 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated SAM for Single-source Domain Generalization in Medical Image Segmentation
Jul 23, 2025Although SAM-based single-source domain generalization models for medical image segmentation can mitigate the impact of domain shift on the model in cross-domain scenarios, these models still face two major challenges. First, the segmentation of SAM is highly dependent on domain-specific expert-annotated prompts, which prevents SAM from achieving fully automated medical image segmentation and therefore limits its application in clinical settings. Second, providing poor prompts (such as bounding boxes that are too small or too large) to the SAM prompt encoder can mislead SAM into generating incorrect mask results. Therefore, we propose the FA-SAM, a single-source domain generalization framework for medical image segmentation that achieves fully automated SAM. FA-SAM introduces two key innovations: an Auto-prompted Generation Model (AGM) branch equipped with a Shallow Feature Uncertainty Modeling (SUFM) module, and an Image-Prompt Embedding Fusion (IPEF) module integrated into the SAM mask decoder. Specifically, AGM models the uncertainty distribution of shallow features through the SUFM module to generate bounding box prompts for the target domain, enabling fully automated segmentation with SAM. The IPEF module integrates multiscale information from SAM image embeddings and prompt embeddings to capture global and local details of the target object, enabling SAM to mitigate the impact of poor prompts. Extensive experiments on publicly available prostate and fundus vessel datasets validate the effectiveness of FA-SAM and highlight its potential to address the above challenges.
Bidirectional Uncertainty-Aware Region Learning for Semi-Supervised Medical Image Segmentation
Feb 11, 2025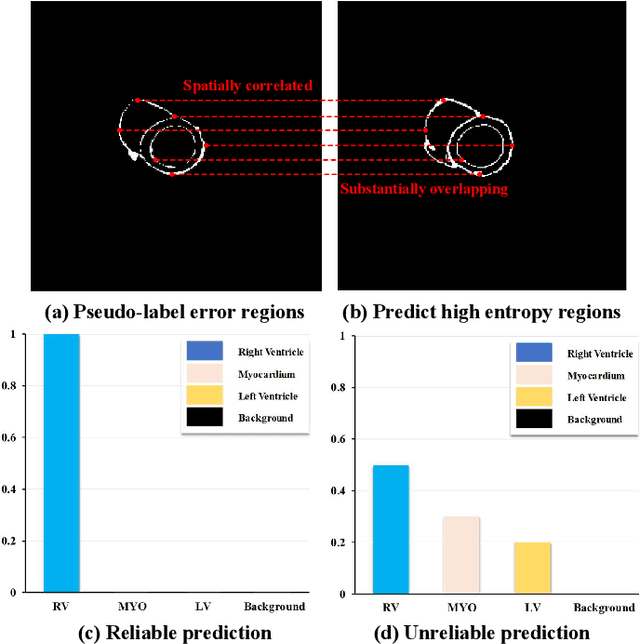
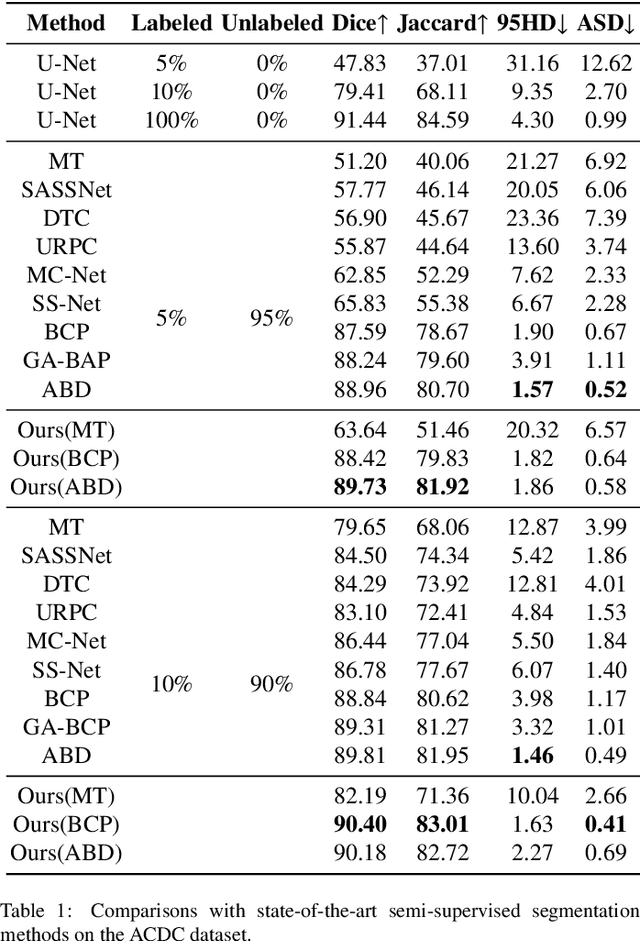
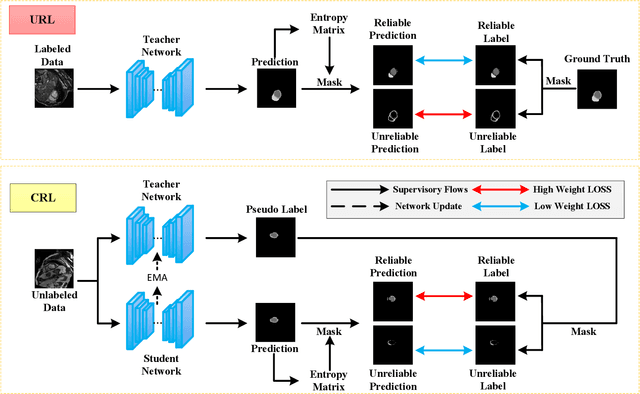
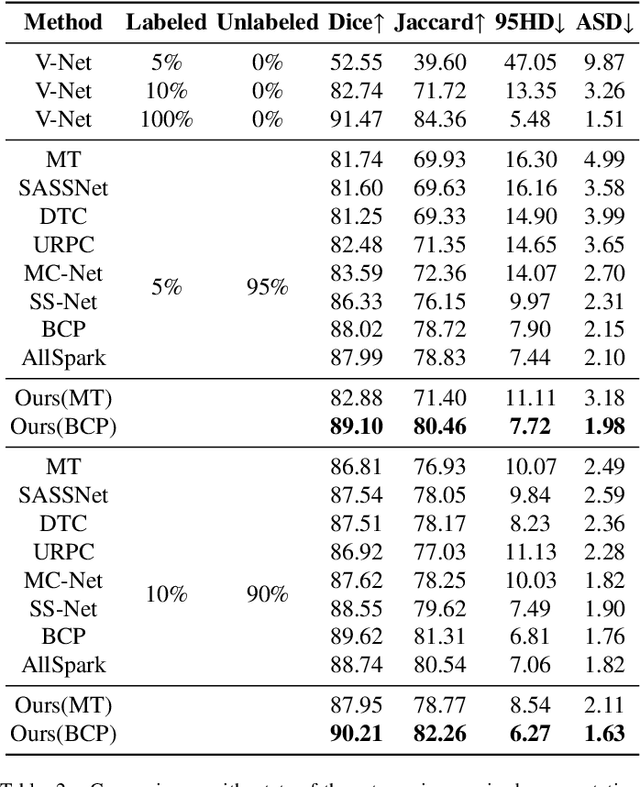
In semi-supervised medical image segmentation, the poor quality of unlabeled data and the uncertainty in the model's predictions lead to models that inevitably produce erroneous pseudo-labels. These errors accumulate throughout model training, thereby weakening the model's performance. We found that these erroneous pseudo-labels are typically concentrated in high-uncertainty regions. Traditional methods improve performance by directly discarding pseudo-labels in these regions, but this can also result in neglecting potentially valuable training data. To alleviate this problem, we propose a bidirectional uncertainty-aware region learning strategy. In training labeled data, we focus on high-uncertainty regions, using precise label information to guide the model's learning in potentially uncontrollable areas. Meanwhile, in the training of unlabeled data, we concentrate on low-uncertainty regions to reduce the interference of erroneous pseudo-labels on the model. Through this bidirectional learning strategy, the model's overall performance has significantly improved. Extensive experiments show that our proposed method achieves significant performance improvement on different medical image segmentation tasks.
FAGhead: Fully Animate Gaussian Head from Monocular Videos
Jun 27, 2024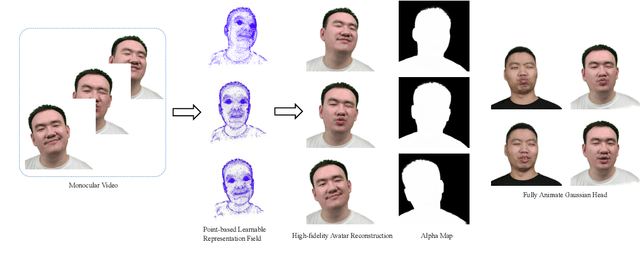
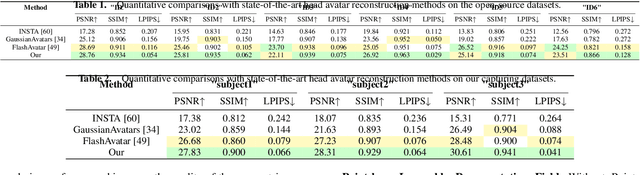
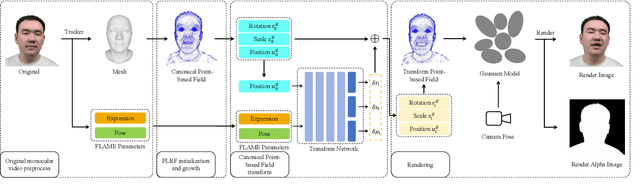
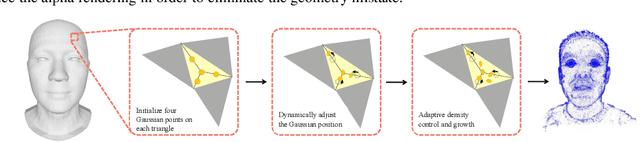
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.