 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-RAIL: A Real-Time Asynchronous Inference Linker for VLA Models and Robots
Dec 31, 2025Vision-Language-Action (VLA) models have achieved remarkable breakthroughs in robotics, with the action chunk playing a dominant role in these advances. Given the real-time and continuous nature of robotic motion control, the strategies for fusing a queue of successive action chunks have a profound impact on the overall performance of VLA models. Existing methods suffer from jitter, stalling, or even pauses in robotic action execution, which not only limits the achievable execution speed but also reduces the overall success rate of task completion. This paper introduces VLA-RAIL (A Real-Time Asynchronous Inference Linker), a novel framework designed to address these issues by conducting model inference and robot motion control asynchronously and guaranteeing smooth, continuous, and high-speed action execution. The core contributions of the paper are two fold: a Trajectory Smoother that effectively filters out the noise and jitter in the trajectory of one action chunk using polynomial fitting and a Chunk Fuser that seamlessly align the current executing trajectory and the newly arrived chunk, ensuring position, velocity, and acceleration continuity between two successive action chunks. We validate the effectiveness of VLA-RAIL on a benchmark of dynamic simulation tasks and several real-world manipulation tasks. Experimental results demonstrate that VLA-RAIL significantly reduces motion jitter, enhances execution speed, and improves task success rates, which will become a key infrastructure for the large-scale deployment of VLA models.
Monocular Visual Place Recognition in LiDAR Maps via Cross-Modal State Space Model and Multi-View Matching
Oct 08, 2024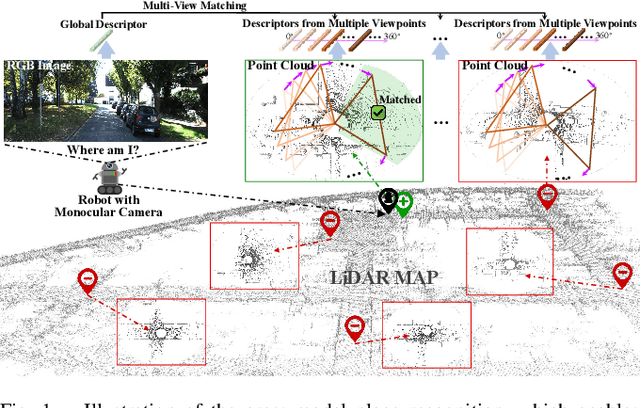
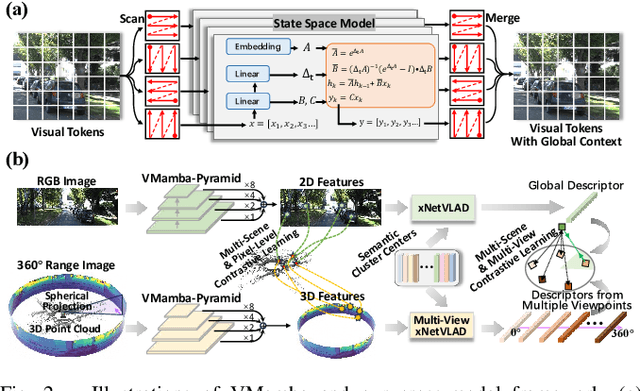
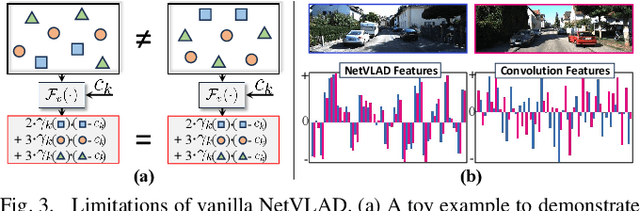
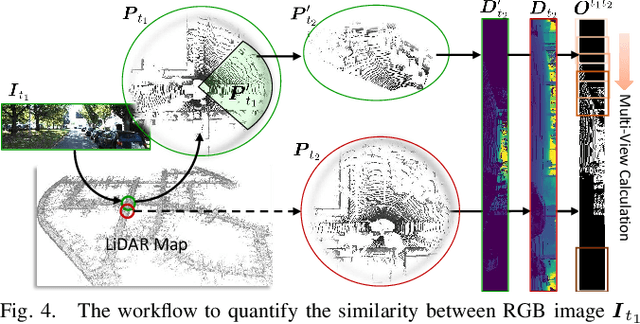
Achieving monocular camera localization within pre-built LiDAR maps can bypass the simultaneous mapping process of visual SLAM systems, potentially reducing the computational overhead of autonomous localization. To this end, one of the key challenges is cross-modal place recognition, which involves retrieving 3D scenes (point clouds) from a LiDAR map according to online RGB images. In this paper, we introduce an efficient framework to learn descriptors for both RGB images and point clouds. It takes visual state space model (VMamba) as the backbone and employs a pixel-view-scene joint training strategy for cross-modal contrastive learning. To address the field-of-view differences, independent descriptors are generated from multiple evenly distributed viewpoints for point clouds. A visible 3D points overlap strategy is then designed to quantify the similarity between point cloud views and RGB images for multi-view supervision. Additionally, when generating descriptors from pixel-level features using NetVLAD, we compensate for the loss of geometric information, and introduce an efficient scheme for multi-view generation. Experimental results on the KITTI and KITTI-360 datasets demonstrate the effectiveness and generalization of our method. The code will be released upon acceptance.
MaFreeI2P: A Matching-Free Image-to-Point Cloud Registration Paradigm with Active Camera Pose Retrieval
Aug 05, 2024
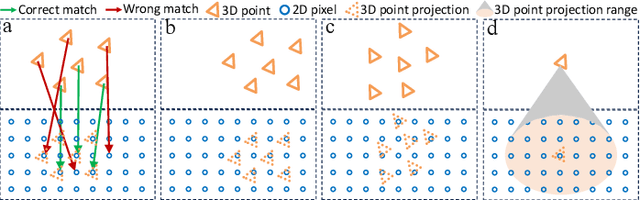

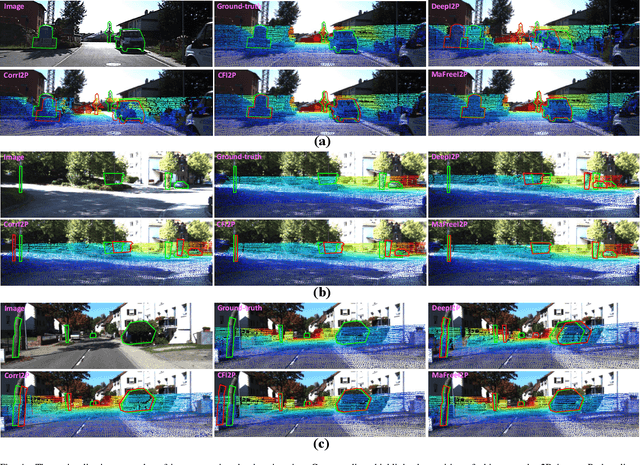
Image-to-point cloud registration seeks to estimate their relative camera pose, which remains an open question due to the data modality gaps. The recent matching-based methods tend to tackle this by building 2D-3D correspondences. In this paper, we reveal the information loss inherent in these methods and propose a matching-free paradigm, named MaFreeI2P. Our key insight is to actively retrieve the camera pose in SE(3) space by contrasting the geometric features between the point cloud and the query image. To achieve this, we first sample a set of candidate camera poses and construct their cost volume using the cross-modal features. Superior to matching, cost volume can preserve more information and its feature similarity implicitly reflects the confidence level of the sampled poses. Afterwards, we employ a convolutional network to adaptively formulate a similarity assessment function, where the input cost volume is further improved by filtering and pose-based weighting. Finally, we update the camera pose based on the similarity scores, and adopt a heuristic strategy to iteratively shrink the pose sampling space for convergence. Our MaFreeI2P achieves a very competitive registration accuracy and recall on the KITTI-Odometry and Apollo-DaoxiangLake datasets.
CMR-Agent: Learning a Cross-Modal Agent for Iterative Image-to-Point Cloud Registration
Aug 05, 2024



Image-to-point cloud registration aims to determine the relative camera pose of an RGB image with respect to a point cloud. It plays an important role in camera localization within pre-built LiDAR maps. Despite the modality gaps, most learning-based methods establish 2D-3D point correspondences in feature space without any feedback mechanism for iterative optimization, resulting in poor accuracy and interpretability. In this paper, we propose to reformulate the registration procedure as an iterative Markov decision process, allowing for incremental adjustments to the camera pose based on each intermediate state. To achieve this, we employ reinforcement learning to develop a cross-modal registration agent (CMR-Agent), and use imitation learning to initialize its registration policy for stability and quick-start of the training. According to the cross-modal observations, we propose a 2D-3D hybrid state representation that fully exploits the fine-grained features of RGB images while reducing the useless neutral states caused by the spatial truncation of camera frustum. Additionally, the overall framework is well-designed to efficiently reuse one-shot cross-modal embeddings, avoiding repetitive and time-consuming feature extraction. Extensive experiments on the KITTI-Odometry and NuScenes datasets demonstrate that CMR-Agent achieves competitive accuracy and efficiency in registration. Once the one-shot embeddings are completed, each iteration only takes a few milliseconds.
FAGhead: Fully Animate Gaussian Head from Monocular Videos
Jun 27, 2024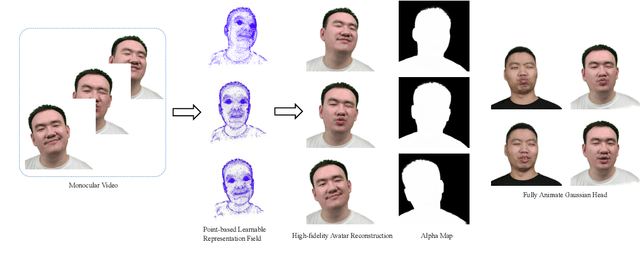
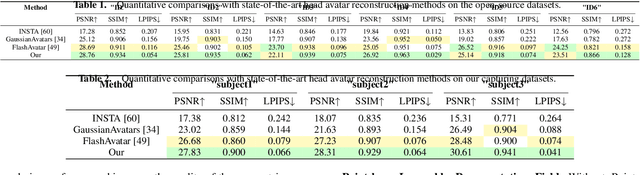
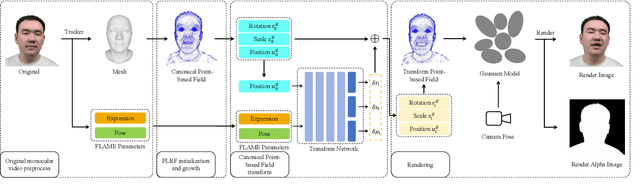
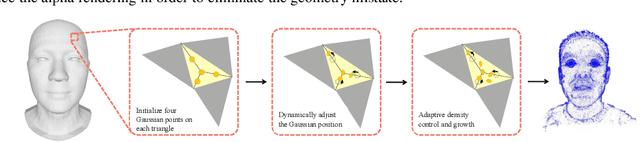
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
GGAvatar: Geometric Adjustment of Gaussian Head Avatar
May 20, 2024



We propose GGAvatar, a novel 3D avatar representation designed to robustly model dynamic head avatars with complex identities and deformations. GGAvatar employs a coarse-to-fine structure, featuring two core modules: Neutral Gaussian Initialization Module and Geometry Morph Adjuster. Neutral Gaussian Initialization Module pairs Gaussian primitives with deformable triangular meshes, employing an adaptive density control strategy to model the geometric structure of the target subject with neutral expressions. Geometry Morph Adjuster introduces deformation bases for each Gaussian in global space, creating fine-grained low-dimensional representations of deformation behaviors to address the Linear Blend Skinning formula's limitations effectively. Extensive experiments show that GGAvatar can produce high-fidelity renderings, outperforming state-of-the-art methods in visual quality and quantitative metrics.
CFI2P: Coarse-to-Fine Cross-Modal Correspondence Learning for Image-to-Point Cloud Registration
Jul 14, 2023



In the context of image-to-point cloud registration, acquiring point-to-pixel correspondences presents a challenging task since the similarity between individual points and pixels is ambiguous due to the visual differences in data modalities. Nevertheless, the same object present in the two data formats can be readily identified from the local perspective of point sets and pixel patches. Motivated by this intuition, we propose a coarse-to-fine framework that emphasizes the establishment of correspondences between local point sets and pixel patches, followed by the refinement of results at both the point and pixel levels. On a coarse scale, we mimic the classic Visual Transformer to translate both image and point cloud into two sequences of local representations, namely point and pixel proxies, and employ attention to capture global and cross-modal contexts. To supervise the coarse matching, we propose a novel projected point proportion loss, which guides to match point sets with pixel patches where more points can be projected into. On a finer scale, point-to-pixel correspondences are then refined from a smaller search space (i.e., the coarsely matched sets and patches) via well-designed sampling, attentional learning and fine matching, where sampling masks are embedded in the last two steps to mitigate the negative effect of sampling. With the high-quality correspondences, the registration problem is then resolved by EPnP algorithm within RANSAC. Experimental results on large-scale outdoor benchmarks demonstrate our superiority over existing methods.
Deep Domain Adversarial Adaptation for Photon-efficient Imaging Based on Spatiotemporal Inception Network
Jan 07, 2022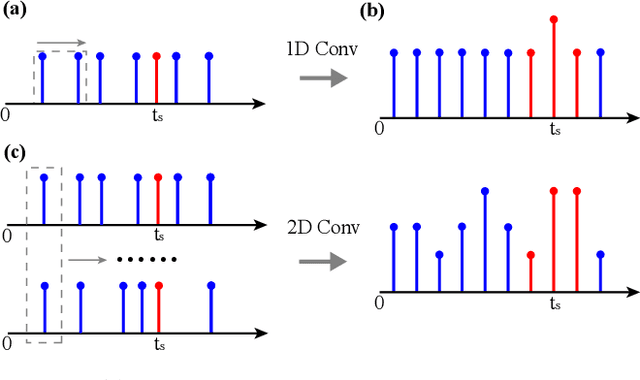
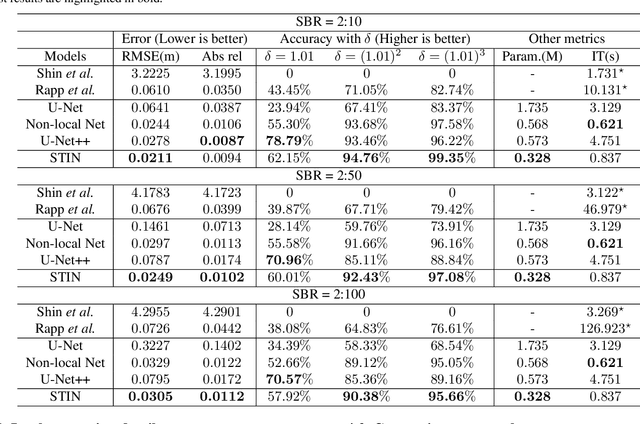
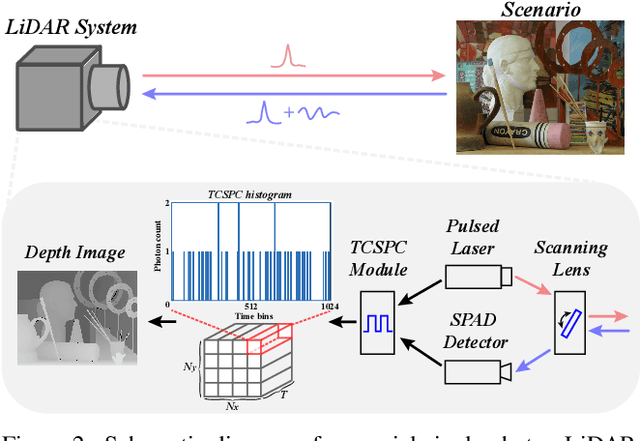
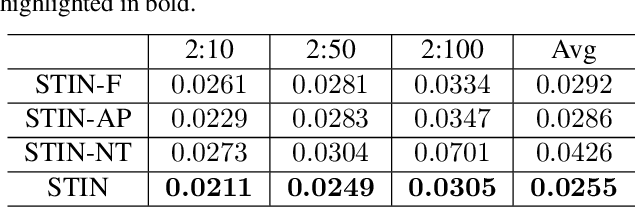
In single-photon LiDAR, photon-efficient imaging captures the 3D structure of a scene by only several detected signal photons per pixel. The existing deep learning models for this task are trained on simulated datasets, which poses the domain shift challenge when applied to realistic scenarios. In this paper, we propose a spatiotemporal inception network (STIN) for photon-efficient imaging, which is able to precisely predict the depth from a sparse and high-noise photon counting histogram by fully exploiting spatial and temporal information. Then the domain adversarial adaptation frameworks, including domain-adversarial neural network and adversarial discriminative domain adaptation, are effectively applied to STIN to alleviate the domain shift problem for realistic applications. Comprehensive experiments on the simulated data generated from the NYU~v2 and the Middlebury datasets demonstrate that STIN outperforms the state-of-the-art models at low signal-to-background ratios from 2:10 to 2:100. Moreover, experimental results on the real-world dataset captured by the single-photon imaging prototype show that the STIN with domain adversarial training achieves better generalization performance compared with the state-of-the-arts as well as the baseline STIN trained by simulated data.
Robust photon-efficient imaging using a pixel-wise residual shrinkage network
Jan 05, 2022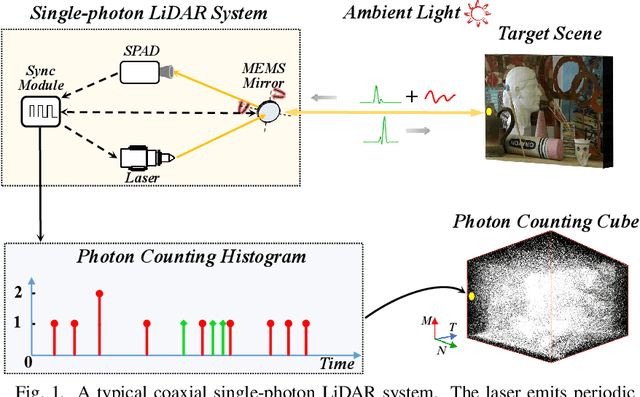
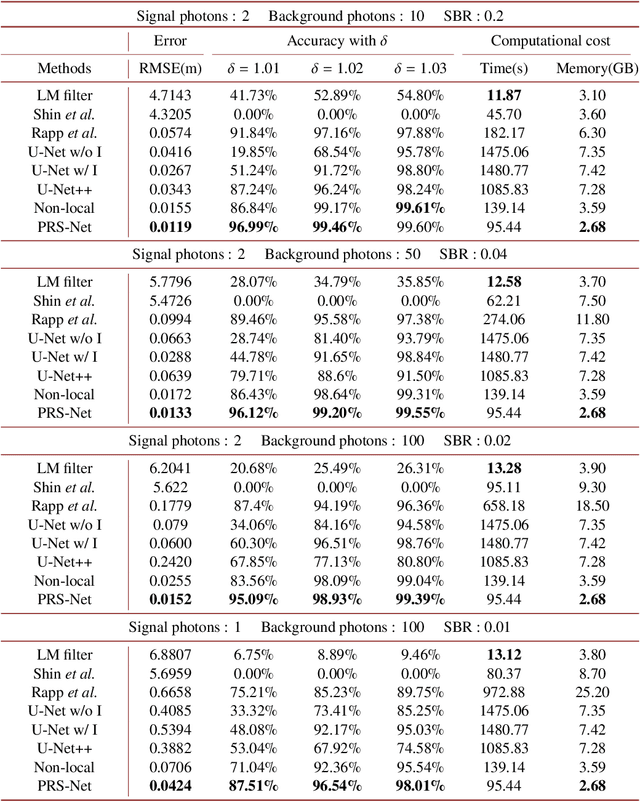

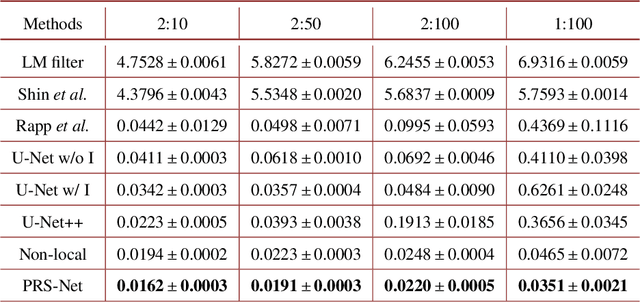
Single-photon light detection and ranging (LiDAR) has been widely applied to 3D imaging in challenging scenarios. However, limited signal photon counts and high noises in the collected data have posed great challenges for predicting the depth image precisely. In this paper, we propose a pixel-wise residual shrinkage network for photon-efficient imaging from high-noise data, which adaptively generates the optimal thresholds for each pixel and denoises the intermediate features by soft thresholding. Besides, redefining the optimization target as pixel-wise classification provides a sharp advantage in producing confident and accurate depth estimation when compared with existing research. Comprehensive experiments conducted on both simulated and real-world datasets demonstrate that the proposed model outperforms the state-of-the-arts and maintains robust imaging performance under different signal-to-noise ratios including the extreme case of 1:100.