 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Visual Place Recognition in LiDAR Maps via Cross-Modal State Space Model and Multi-View Matching
Oct 08, 2024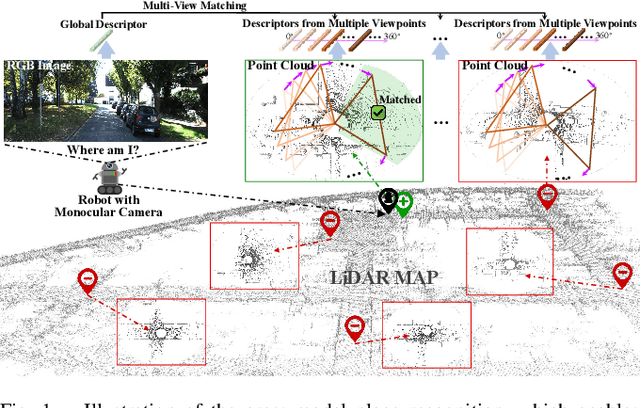
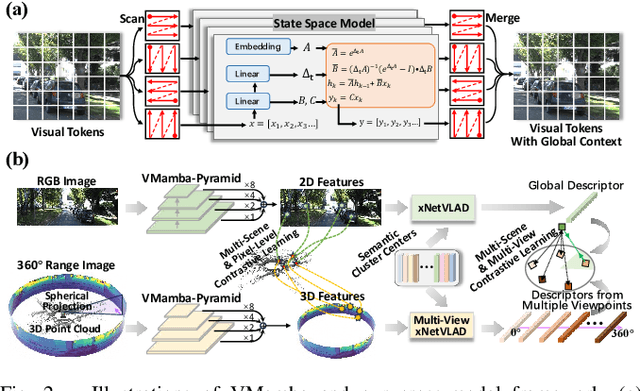
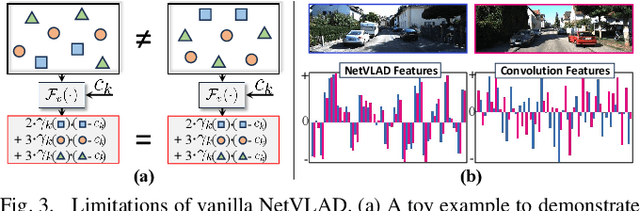
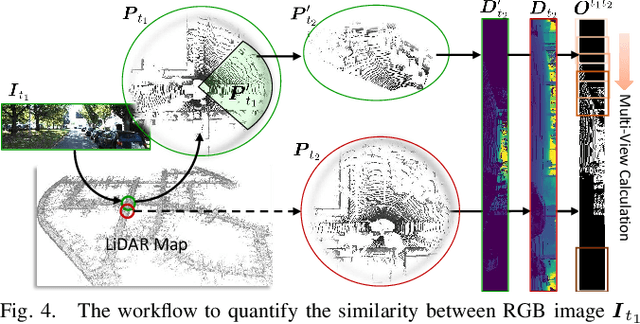
Achieving monocular camera localization within pre-built LiDAR maps can bypass the simultaneous mapping process of visual SLAM systems, potentially reducing the computational overhead of autonomous localization. To this end, one of the key challenges is cross-modal place recognition, which involves retrieving 3D scenes (point clouds) from a LiDAR map according to online RGB images. In this paper, we introduce an efficient framework to learn descriptors for both RGB images and point clouds. It takes visual state space model (VMamba) as the backbone and employs a pixel-view-scene joint training strategy for cross-modal contrastive learning. To address the field-of-view differences, independent descriptors are generated from multiple evenly distributed viewpoints for point clouds. A visible 3D points overlap strategy is then designed to quantify the similarity between point cloud views and RGB images for multi-view supervision. Additionally, when generating descriptors from pixel-level features using NetVLAD, we compensate for the loss of geometric information, and introduce an efficient scheme for multi-view generation. Experimental results on the KITTI and KITTI-360 datasets demonstrate the effectiveness and generalization of our method. The code will be released upon acceptance.