 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexInfer: Breaking Memory Constraint via Flexible and Efficient Offloading for On-Device LLM Inference
Paper and Code
Mar 04, 2025
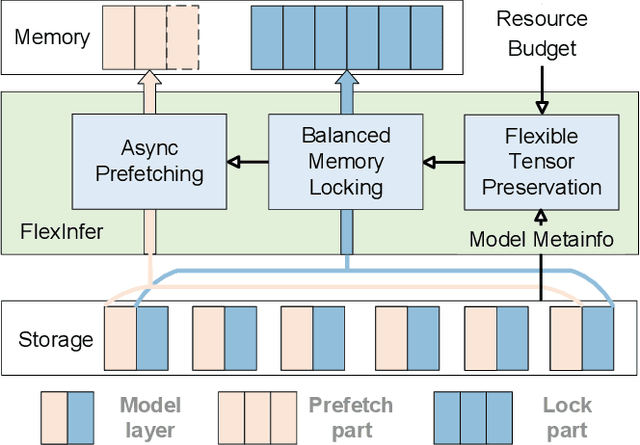
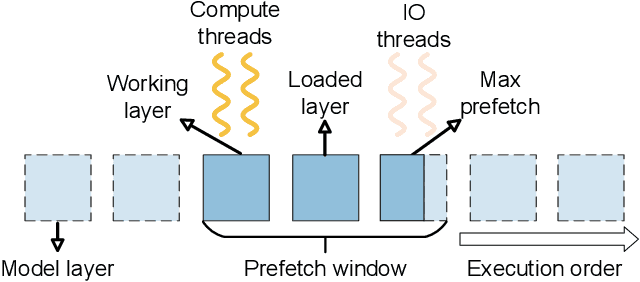
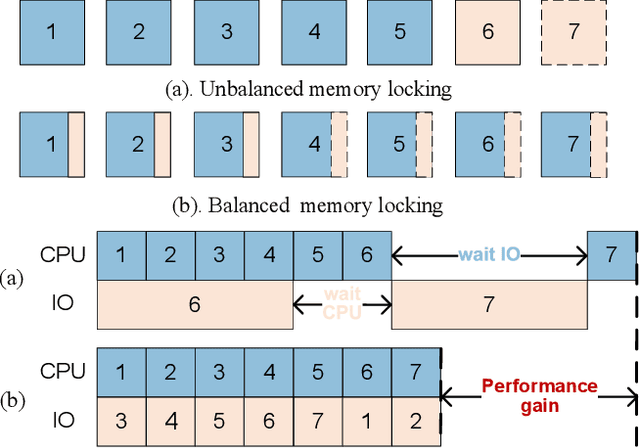
Large Language Models (LLMs) face challenges for on-device inference due to high memory demands. Traditional methods to reduce memory usage often compromise performance and lack adaptability. We propose FlexInfer, an optimized offloading framework for on-device inference, addressing these issues with techniques like asynchronous prefetching, balanced memory locking, and flexible tensor preservation. These strategies enhance memory efficiency and mitigate I/O bottlenecks, ensuring high performance within user-specified resource constraints. Experiments demonstrate that FlexInfer significantly improves throughput under limited resources, achieving up to 12.5 times better performance than existing methods and facilitating the deployment of large models on resource-constrained devices.