 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-material Direct Ink Writing and Embroidery for Stretchable Wearable Sensors
Mar 18, 2026The development of wearable sensing systems for sports performance tracking, rehabilitation, and injury prevention has driven growing demand for smart garments that combine comfort, durability, and accurate motion detection. This paper presents a textile-compatible fabrication workflow that integrates multi-material direct ink writing with automated embroidery to create stretchable strain sensors directly embedded into garments. The process combines sequential multi-material printing of a silicone-carbon grease-silicone stack with automated embroidery that provides both mechanical fixation and electrical interfacing in a single step. The resulting hybrid sensor demonstrates stretchability up to 120% strain while maintaining electrical continuity, with approximately linear behaviour up to 60% strain (R^2 = 0.99), a gauge factor of 31.4, and hysteresis of 22.9%. Repeated loading-unloading tests over 80 cycles show baseline and peak drift of 0.135% and 0.236% per cycle, respectively, indicating moderate cycle-to-cycle stability. Mechanical testing further confirms that the silicone-fabric interface remains intact under large deformation, with failure occurring in the textile rather than at the stitched boundary. As a preliminary proof of concept, the sensor was integrated into wearable elbow and knee sleeves for joint angle monitoring, showing a clear correlation between normalised resistance change and bending angle. By addressing both mechanical fixation and electrical interfacing through embroidery-based integration, this approach provides a reproducible and scalable pathway for incorporating printed stretchable electronics into textile systems for motion capture and soft robotic applications.
OphGLM: Training an Ophthalmology Large Language-and-Vision Assistant based on Instructions and Dialogue
Jun 22, 2023



Large multimodal language models (LMMs) have achieved significant success in general domains. However, due to the significant differences between medical images and text and general web content, the performance of LMMs in medical scenarios is limited. In ophthalmology, clinical diagnosis relies on multiple modalities of medical images, but unfortunately, multimodal ophthalmic large language models have not been explored to date. In this paper, we study and construct an ophthalmic large multimodal model. Firstly, we use fundus images as an entry point to build a disease assessment and diagnosis pipeline to achieve common ophthalmic disease diagnosis and lesion segmentation. Then, we establish a new ophthalmic multimodal instruction-following and dialogue fine-tuning dataset based on disease-related knowledge data and publicly available real-world medical dialogue. We introduce visual ability into the large language model to complete the ophthalmic large language and vision assistant (OphGLM). Our experimental results demonstrate that the OphGLM model performs exceptionally well, and it has the potential to revolutionize clinical applications in ophthalmology. The dataset, code, and models will be made publicly available at https://github.com/ML-AILab/OphGLM.
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
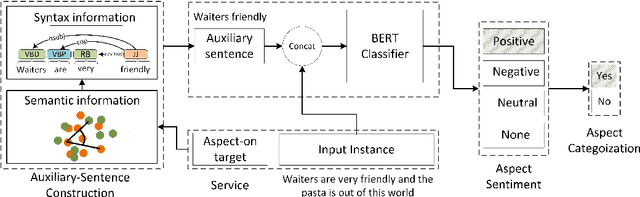
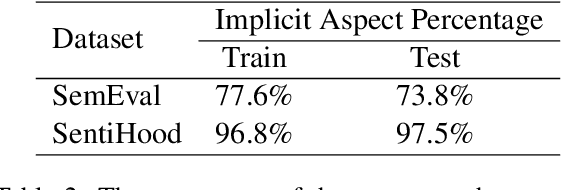

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.