 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifAttack++: Query-Efficient Black-Box Adversarial Attack via Hierarchical Disentangled Feature Space in Cross Domain
Paper and Code

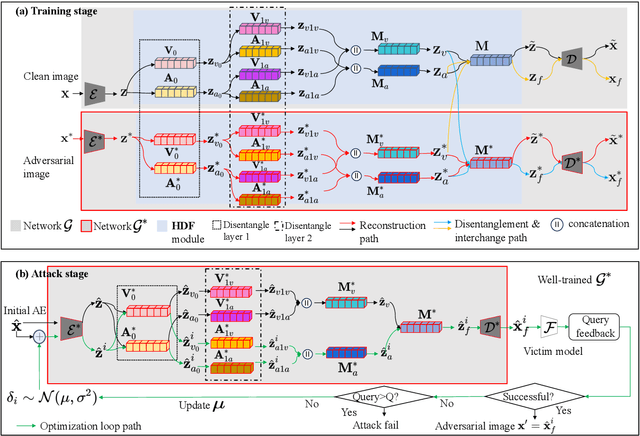


This work investigates efficient score-based black-box adversarial attacks with a high Attack Success Rate (ASR) and good generalizability. We design a novel attack method based on a \textit{Hierarchical} \textbf{Di}sentangled \textbf{F}eature space and \textit{cross domain}, called \textbf{DifAttack++}, which differs significantly from the existing ones operating over the entire feature space. Specifically, DifAttack++ firstly disentangles an image's latent feature into an \textit{adversarial feature} (AF) and a \textit{visual feature} (VF) via an autoencoder equipped with our specially designed \textbf{H}ierarchical \textbf{D}ecouple-\textbf{F}usion (HDF) module, where the AF dominates the adversarial capability of an image, while the VF largely determines its visual appearance. We train such autoencoders for the clean and adversarial image domains respectively, meanwhile realizing feature disentanglement, by using pairs of clean images and their Adversarial Examples (AEs) generated from available surrogate models via white-box attack methods. Eventually, in the black-box attack stage, DifAttack++ iteratively optimizes the AF according to the query feedback from the victim model until a successful AE is generated, while keeping the VF unaltered. Extensive experimental results demonstrate that our method achieves superior ASR and query efficiency than SOTA methods, meanwhile exhibiting much better visual quality of AEs. The code is available at https://github.com/csjunjun/DifAttack.git.