 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-assisted Multimodal Sentiment Analysis under Uncertain Missing Modalities
Paper and Code
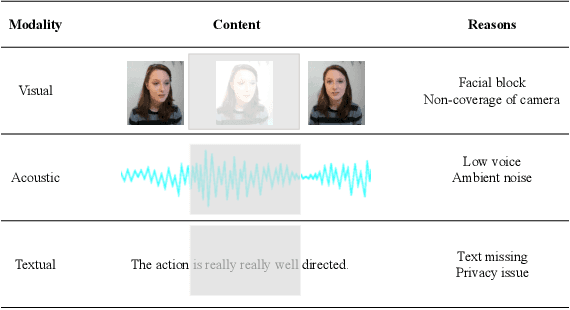


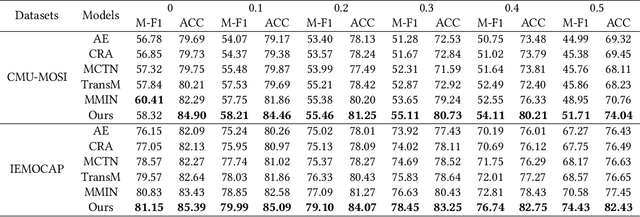
Multimodal sentiment analysis has been studied under the assumption that all modalities are available. However, such a strong assumption does not always hold in practice, and most of multimodal fusion models may fail when partial modalities are missing. Several works have addressed the missing modality problem; but most of them only considered the single modality missing case, and ignored the practically more general cases of multiple modalities missing. To this end, in this paper, we propose a Tag-Assisted Transformer Encoder (TATE) network to handle the problem of missing uncertain modalities. Specifically, we design a tag encoding module to cover both the single modality and multiple modalities missing cases, so as to guide the network's attention to those missing modalities. Besides, we adopt a new space projection pattern to align common vectors. Then, a Transformer encoder-decoder network is utilized to learn the missing modality features. At last, the outputs of the Transformer encoder are used for the final sentiment classification. Extensive experiments are conducted on CMU-MOSI and IEMOCAP datasets, showing that our method can achieve significant improvements compared with several baselines.