 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Manipulation via Imitation Learning: Taxonomy, Evolution, Benchmark, and Challenges
Aug 24, 2025



Robotic Manipulation (RM) is central to the advancement of autonomous robots, enabling them to interact with and manipulate objects in real-world environments. This survey focuses on RM methodologies that leverage imitation learning, a powerful technique that allows robots to learn complex manipulation skills by mimicking human demonstrations. We identify and analyze the most influential studies in this domain, selected based on community impact and intrinsic quality. For each paper, we provide a structured summary, covering the research purpose, technical implementation, hierarchical classification, input formats, key priors, strengths and limitations, and citation metrics. Additionally, we trace the chronological development of imitation learning techniques within RM policy (RMP), offering a timeline of key technological advancements. Where available, we report benchmark results and perform quantitative evaluations to compare existing methods. By synthesizing these insights, this review provides a comprehensive resource for researchers and practitioners, highlighting both the state of the art and the challenges that lie ahead in the field of robotic manipulation through imitation learning.
Is an object-centric representation beneficial for robotic manipulation ?
Jun 24, 2025



Object-centric representation (OCR) has recently become a subject of interest in the computer vision community for learning a structured representation of images and videos. It has been several times presented as a potential way to improve data-efficiency and generalization capabilities to learn an agent on downstream tasks. However, most existing work only evaluates such models on scene decomposition, without any notion of reasoning over the learned representation. Robotic manipulation tasks generally involve multi-object environments with potential inter-object interaction. We thus argue that they are a very interesting playground to really evaluate the potential of existing object-centric work. To do so, we create several robotic manipulation tasks in simulated environments involving multiple objects (several distractors, the robot, etc.) and a high-level of randomization (object positions, colors, shapes, background, initial positions, etc.). We then evaluate one classical object-centric method across several generalization scenarios and compare its results against several state-of-the-art hollistic representations. Our results exhibit that existing methods are prone to failure in difficult scenarios involving complex scene structures, whereas object-centric methods help overcome these challenges.
Object-Centric Representations Improve Policy Generalization in Robot Manipulation
May 16, 2025Visual representations are central to the learning and generalization capabilities of robotic manipulation policies. While existing methods rely on global or dense features, such representations often entangle task-relevant and irrelevant scene information, limiting robustness under distribution shifts. In this work, we investigate object-centric representations (OCR) as a structured alternative that segments visual input into a finished set of entities, introducing inductive biases that align more naturally with manipulation tasks. We benchmark a range of visual encoders-object-centric, global and dense methods-across a suite of simulated and real-world manipulation tasks ranging from simple to complex, and evaluate their generalization under diverse visual conditions including changes in lighting, texture, and the presence of distractors. Our findings reveal that OCR-based policies outperform dense and global representations in generalization settings, even without task-specific pretraining. These insights suggest that OCR is a promising direction for designing visual systems that generalize effectively in dynamic, real-world robotic environments.
Bayesian Optimization for Developmental Robotics with Meta-Learning by Parameters Bounds Reduction
Jul 30, 2020



In robotics, methods and softwares usually require optimizations of hyperparameters in order to be efficient for specific tasks, for instance industrial bin-picking from homogeneous heaps of different objects. We present a developmental framework based on long-term memory and reasoning modules (Bayesian Optimisation, visual similarity and parameters bounds reduction) allowing a robot to use meta-learning mechanism increasing the efficiency of such continuous and constrained parameters optimizations. The new optimization, viewed as a learning for the robot, can take advantage of past experiences (stored in the episodic and procedural memories) to shrink the search space by using reduced parameters bounds computed from the best optimizations realized by the robot with similar tasks of the new one (e.g. bin-picking from an homogenous heap of a similar object, based on visual similarity of objects stored in the semantic memory). As example, we have confronted the system to the constrained optimizations of 9 continuous hyperparameters for a professional software (Kamido) in industrial robotic arm bin-picking tasks, a step that is needed each time to handle correctly new object. We used a simulator to create bin-picking tasks for 8 different objects (7 in simulation and one with real setup, without and with meta-learning with experiences coming from other similar objects) achieving goods results despite a very small optimization budget, with a better performance reached when meta-learning is used (84.3% vs 78.9% of success overall, with a small budget of 30 iterations for each optimization) for every object tested (p-value=0.036).
Visual and Semantic Knowledge Transfer for Large Scale Semi-supervised Object Detection
Mar 13, 2018
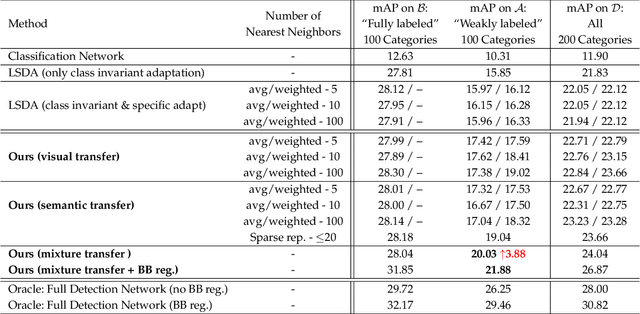


Deep CNN-based object detection systems have achieved remarkable success on several large-scale object detection benchmarks. However, training such detectors requires a large number of labeled bounding boxes, which are more difficult to obtain than image-level annotations. Previous work addresses this issue by transforming image-level classifiers into object detectors. This is done by modeling the differences between the two on categories with both image-level and bounding box annotations, and transferring this information to convert classifiers to detectors for categories without bounding box annotations. We improve this previous work by incorporating knowledge about object similarities from visual and semantic domains during the transfer process. The intuition behind our proposed method is that visually and semantically similar categories should exhibit more common transferable properties than dissimilar categories, e.g. a better detector would result by transforming the differences between a dog classifier and a dog detector onto the cat class, than would by transforming from the violin class. Experimental results on the challenging ILSVRC2013 detection dataset demonstrate that each of our proposed object similarity based knowledge transfer methods outperforms the baseline methods. We found strong evidence that visual similarity and semantic relatedness are complementary for the task, and when combined notably improve detection, achieving state-of-the-art detection performance in a semi-supervised setting.
* TPAMI. correct some typos