 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAGhead: Fully Animate Gaussian Head from Monocular Videos
Jun 27, 2024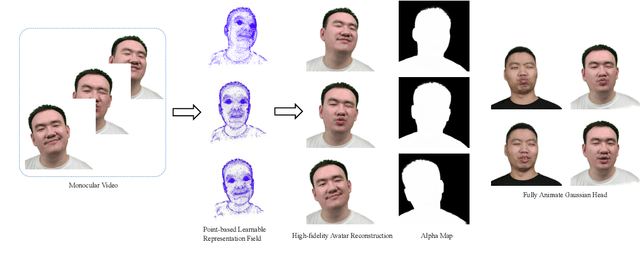
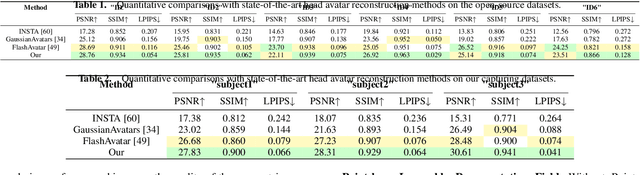
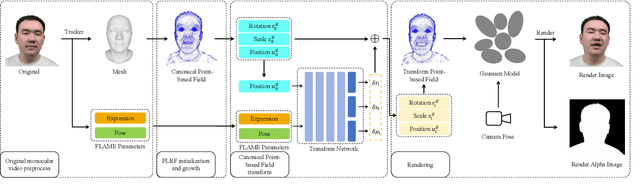
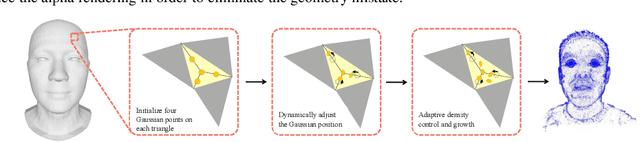
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
Pyramid Embedded Generative Adversarial Network for Automated Font Generation
Nov 20, 2018



In this paper, we investigate the Chinese font synthesis problem and propose a Pyramid Embedded Generative Adversarial Network (PEGAN) to automatically generate Chinese character images. The PEGAN consists of one generator and one discriminator. The generator is built using one encoder-decoder structure with cascaded refinement connections and mirror skip connections. The cascaded refinement connections embed a multiscale pyramid of downsampled original input into the encoder feature maps of different layers, and multi-scale feature maps from the encoder are connected to the corresponding feature maps in the decoder to make the mirror skip connections. Through combining the generative adversarial loss, pixel-wise loss, category loss and perceptual loss, the generator and discriminator can be trained alternately to synthesize character images. In order to verify the effectiveness of our proposed PEGAN, we first build one evaluation set, in which the characters are selected according to their stroke number and frequency of use, and then use both qualitative and quantitative metrics to measure the performance of our model comparing with the baseline method. The experimental results demonstrate the effectiveness of our proposed model, it shows the potential to automatically extend small font banks into complete ones.