 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSRL: Distributed Reinforcement Learning with Dataflow Fragments
Paper and Code
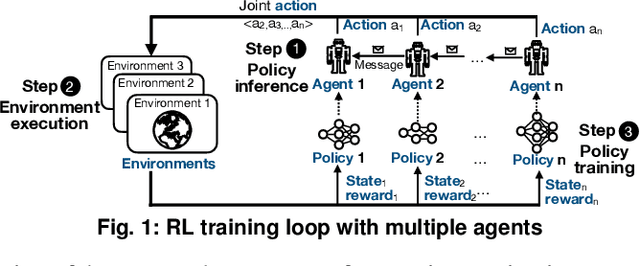
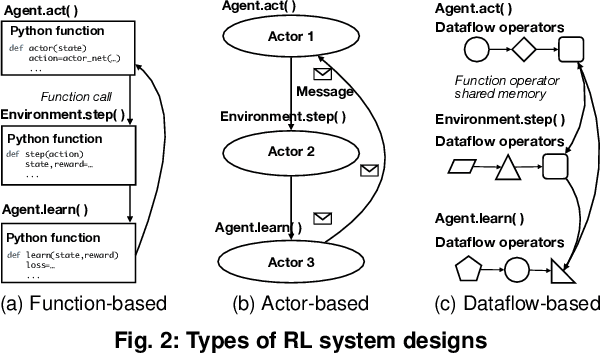
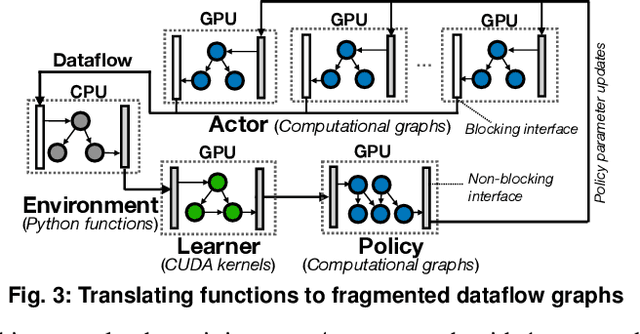
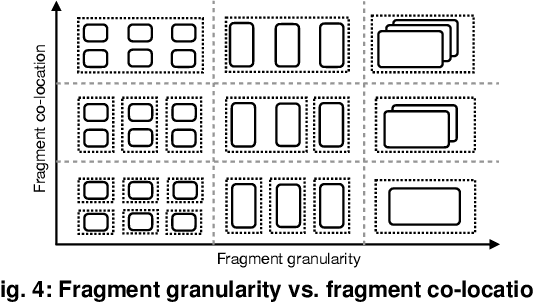
Reinforcement learning~(RL) trains many agents, which is resource-intensive and must scale to large GPU clusters. Different RL training algorithms offer different opportunities for distributing and parallelising the computation. Yet, current distributed RL systems tie the definition of RL algorithms to their distributed execution: they hard-code particular distribution strategies and only accelerate specific parts of the computation (e.g. policy network updates) on GPU workers. Fundamentally, current systems lack abstractions that decouple RL algorithms from their execution. We describe MindSpore Reinforcement Learning (MSRL), a distributed RL training system that supports distribution policies that govern how RL training computation is parallelised and distributed on cluster resources, without requiring changes to the algorithm implementation. MSRL introduces the new abstraction of a fragmented dataflow graph, which maps Python functions from an RL algorithm's training loop to parallel computational fragments. Fragments are executed on different devices by translating them to low-level dataflow representations, e.g. computational graphs as supported by deep learning engines, CUDA implementations or multi-threaded CPU processes. We show that MSRL subsumes the distribution strategies of existing systems, while scaling RL training to 64 GPUs.