 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
ATPrompt: Textual Prompt Learning with Embedded Attributes
Dec 12, 2024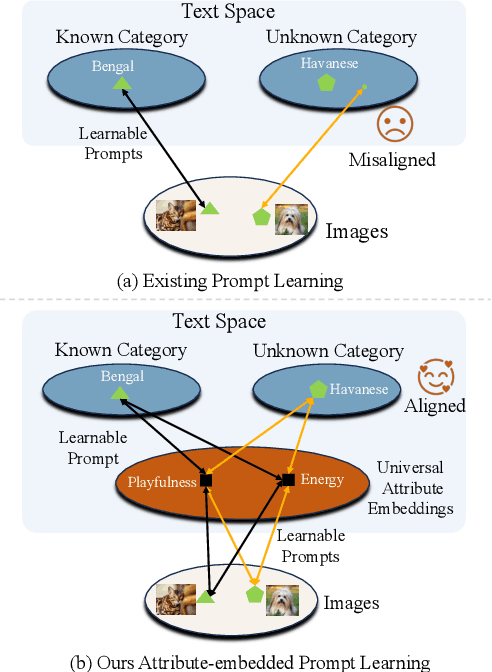
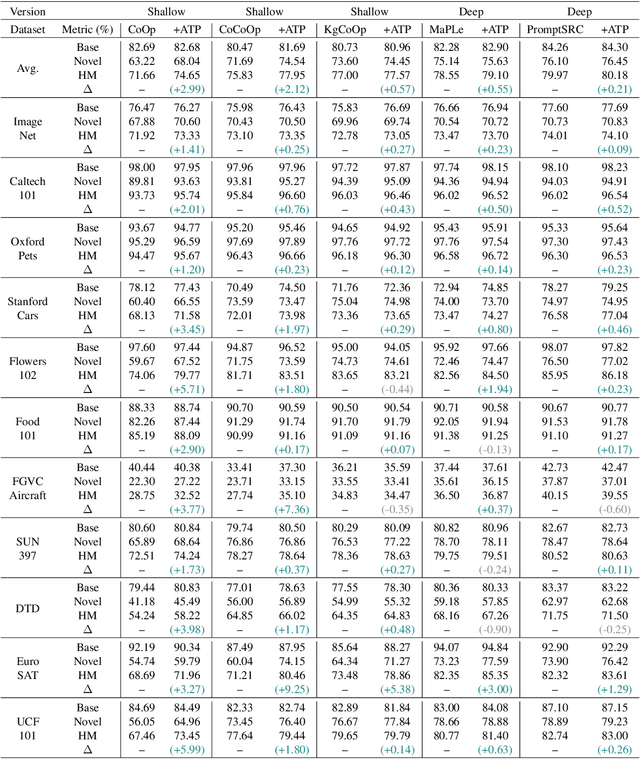
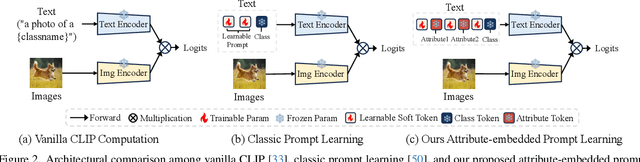
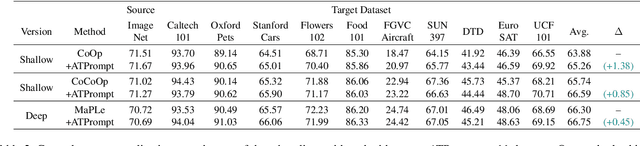
Textual-based prompt learning methods primarily employ multiple learnable soft prompts and hard class tokens in a cascading manner as text prompt inputs, aiming to align image and text (category) spaces for downstream tasks. However, current training is restricted to aligning images with predefined known categories and cannot be associated with unknown categories. In this work, we propose utilizing universal attributes as a bridge to enhance the alignment between images and unknown categories. Specifically, we introduce an Attribute-embedded Textual Prompt learning method for vision-language models, named ATPrompt. This approach expands the learning space of soft prompts from the original one-dimensional category level into the multi-dimensional attribute level by incorporating multiple universal attribute tokens into the learnable soft prompts. Through this modification, we transform the text prompt from a category-centric form to an attribute-category hybrid form. To finalize the attributes for downstream tasks, we propose a differentiable attribute search method that learns to identify representative and suitable attributes from a candidate pool summarized by a large language model. As an easy-to-use plug-in technique, ATPrompt can seamlessly replace the existing prompt format of textual-based methods, offering general improvements at a negligible computational cost. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
From Words to Worth: Newborn Article Impact Prediction with LLM
Aug 07, 2024As the academic landscape expands, the challenge of efficiently identifying potentially high-impact articles among the vast number of newly published works becomes critical. This paper introduces a promising approach, leveraging the capabilities of fine-tuned LLMs to predict the future impact of newborn articles solely based on titles and abstracts. Moving beyond traditional methods heavily reliant on external information, the proposed method discerns the shared semantic features of highly impactful papers from a large collection of title-abstract and potential impact pairs. These semantic features are further utilized to regress an improved metric, TNCSI_SP, which has been endowed with value, field, and time normalization properties. Additionally, a comprehensive dataset has been constructed and released for fine-tuning the LLM, containing over 12,000 entries with corresponding titles, abstracts, and TNCSI_SP. The quantitative results, with an NDCG@20 of 0.901, demonstrate that the proposed approach achieves state-of-the-art performance in predicting the impact of newborn articles when compared to competitive counterparts. Finally, we demonstrate a real-world application for predicting the impact of newborn journal articles to demonstrate its noteworthy practical value. Overall, our findings challenge existing paradigms and propose a shift towards a more content-focused prediction of academic impact, offering new insights for assessing newborn article impact.
A Literature Review of Literature Reviews in Pattern Analysis and Machine Intelligence
Feb 29, 2024



By consolidating scattered knowledge, the literature review provides a comprehensive understanding of the investigated topic. However, excessive reviews, especially in the booming field of pattern analysis and machine intelligence (PAMI), raise concerns for both researchers and reviewers. In response to these concerns, this Analysis aims to provide a thorough review of reviews in the PAMI field from diverse perspectives. First, large language model-empowered bibliometric indicators are proposed to evaluate literature reviews automatically. To facilitate this, a meta-data database dubbed RiPAMI, and a topic dataset are constructed, which are utilized to obtain statistical characteristics of PAMI reviews. Unlike traditional bibliometric measurements, the proposed article-level indicators provide real-time and field-normalized quantified assessments of reviews without relying on user-defined keywords. Second, based on these indicators, the study presents comparative analyses of different reviews, unveiling the characteristics of publications across various fields, periods, and journals. The newly emerging AI-generated literature reviews are also appraised, and the observed differences suggest that most AI-generated reviews still lag behind human-authored reviews in several aspects. Third, we briefly provide a subjective evaluation of representative PAMI reviews and introduce a paper structure-based typology of literature reviews. This typology may improve the clarity and effectiveness for scholars in reading and writing reviews, while also serving as a guide for AI systems in generating well-organized reviews. Finally, this Analysis offers insights into the current challenges of literature reviews and envisions future directions for their development.
Is Synthetic Data From Diffusion Models Ready for Knowledge Distillation?
May 22, 2023



Diffusion models have recently achieved astonishing performance in generating high-fidelity photo-realistic images. Given their huge success, it is still unclear whether synthetic images are applicable for knowledge distillation when real images are unavailable. In this paper, we extensively study whether and how synthetic images produced from state-of-the-art diffusion models can be used for knowledge distillation without access to real images, and obtain three key conclusions: (1) synthetic data from diffusion models can easily lead to state-of-the-art performance among existing synthesis-based distillation methods, (2) low-fidelity synthetic images are better teaching materials, and (3) relatively weak classifiers are better teachers. Code is available at https://github.com/zhengli97/DM-KD.
Accurate Fine-grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation
Oct 23, 2021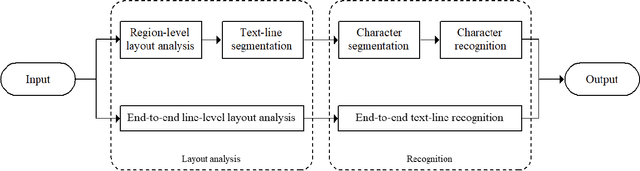



Accurate layout analysis without subsequent text-line segmentation remains an ongoing challenge, especially when facing the Kangyur, a kind of historical Tibetan document featuring considerable touching components and mottled background. Aiming at identifying different regions in document images, layout analysis is indispensable for subsequent procedures such as character recognition. However, there was only a little research being carried out to perform line-level layout analysis which failed to deal with the Kangyur. To obtain the optimal results, a fine-grained sub-line level layout analysis approach is presented. Firstly, we introduced an accelerated method to build the dataset which is dynamic and reliable. Secondly, enhancement had been made to the SOLOv2 according to the characteristics of the Kangyur. Then, we fed the enhanced SOLOv2 with the prepared annotation file during the training phase. Once the network is trained, instances of the text line, sentence, and titles can be segmented and identified during the inference stage. The experimental results show that the proposed method delivers a decent 72.7% AP on our dataset. In general, this preliminary research provides insights into the fine-grained sub-line level layout analysis and testifies the SOLOv2-based approaches. We also believe that the proposed methods can be adopted on other language documents with various layouts.