 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFilter: Improving Robustness of Retrieval-Augmented Generation via Gated Filter
Feb 13, 2026Retrieval-augmented generation (RAG) has become a dominant paradigm for grounding large language models (LLMs) with external evidence in knowledge-intensive question answering. A core design choice is how to fuse retrieved samples into the LLMs, where existing internal fusion approaches broadly fall into query-based fusion, parametric fusion, and latent-based fusion. Despite their effectiveness at modest retrieval scales, these methods often fail to scale gracefully as the number of retrieved candidates k increases: Larger k improves evidence coverage, yet realistic top-k retrieval inevitably contains irrelevant or redundant content and increases the inference cost. To address these limitations, we propose ReFilter, a novel latent-based fusion framework that performs token-level filtering and fusion. ReFilter consists of three key components: a context encoder for encoding context features, a gated filter for weighting each token, and a token fusion module for integrating the weighted token feature into the LLM's hidden states. Our experiments across four general-domain QA benchmarks show that ReFilter consistently achieves the best average performance under both in-domain adaptation and out-of-domain transfer. ReFilter further generalizes to five biomedical QA benchmarks in zero-shot transfer without domain fine-tuning, reaching 70.01% average accuracy with Qwen2.5-14B-Instruct.
Beyond Semantic Similarity: Reducing Unnecessary API Calls via Behavior-Aligned Retriever
Aug 20, 2025Tool-augmented large language models (LLMs) leverage external functions to extend their capabilities, but inaccurate function calls can lead to inefficiencies and increased costs.Existing methods address this challenge by fine-tuning LLMs or using demonstration-based prompting, yet they often suffer from high training overhead and fail to account for inconsistent demonstration samples, which misguide the model's invocation behavior. In this paper, we trained a behavior-aligned retriever (BAR), which provides behaviorally consistent demonstrations to help LLMs make more accurate tool-using decisions. To train the BAR, we construct a corpus including different function-calling behaviors, i.e., calling or non-calling.We use the contrastive learning framework to train the BAR with customized positive/negative pairs and a dual-negative contrastive loss, ensuring robust retrieval of behaviorally consistent examples.Experiments demonstrate that our approach significantly reduces erroneous function calls while maintaining high task performance, offering a cost-effective and efficient solution for tool-augmented LLMs.
FlexInfer: Breaking Memory Constraint via Flexible and Efficient Offloading for On-Device LLM Inference
Mar 04, 2025
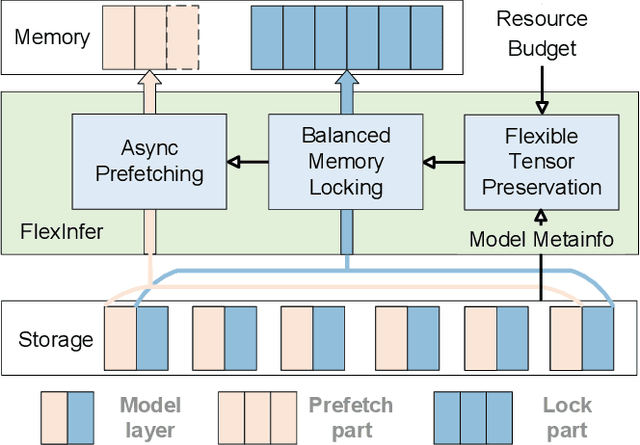
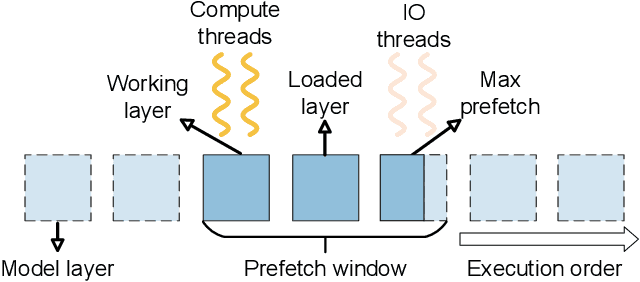
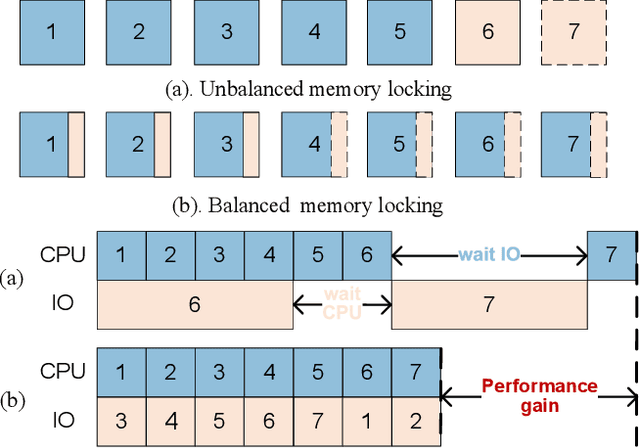
Large Language Models (LLMs) face challenges for on-device inference due to high memory demands. Traditional methods to reduce memory usage often compromise performance and lack adaptability. We propose FlexInfer, an optimized offloading framework for on-device inference, addressing these issues with techniques like asynchronous prefetching, balanced memory locking, and flexible tensor preservation. These strategies enhance memory efficiency and mitigate I/O bottlenecks, ensuring high performance within user-specified resource constraints. Experiments demonstrate that FlexInfer significantly improves throughput under limited resources, achieving up to 12.5 times better performance than existing methods and facilitating the deployment of large models on resource-constrained devices.
EvoP: Robust LLM Inference via Evolutionary Pruning
Feb 19, 2025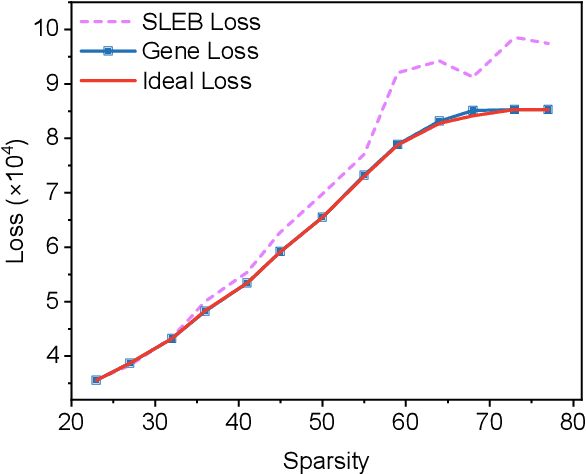
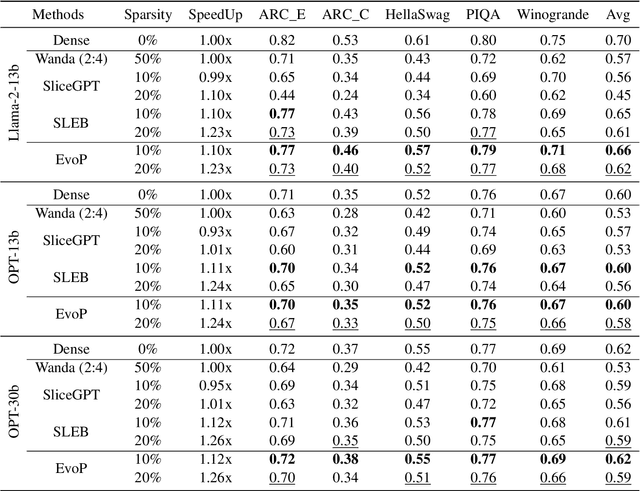
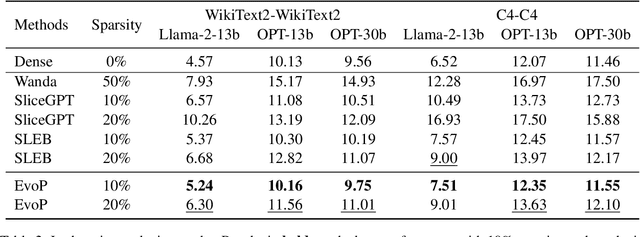
Large Language Models (LLMs) have achieved remarkable success in natural language processing tasks, but their massive size and computational demands hinder their deployment in resource-constrained environments. Existing structured pruning methods address this issue by removing redundant structures (e.g., elements, channels, layers) from the model. However, these methods employ a heuristic pruning strategy, which leads to suboptimal performance. Besides, they also ignore the data characteristics when pruning the model. To overcome these limitations, we propose EvoP, an evolutionary pruning framework for robust LLM inference. EvoP first presents a cluster-based calibration dataset sampling (CCDS) strategy for creating a more diverse calibration dataset. EvoP then introduces an evolutionary pruning pattern searching (EPPS) method to find the optimal pruning pattern. Compared to existing structured pruning techniques, EvoP achieves the best performance while maintaining the best efficiency. Experiments across different LLMs and different downstream tasks validate the effectiveness of the proposed EvoP, making it a practical and scalable solution for deploying LLMs in real-world applications.
A$^2$ATS: Retrieval-Based KV Cache Reduction via Windowed Rotary Position Embedding and Query-Aware Vector Quantization
Feb 18, 2025


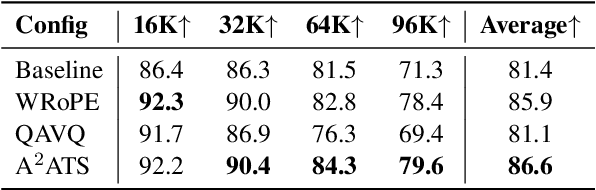
Long context large language models (LLMs) pose significant challenges for efficient serving due to the large memory footprint and high access overhead of KV cache. Retrieval-based KV cache reduction methods can mitigate these challenges, typically by offloading the complete KV cache to CPU and retrieving necessary tokens on demand during inference. However, these methods still suffer from unsatisfactory accuracy degradation and extra retrieval overhead. To address these limitations, this paper proposes A$^2$ATS, a novel retrieval-based KV cache reduction method. A$^2$ATS aims to obtain an accurate approximation of attention scores by applying the vector quantization technique to key states, thereby enabling efficient and precise retrieval of the top-K tokens. First, we propose Windowed Rotary Position Embedding, which decouples the positional dependency from query and key states after position embedding. Then, we propose query-aware vector quantization that optimizes the objective of attention score approximation directly. Finally, we design the heterogeneous inference architecture for KV cache offloading, enabling long context serving with larger batch sizes. Experimental results demonstrate that A$^2$ATS can achieve a lower performance degradation with similar or lower overhead compared to existing methods, thereby increasing long context serving throughput by up to $2.7 \times$.
GeneQuery: A General QA-based Framework for Spatial Gene Expression Predictions from Histology Images
Nov 27, 2024



Gene expression profiling provides profound insights into molecular mechanisms, but its time-consuming and costly nature often presents significant challenges. In contrast, whole-slide hematoxylin and eosin (H&E) stained histological images are readily accessible and allow for detailed examinations of tissue structure and composition at the microscopic level. Recent advancements have utilized these histological images to predict spatially resolved gene expression profiles. However, state-of-the-art works treat gene expression prediction as a multi-output regression problem, where each gene is learned independently with its own weights, failing to capture the shared dependencies and co-expression patterns between genes. Besides, existing works can only predict gene expression values for genes seen during training, limiting their ability to generalize to new, unseen genes. To address the above limitations, this paper presents GeneQuery, which aims to solve this gene expression prediction task in a question-answering (QA) manner for better generality and flexibility. Specifically, GeneQuery takes gene-related texts as queries and whole-slide images as contexts and then predicts the queried gene expression values. With such a transformation, GeneQuery can implicitly estimate the gene distribution by introducing the gene random variable. Besides, the proposed GeneQuery consists of two architecture implementations, i.e., spot-aware GeneQuery for capturing patterns between images and gene-aware GeneQuery for capturing patterns between genes. Comprehensive experiments on spatial transcriptomics datasets show that the proposed GeneQuery outperforms existing state-of-the-art methods on known and unseen genes. More results also demonstrate that GeneQuery can potentially analyze the tissue structure.
CHESS: Optimizing LLM Inference via Channel-Wise Thresholding and Selective Sparsification
Sep 02, 2024



Deploying large language models (LLMs) on edge devices presents significant challenges due to the substantial computational overhead and memory requirements. Activation sparsification can mitigate these challenges by reducing the number of activated neurons during inference. Existing methods typically employ thresholding-based sparsification based on the statistics of activation tensors. However, these methods do not explicitly model the impact of activation sparsification on performance, leading to suboptimal performance degradation. To address this issue, this paper reformulates the activation sparsification problem by introducing a new objective that optimizes the sparsification decisions. Building on this reformulation, we propose CHESS, a general activation sparsification approach via CHannel-wise thrEsholding and Selective Sparsification. First, channel-wise thresholding assigns a unique threshold to each activation channel in the feed-forward network (FFN) layers. Then, selective sparsification involves applying thresholding-based activation sparsification to specific layers within the attention modules. Finally, we detail the implementation of sparse kernels to accelerate LLM inference. Experimental results demonstrate that the proposed CHESS achieves lower performance degradation over 8 downstream tasks while activating fewer parameters compared to existing methods, thus speeding up the LLM inference by up to 1.27x.
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Jul 19, 2024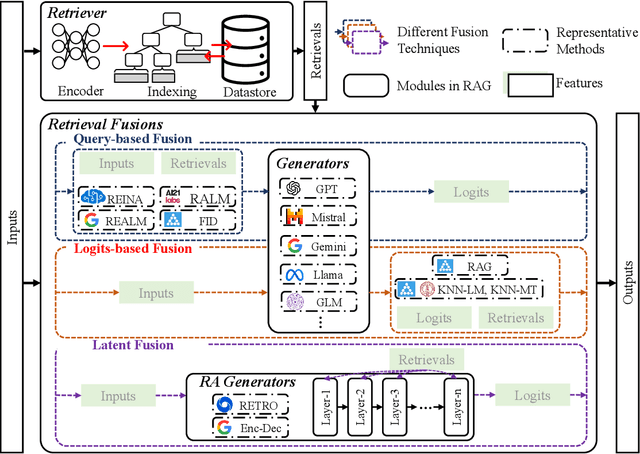
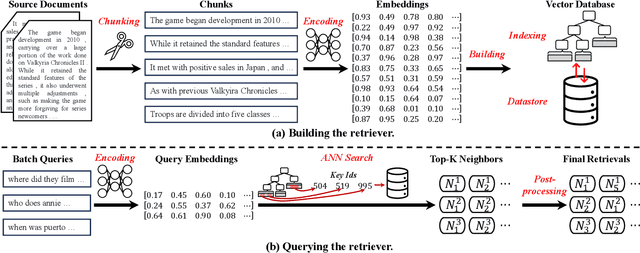
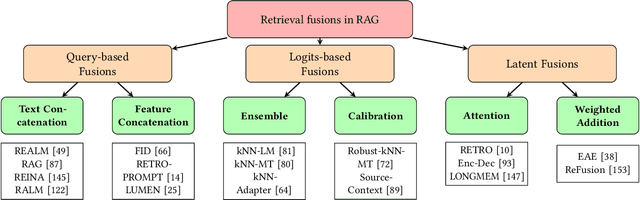
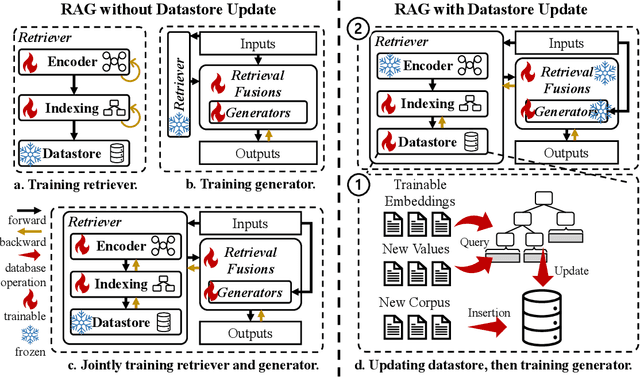
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
RAEE: A Training-Free Retrieval-Augmented Early Exiting Framework for Efficient Inference
May 24, 2024



Deploying large language model inference remains challenging due to their high computational overhead. Early exiting accelerates model inference by adaptively reducing the number of inference layers. Existing methods require training internal classifiers to determine whether to exit at each intermediate layer. However, such classifier-based early exiting frameworks require significant effort to design and train the classifiers. To address these limitations, this paper proposes RAEE, a training-free Retrieval-Augmented Early Exiting framework for efficient inference. First, this paper demonstrates that the early exiting problem can be modeled as a distribution prediction problem, where the distribution is approximated using similar data's existing information. Next, the paper details the process of collecting existing information to build the retrieval database. Finally, based on the pre-built retrieval database, RAEE leverages the retrieved similar data's exiting information to guide the backbone model to exit at the layer, which is predicted by the approximated distribution. Experimental results demonstrate that the proposed RAEE can significantly accelerate inference. RAEE also achieves state-of-the-art zero-shot performance on 8 classification tasks.
Improving Natural Language Understanding with Computation-Efficient Retrieval Representation Fusion
Jan 04, 2024Retrieval-based augmentations that aim to incorporate knowledge from an external database into language models have achieved great success in various knowledge-intensive (KI) tasks, such as question-answering and text generation. However, integrating retrievals in non-knowledge-intensive (NKI) tasks, such as text classification, is still challenging. Existing works focus on concatenating retrievals to inputs as context to form the prompt-based inputs. Unfortunately, such methods require language models to have the capability to handle long texts. Besides, inferring such concatenated data would also consume a significant amount of computational resources. To solve these challenges, we propose \textbf{ReFusion} in this paper, a computation-efficient \textbf{Re}trieval representation \textbf{Fusion} with neural architecture search. The main idea is to directly fuse the retrieval representations into the language models. Specifically, we first propose an online retrieval module that retrieves representations of similar sentences. Then, we present a retrieval fusion module including two effective ranking schemes, i.e., reranker-based scheme and ordered-mask-based scheme, to fuse the retrieval representations with hidden states. Furthermore, we use Neural Architecture Search (NAS) to seek the optimal fusion structure across different layers. Finally, we conduct comprehensive experiments, and the results demonstrate our ReFusion can achieve superior and robust performance on various NKI tasks.