 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless KV Cache Compression to 2%
Paper and Code
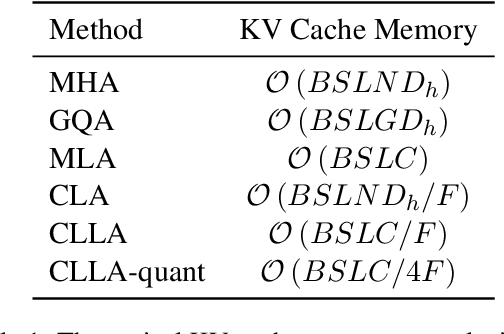
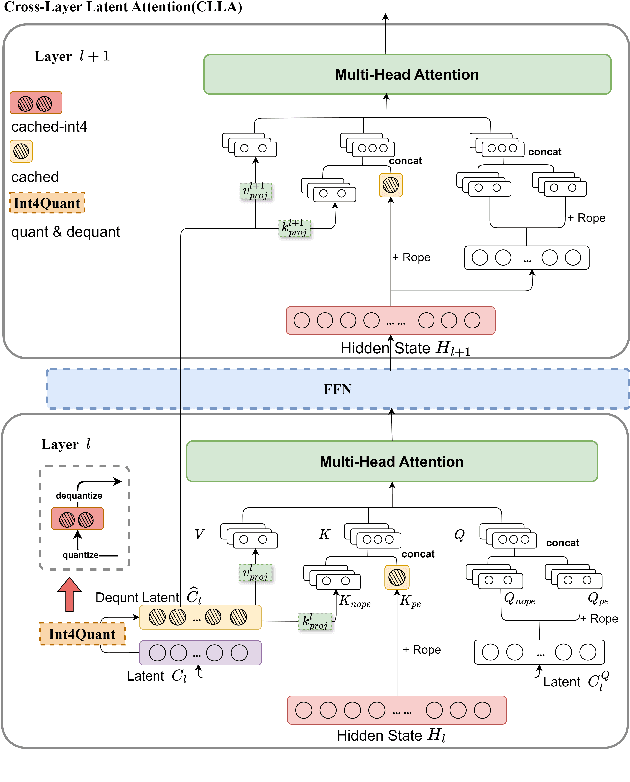
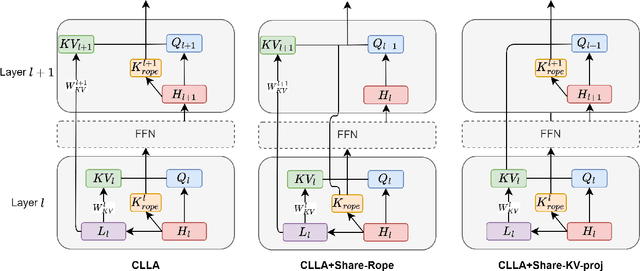
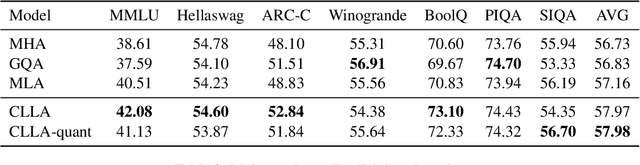
Large language models have revolutionized data processing in numerous domains, with their ability to handle extended context reasoning receiving notable recognition. To speed up inference, maintaining a key-value (KV) cache memory is essential. Nonetheless, the growing demands for KV cache memory create significant hurdles for efficient implementation. This work introduces a novel architecture, Cross-Layer Latent Attention (CLLA), aimed at compressing the KV cache to less than 2% of its original size while maintaining comparable performance levels. CLLA integrates multiple aspects of KV cache compression, including attention head/dimension reduction, layer sharing, and quantization techniques, into a cohesive framework. Our extensive experiments demonstrate that CLLA achieves lossless performance on most tasks while utilizing minimal KV cache, marking a significant advancement in practical KV cache compression.