 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOP: Prefill-Only Pruning for Efficient Large Model Inference
Feb 03, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated remarkable capabilities. However, their deployment is hindered by significant computational costs. Existing structured pruning methods, while hardware-efficient, often suffer from significant accuracy degradation. In this paper, we argue that this failure stems from a stage-agnostic pruning approach that overlooks the asymmetric roles between the prefill and decode stages. By introducing a virtual gate mechanism, our importance analysis reveals that deep layers are critical for next-token prediction (decode) but largely redundant for context encoding (prefill). Leveraging this insight, we propose Prefill-Only Pruning (POP), a stage-aware inference strategy that safely omits deep layers during the computationally intensive prefill stage while retaining the full model for the sensitive decode stage. To enable the transition between stages, we introduce independent Key-Value (KV) projections to maintain cache integrity, and a boundary handling strategy to ensure the accuracy of the first generated token. Extensive experiments on Llama-3.1, Qwen3-VL, and Gemma-3 across diverse modalities demonstrate that POP achieves up to 1.37$\times$ speedup in prefill latency with minimal performance loss, effectively overcoming the accuracy-efficiency trade-off limitations of existing structured pruning methods.
A$^2$ATS: Retrieval-Based KV Cache Reduction via Windowed Rotary Position Embedding and Query-Aware Vector Quantization
Feb 18, 2025


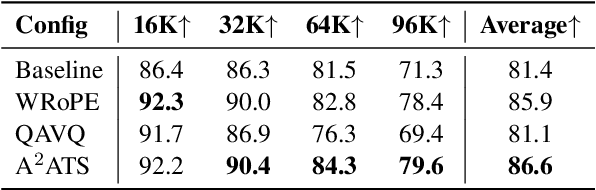
Long context large language models (LLMs) pose significant challenges for efficient serving due to the large memory footprint and high access overhead of KV cache. Retrieval-based KV cache reduction methods can mitigate these challenges, typically by offloading the complete KV cache to CPU and retrieving necessary tokens on demand during inference. However, these methods still suffer from unsatisfactory accuracy degradation and extra retrieval overhead. To address these limitations, this paper proposes A$^2$ATS, a novel retrieval-based KV cache reduction method. A$^2$ATS aims to obtain an accurate approximation of attention scores by applying the vector quantization technique to key states, thereby enabling efficient and precise retrieval of the top-K tokens. First, we propose Windowed Rotary Position Embedding, which decouples the positional dependency from query and key states after position embedding. Then, we propose query-aware vector quantization that optimizes the objective of attention score approximation directly. Finally, we design the heterogeneous inference architecture for KV cache offloading, enabling long context serving with larger batch sizes. Experimental results demonstrate that A$^2$ATS can achieve a lower performance degradation with similar or lower overhead compared to existing methods, thereby increasing long context serving throughput by up to $2.7 \times$.
CHESS: Optimizing LLM Inference via Channel-Wise Thresholding and Selective Sparsification
Sep 02, 2024



Deploying large language models (LLMs) on edge devices presents significant challenges due to the substantial computational overhead and memory requirements. Activation sparsification can mitigate these challenges by reducing the number of activated neurons during inference. Existing methods typically employ thresholding-based sparsification based on the statistics of activation tensors. However, these methods do not explicitly model the impact of activation sparsification on performance, leading to suboptimal performance degradation. To address this issue, this paper reformulates the activation sparsification problem by introducing a new objective that optimizes the sparsification decisions. Building on this reformulation, we propose CHESS, a general activation sparsification approach via CHannel-wise thrEsholding and Selective Sparsification. First, channel-wise thresholding assigns a unique threshold to each activation channel in the feed-forward network (FFN) layers. Then, selective sparsification involves applying thresholding-based activation sparsification to specific layers within the attention modules. Finally, we detail the implementation of sparse kernels to accelerate LLM inference. Experimental results demonstrate that the proposed CHESS achieves lower performance degradation over 8 downstream tasks while activating fewer parameters compared to existing methods, thus speeding up the LLM inference by up to 1.27x.