Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Image Captioning
Dec 06, 2020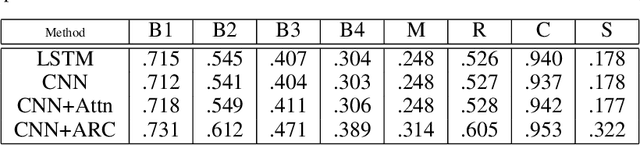
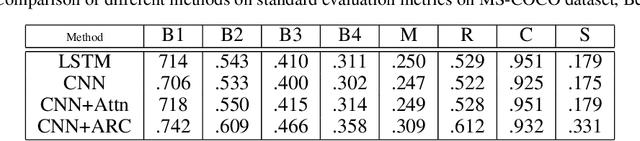
Automated captioning of photos is a mission that incorporates the difficulties of photo analysis and text generation. One essential feature of captioning is the concept of attention: how to determine what to specify and in which sequence. In this study, we leverage the Object Relation using adversarial robust cut algorithm, that grows upon this method by specifically embedding knowledge about the spatial association between input data through graph representation. Our experimental study represent the promising performance of our proposed method for image captioning.
Via