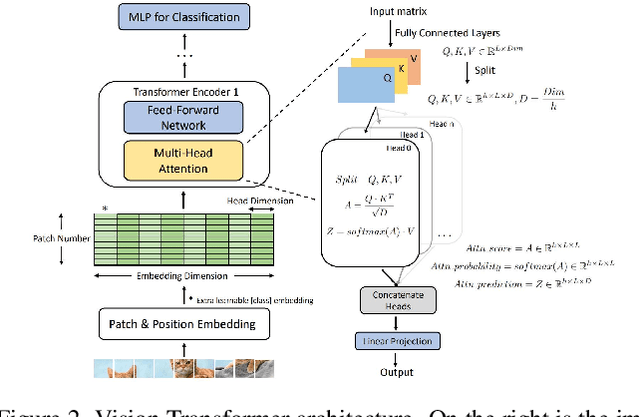
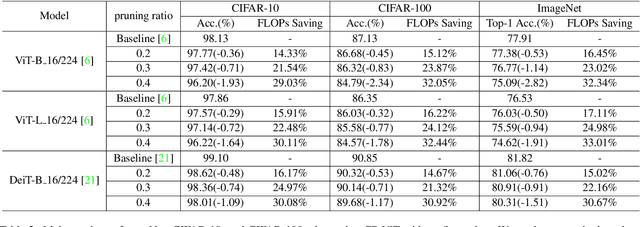
Vision transformer (ViT) has achieved competitive accuracy on a variety of computer vision applications, but its computational cost impedes the deployment on resource-limited mobile devices. We explore the sparsity in ViT and observe that informative patches and heads are sufficient for accurate image recognition. In this paper, we propose a cascade pruning framework named CP-ViT by predicting sparsity in ViT models progressively and dynamically to reduce computational redundancy while minimizing the accuracy loss. Specifically, we define the cumulative score to reserve the informative patches and heads across the ViT model for better accuracy. We also propose the dynamic pruning ratio adjustment technique based on layer-aware attention range. CP-ViT has great general applicability for practical deployment, which can be applied to a wide range of ViT models and can achieve superior accuracy with or without fine-tuning. Extensive experiments on ImageNet, CIFAR-10, and CIFAR-100 with various pre-trained models have demonstrated the effectiveness and efficiency of CP-ViT. By progressively pruning 50\% patches, our CP-ViT method reduces over 40\% FLOPs while maintaining accuracy loss within 1\%.