 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVASTIN: Sparse Video Adversarial Attack via Spatio-Temporal Invertible Neural Networks
Paper and Code
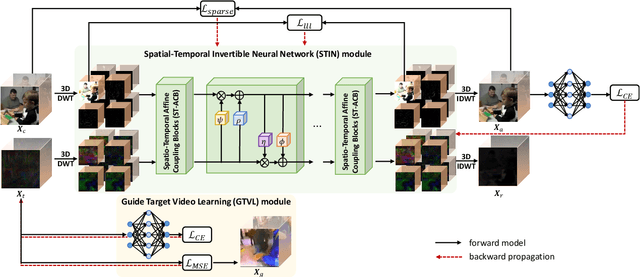

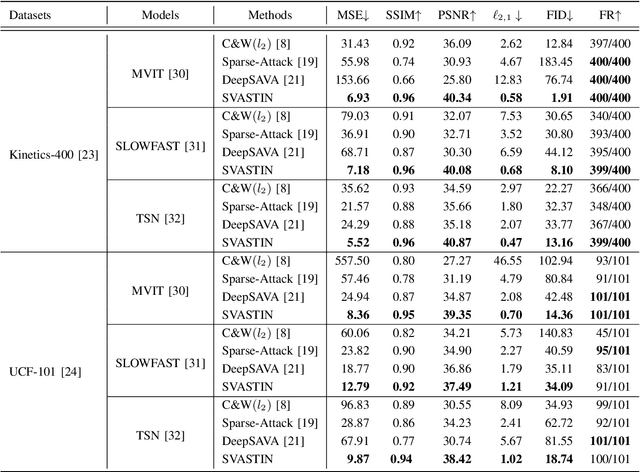
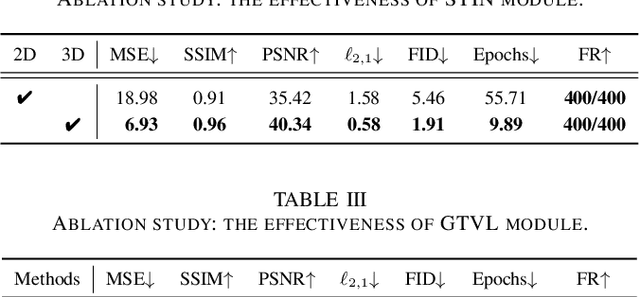
Robust and imperceptible adversarial video attack is challenging due to the spatial and temporal characteristics of videos. The existing video adversarial attack methods mainly take a gradient-based approach and generate adversarial videos with noticeable perturbations. In this paper, we propose a novel Sparse Adversarial Video Attack via Spatio-Temporal Invertible Neural Networks (SVASTIN) to generate adversarial videos through spatio-temporal feature space information exchanging. It consists of a Guided Target Video Learning (GTVL) module to balance the perturbation budget and optimization speed and a Spatio-Temporal Invertible Neural Network (STIN) module to perform spatio-temporal feature space information exchanging between a source video and the target feature tensor learned by GTVL module. Extensive experiments on UCF-101 and Kinetics-400 demonstrate that our proposed SVASTIN can generate adversarial examples with higher imperceptibility than the state-of-the-art methods with the higher fooling rate. Code is available at \href{https://github.com/Brittany-Chen/SVASTIN}{https://github.com/Brittany-Chen/SVASTIN}.