 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Can Understand Depth
Feb 05, 2024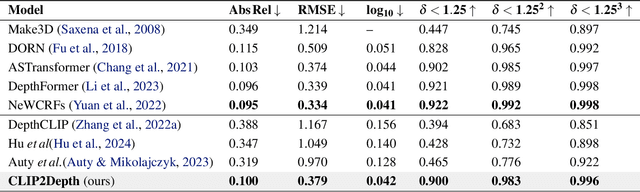
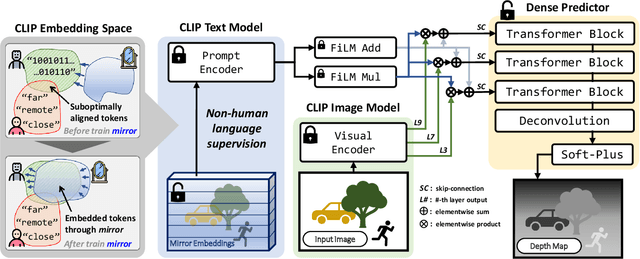
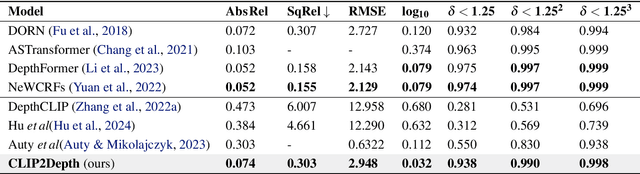

Recent studies on generalizing CLIP for monocular depth estimation reveal that CLIP pre-trained on web-crawled data is inefficient for deriving proper similarities between image patches and depth-related prompts. In this paper, we adapt CLIP for meaningful quality of monocular depth estimation with dense prediction, without fine-tuning its original vision-language alignment. By jointly training a compact deconvolutional decoder with a tiny learnable embedding matrix named mirror, as a static prompt for its text encoder, CLIP is enabled to understand depth. With this approach, our model exhibits impressive performance matching several previous state-of-the-art vision-only models on the NYU Depth v2 and KITTI datasets, outperforming every CLIP-based depth estimation model with a large margin. Experiments on temporal depth consistency and spatial continuity demonstrate that the prior knowledge of CLIP can be effectively refined by our proposed framework. Furthermore, an ablation study on mirror proves that the resulting model estimates depth utilizing knowledge not only from the image encoder but also text encoder despite not being given any prompt written in a human way. This research demonstrates that through minimal adjustments, the prior knowledge of vision-language foundation models, such as CLIP, can be generalized even to domains where learning during pretraining is challenging. We facilitate future works focused on methods to adjust suboptimal prior knowledge of vision-language models using non-human language prompts, achieving performance on par with task-specific state-of-the-art methodologies.
Elementwise Language Representation
Feb 27, 2023



We propose a new technique for computational language representation called elementwise embedding, in which a material (semantic unit) is abstracted into a horizontal concatenation of lower-dimensional element (character) embeddings. While elements are always characters, materials are arbitrary levels of semantic units so it generalizes to any type of tokenization. To focus only on the important letters, the $n^{th}$ spellings of each semantic unit are aligned in $n^{th}$ attention heads, then concatenated back into original forms creating unique embedding representations; they are jointly projected thereby determining own contextual importance. Technically, this framework is achieved by passing a sequence of materials, each consists of $v$ elements, to a transformer having $h=v$ attention heads. As a pure embedding technique, elementwise embedding replaces the $w$-dimensional embedding table of a transformer model with $256$ $c$-dimensional elements (each corresponding to one of UTF-8 bytes) where $c=w/v$. Using this novel approach, we show that the standard transformer architecture can be reused for all levels of language representations and be able to process much longer sequences at the same time-complexity without "any" architectural modification and additional overhead. BERT trained with elementwise embedding outperforms its subword equivalence (original implementation) in multilabel patent document classification exhibiting superior robustness to domain-specificity and data imbalance, despite using $0.005\%$ of embedding parameters. Experiments demonstrate the generalizability of the proposed method by successfully transferring these enhancements to differently architected transformers CANINE and ALBERT.