 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaive Bayes-based Context Extension for Large Language Models
Mar 26, 2024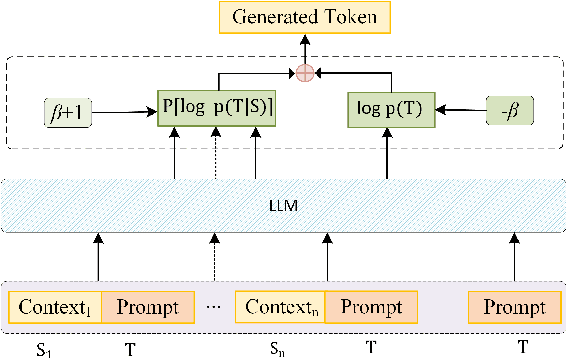
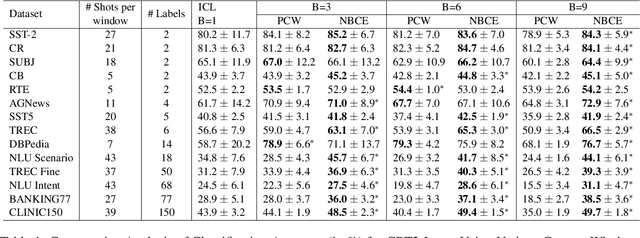
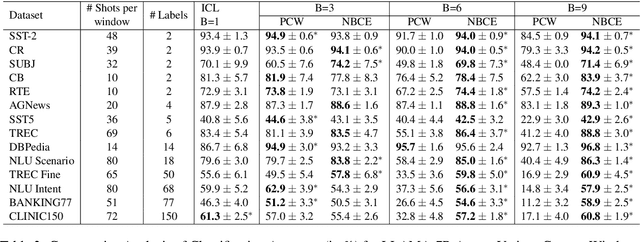
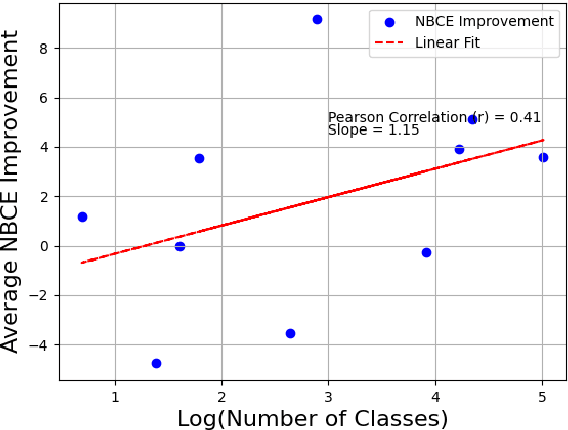
Large Language Models (LLMs) have shown promising in-context learning abilities. However, conventional In-Context Learning (ICL) approaches are often impeded by length limitations of transformer architecture, which pose challenges when attempting to effectively integrate supervision from a substantial number of demonstration examples. In this paper, we introduce a novel framework, called Naive Bayes-based Context Extension (NBCE), to enable existing LLMs to perform ICL with an increased number of demonstrations by significantly expanding their context size. Importantly, this expansion does not require fine-tuning or dependence on particular model architectures, all the while preserving linear efficiency. NBCE initially splits the context into equal-sized windows fitting the target LLM's maximum length. Then, it introduces a voting mechanism to select the most relevant window, regarded as the posterior context. Finally, it employs Bayes' theorem to generate the test task. Our experimental results demonstrate that NBCE substantially enhances performance, particularly as the number of demonstration examples increases, consistently outperforming alternative methods. The NBCE code will be made publicly accessible. The code NBCE is available at: https://github.com/amurtadha/NBCE-master
ZLPR: A Novel Loss for Multi-label Classification
Aug 05, 2022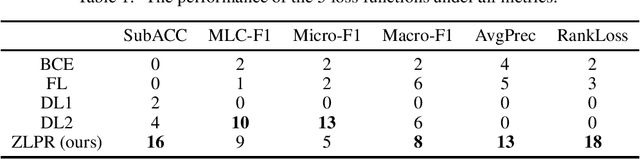
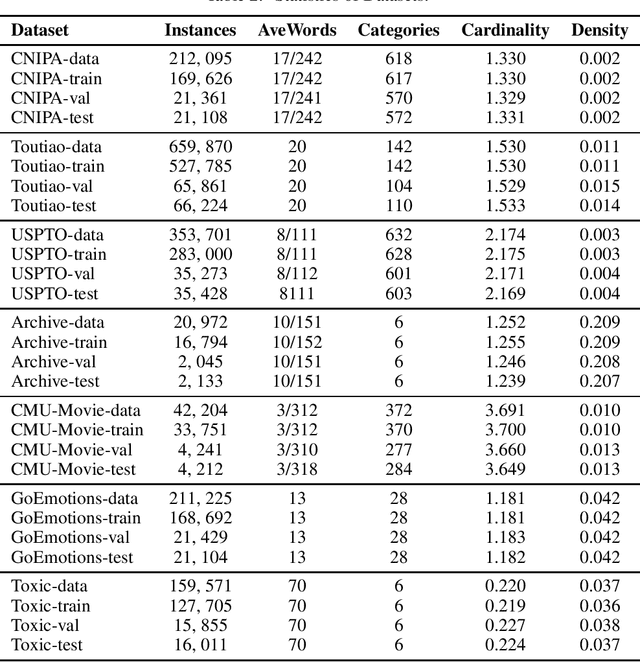
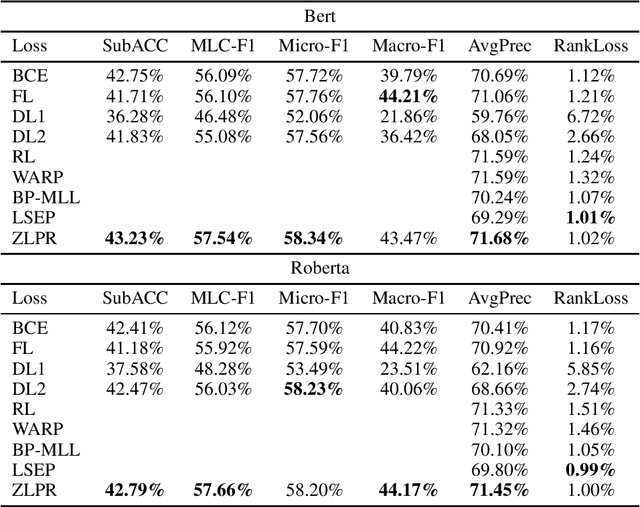
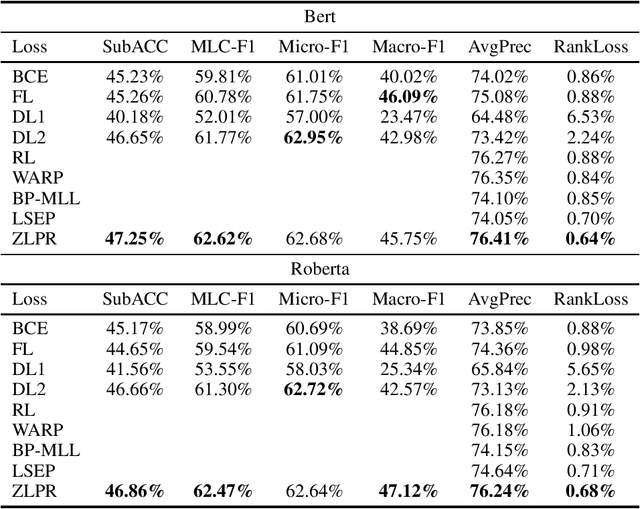
In the era of deep learning, loss functions determine the range of tasks available to models and algorithms. To support the application of deep learning in multi-label classification (MLC) tasks, we propose the ZLPR (zero-bounded log-sum-exp \& pairwise rank-based) loss in this paper. Compared to other rank-based losses for MLC, ZLPR can handel problems that the number of target labels is uncertain, which, in this point of view, makes it equally capable with the other two strategies often used in MLC, namely the binary relevance (BR) and the label powerset (LP). Additionally, ZLPR takes the corelation between labels into consideration, which makes it more comprehensive than the BR methods. In terms of computational complexity, ZLPR can compete with the BR methods because its prediction is also label-independent, which makes it take less time and memory than the LP methods. Our experiments demonstrate the effectiveness of ZLPR on multiple benchmark datasets and multiple evaluation metrics. Moreover, we propose the soft version and the corresponding KL-divergency calculation method of ZLPR, which makes it possible to apply some regularization tricks such as label smoothing to enhance the generalization of models.