 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAR: Efficient Large Language Models via Module-aware Architecture Refinement
Jan 29, 2026Large Language Models (LLMs) excel across diverse domains but suffer from high energy costs due to quadratic attention and dense Feed-Forward Network (FFN) operations. To address these issues, we propose Module-aware Architecture Refinement (MAR), a two-stage framework that integrates State Space Models (SSMs) for linear-time sequence modeling and applies activation sparsification to reduce FFN costs. In addition, to mitigate low information density and temporal mismatch in integrating Spiking Neural Networks (SNNs) with SSMs, we design the Adaptive Ternary Multi-step Neuron (ATMN) and the Spike-aware Bidirectional Distillation Strategy (SBDS). Extensive experiments demonstrate that MAR effectively restores the performance of its dense counterpart under constrained resources while substantially reducing inference energy consumption. Furthermore, it outperforms efficient models of comparable or even larger scale, underscoring its potential for building efficient and practical LLMs.
EdgeSync: Faster Edge-model Updating via Adaptive Continuous Learning for Video Data Drift
Jun 05, 2024

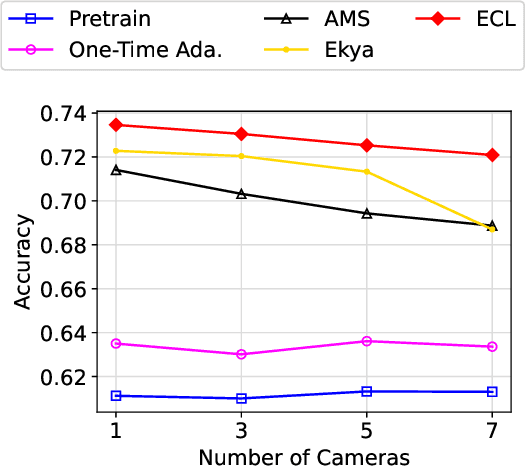

Real-time video analytics systems typically place models with fewer weights on edge devices to reduce latency. The distribution of video content features may change over time for various reasons (i.e. light and weather change) , leading to accuracy degradation of existing models, to solve this problem, recent work proposes a framework that uses a remote server to continually train and adapt the lightweight model at edge with the help of complex model. However, existing analytics approaches leave two challenges untouched: firstly, retraining task is compute-intensive, resulting in large model update delays; secondly, new model may not fit well enough with the data distribution of the current video stream. To address these challenges, in this paper, we present EdgeSync, EdgeSync filters the samples by considering both timeliness and inference results to make training samples more relevant to the current video content as well as reduce the update delay, to improve the quality of training, EdgeSync also designs a training management module that can efficiently adjusts the model training time and training order on the runtime. By evaluating real datasets with complex scenes, our method improves about 3.4% compared to existing methods and about 10% compared to traditional means.
Generative Model-based Feature Knowledge Distillation for Action Recognition
Dec 14, 2023Knowledge distillation (KD), a technique widely employed in computer vision, has emerged as a de facto standard for improving the performance of small neural networks. However, prevailing KD-based approaches in video tasks primarily focus on designing loss functions and fusing cross-modal information. This overlooks the spatial-temporal feature semantics, resulting in limited advancements in model compression. Addressing this gap, our paper introduces an innovative knowledge distillation framework, with the generative model for training a lightweight student model. In particular, the framework is organized into two steps: the initial phase is Feature Representation, wherein a generative model-based attention module is trained to represent feature semantics; Subsequently, the Generative-based Feature Distillation phase encompasses both Generative Distillation and Attention Distillation, with the objective of transferring attention-based feature semantics with the generative model. The efficacy of our approach is demonstrated through comprehensive experiments on diverse popular datasets, proving considerable enhancements in video action recognition task. Moreover, the effectiveness of our proposed framework is validated in the context of more intricate video action detection task. Our code is available at https://github.com/aaai-24/Generative-based-KD.
Weakly-Supervised Action Localization by Hierarchically-structured Latent Attention Modeling
Aug 19, 2023Weakly-supervised action localization aims to recognize and localize action instancese in untrimmed videos with only video-level labels. Most existing models rely on multiple instance learning(MIL), where the predictions of unlabeled instances are supervised by classifying labeled bags. The MIL-based methods are relatively well studied with cogent performance achieved on classification but not on localization. Generally, they locate temporal regions by the video-level classification but overlook the temporal variations of feature semantics. To address this problem, we propose a novel attention-based hierarchically-structured latent model to learn the temporal variations of feature semantics. Specifically, our model entails two components, the first is an unsupervised change-points detection module that detects change-points by learning the latent representations of video features in a temporal hierarchy based on their rates of change, and the second is an attention-based classification model that selects the change-points of the foreground as the boundaries. To evaluate the effectiveness of our model, we conduct extensive experiments on two benchmark datasets, THUMOS-14 and ActivityNet-v1.3. The experiments show that our method outperforms current state-of-the-art methods, and even achieves comparable performance with fully-supervised methods.