 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-driven approach to inferring travel trajectory during peak hours in urban rail transit systems
Dec 10, 2025Refined trajectory inference of urban rail transit is of great significance to the operation organization. In this paper, we develop a fully data-driven approach to inferring individual travel trajectories in urban rail transit systems. It utilizes data from the Automatic Fare Collection (AFC) and Automatic Vehicle Location (AVL) systems to infer key trajectory elements, such as selected train, access/egress time, and transfer time. The approach includes establishing train alternative sets based on spatio-temporal constraints, data-driven adaptive trajectory inference, and trave l trajectory construction. To realize data-driven adaptive trajectory inference, a data-driven parameter estimation method based on KL divergence combined with EM algorithm (KLEM) was proposed. This method eliminates the reliance on external or survey data for parameter fitting, enhancing the robustness and applicability of the model. Furthermore, to overcome the limitations of using synthetic data to validate the result, this paper employs real individual travel trajectory data for verification. The results show that the approach developed in this paper can achieve high-precision passenger trajectory inference, with an accuracy rate of over 90% in urban rail transit travel trajectory inference during peak hours.
RAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse
Nov 05, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with retrieved context but often suffers from downgraded prefill performance as modern applications demand longer and more complex inputs. Existing caching techniques either preserve accuracy with low cache reuse or improve reuse at the cost of degraded reasoning quality. We present RAGBoost, an efficient RAG system that achieves high cache reuse without sacrificing accuracy through accuracy-preserving context reuse. RAGBoost detects overlapping retrieved items across concurrent sessions and multi-turn interactions, using efficient context indexing, ordering, and de-duplication to maximize reuse, while lightweight contextual hints maintain reasoning fidelity. It integrates seamlessly with existing LLM inference engines and improves their prefill performance by 1.5-3X over state-of-the-art methods, while preserving or even enhancing reasoning accuracy across diverse RAG and agentic AI workloads. Our code is released at: https://github.com/Edinburgh-AgenticAI/RAGBoost.
D2SL: Decouple Defogging and Semantic Learning for Foggy Domain-Adaptive Segmentation
Apr 07, 2024We investigated domain adaptive semantic segmentation in foggy weather scenarios, which aims to enhance the utilization of unlabeled foggy data and improve the model's adaptability to foggy conditions. Current methods rely on clear images as references, jointly learning defogging and segmentation for foggy images. Despite making some progress, there are still two main drawbacks: (1) the coupling of segmentation and defogging feature representations, resulting in a decrease in semantic representation capability, and (2) the failure to leverage real fog priors in unlabeled foggy data, leading to insufficient model generalization ability. To address these issues, we propose a novel training framework, Decouple Defogging and Semantic learning, called D2SL, aiming to alleviate the adverse impact of defogging tasks on the final segmentation task. In this framework, we introduce a domain-consistent transfer strategy to establish a connection between defogging and segmentation tasks. Furthermore, we design a real fog transfer strategy to improve defogging effects by fully leveraging the fog priors from real foggy images. Our approach enhances the semantic representations required for segmentation during the defogging learning process and maximizes the representation capability of fog invariance by effectively utilizing real fog data. Comprehensive experiments validate the effectiveness of the proposed method.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
NFL: Robust Learned Index via Distribution Transformation
May 24, 2022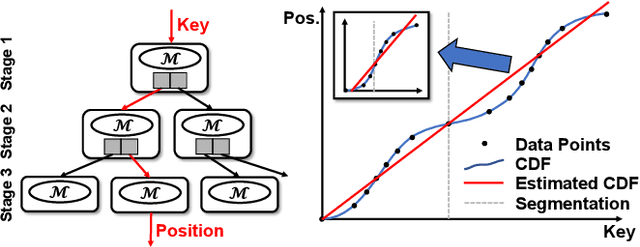
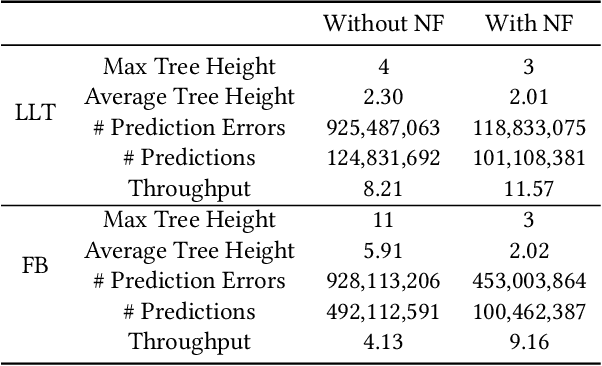
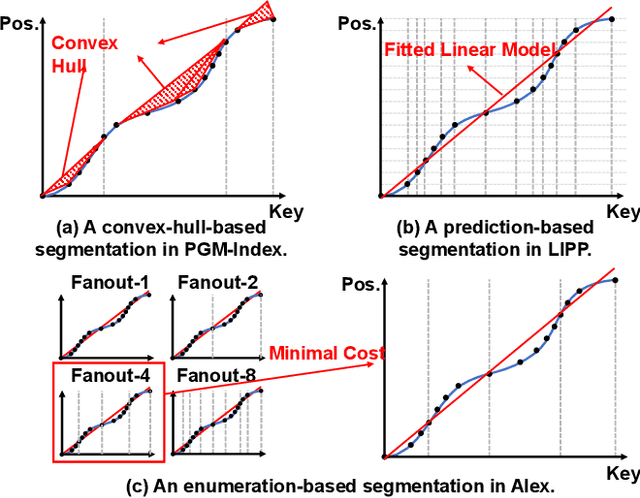
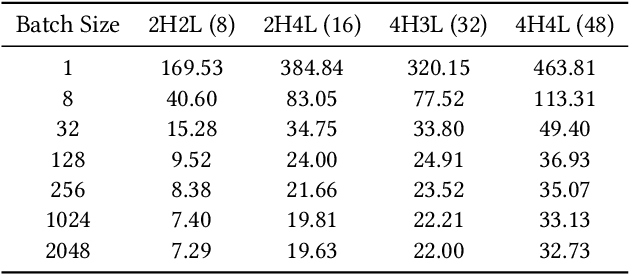
Recent works on learned index open a new direction for the indexing field. The key insight of the learned index is to approximate the mapping between keys and positions with piece-wise linear functions. Such methods require partitioning key space for a better approximation. Although lots of heuristics are proposed to improve the approximation quality, the bottleneck is that the segmentation overheads could hinder the overall performance. This paper tackles the approximation problem by applying a \textit{distribution transformation} to the keys before constructing the learned index. A two-stage Normalizing-Flow-based Learned index framework (NFL) is proposed, which first transforms the original complex key distribution into a near-uniform distribution, then builds a learned index leveraging the transformed keys. For effective distribution transformation, we propose a Numerical Normalizing Flow (Numerical NF). Based on the characteristics of the transformed keys, we propose a robust After-Flow Learned Index (AFLI). To validate the performance, comprehensive evaluations are conducted on both synthetic and real-world workloads, which shows that the proposed NFL produces the highest throughput and the lowest tail latency compared to the state-of-the-art learned indexes.