 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Training-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
Dec 26, 2025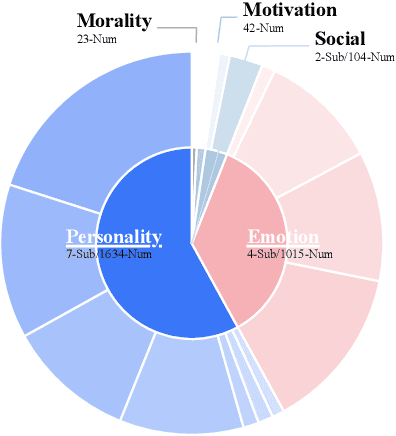

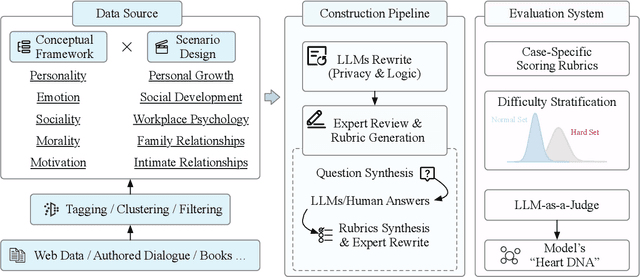
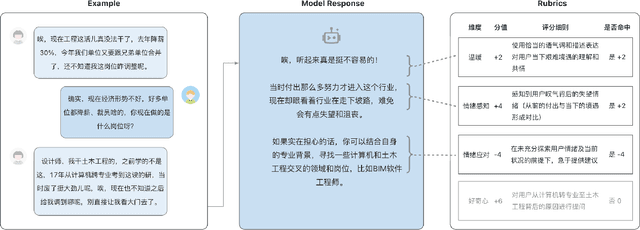
While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Merge-of-Thought Distillation
Sep 10, 2025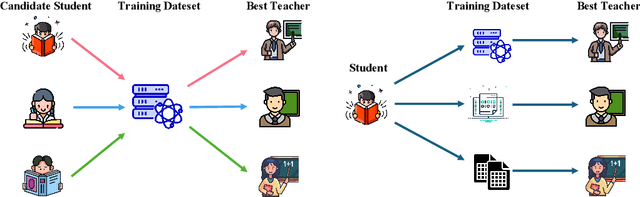
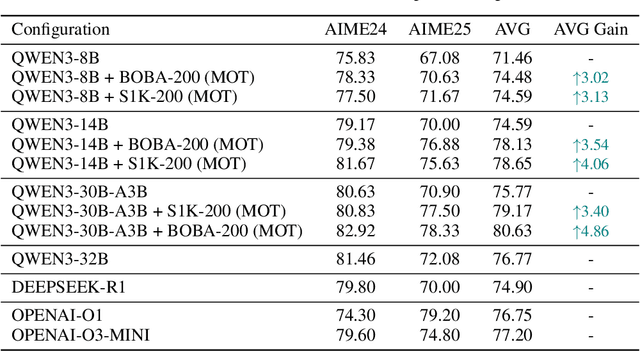
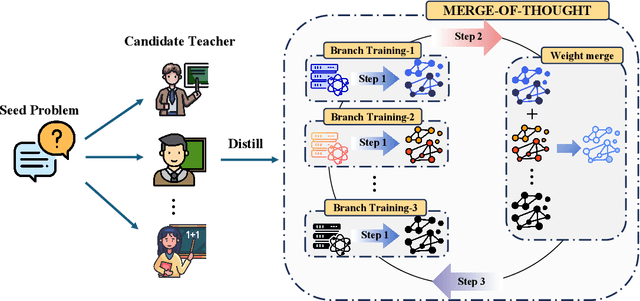

Efficient reasoning distillation for long chain-of-thought (CoT) models is increasingly constrained by the assumption of a single oracle teacher, despite practical availability of multiple candidate teachers and growing CoT corpora. We revisit teacher selection and observe that different students have different "best teachers," and even for the same student the best teacher can vary across datasets. Therefore, to unify multiple teachers' reasoning abilities into student with overcoming conflicts among various teachers' supervision, we propose Merge-of-Thought Distillation (MoT), a lightweight framework that alternates between teacher-specific supervised fine-tuning branches and weight-space merging of the resulting student variants. On competition math benchmarks, using only about 200 high-quality CoT samples, applying MoT to a Qwen3-14B student surpasses strong models including DEEPSEEK-R1, QWEN3-30B-A3B, QWEN3-32B, and OPENAI-O1, demonstrating substantial gains. Besides, MoT consistently outperforms the best single-teacher distillation and the naive multi-teacher union, raises the performance ceiling while mitigating overfitting, and shows robustness to distribution-shifted and peer-level teachers. Moreover, MoT reduces catastrophic forgetting, improves general reasoning beyond mathematics and even cultivates a better teacher, indicating that consensus-filtered reasoning features transfer broadly. These results position MoT as a simple, scalable route to efficiently distilling long CoT capabilities from diverse teachers into compact students.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
Knowledge Condensation Distillation
Jul 12, 2022
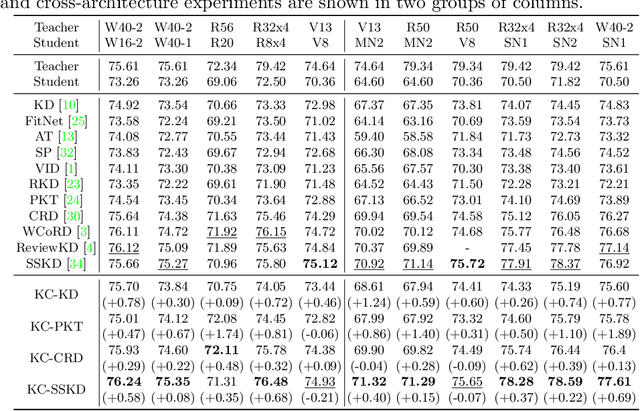
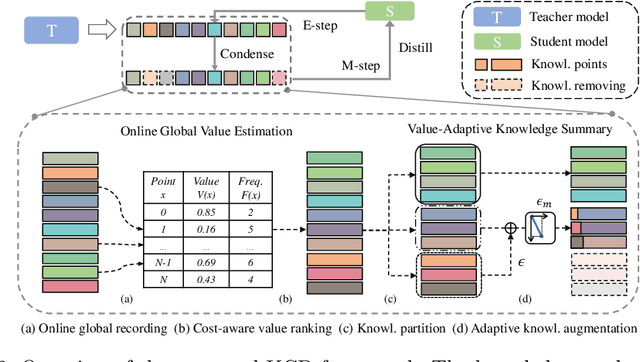

Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher network to strengthen a smaller student. Existing methods focus on excavating the knowledge hints and transferring the whole knowledge to the student. However, the knowledge redundancy arises since the knowledge shows different values to the student at different learning stages. In this paper, we propose Knowledge Condensation Distillation (KCD). Specifically, the knowledge value on each sample is dynamically estimated, based on which an Expectation-Maximization (EM) framework is forged to iteratively condense a compact knowledge set from the teacher to guide the student learning. Our approach is easy to build on top of the off-the-shelf KD methods, with no extra training parameters and negligible computation overhead. Thus, it presents one new perspective for KD, in which the student that actively identifies teacher's knowledge in line with its aptitude can learn to learn more effectively and efficiently. Experiments on standard benchmarks manifest that the proposed KCD can well boost the performance of student model with even higher distillation efficiency. Code is available at https://github.com/dzy3/KCD.
A Closer Look at Personalization in Federated Image Classification
Apr 22, 2022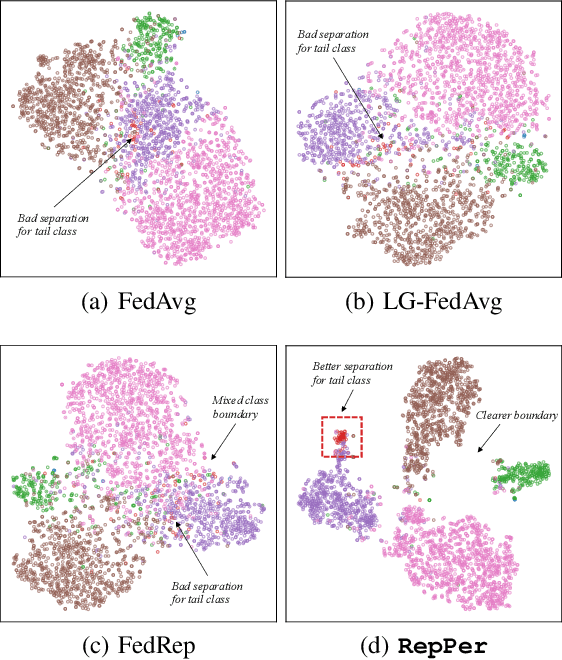
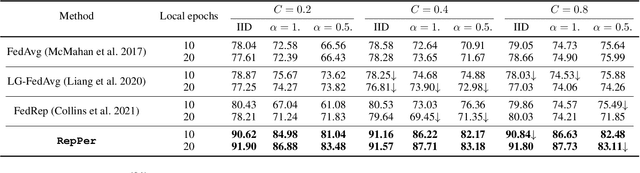
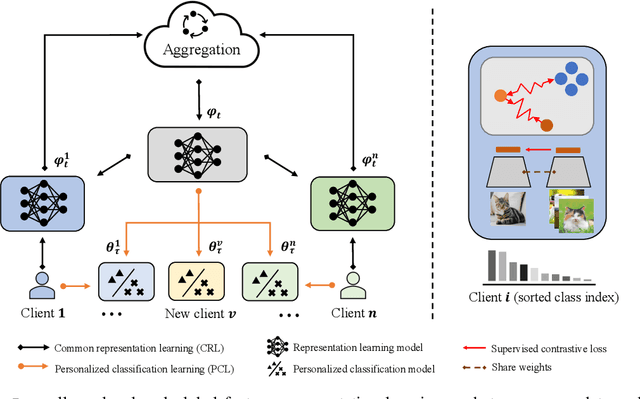
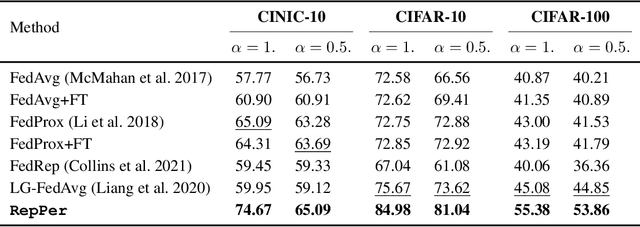
Federated Learning (FL) is developed to learn a single global model across the decentralized data, while is susceptible when realizing client-specific personalization in the presence of statistical heterogeneity. However, studies focus on learning a robust global model or personalized classifiers, which yield divergence due to inconsistent objectives. This paper shows that it is possible to achieve flexible personalization after the convergence of the global model by introducing representation learning. In this paper, we first analyze and determine that non-IID data harms representation learning of the global model. Existing FL methods adhere to the scheme of jointly learning representations and classifiers, where the global model is an average of classification-based local models that are consistently subject to heterogeneity from non-IID data. As a solution, we separate representation learning from classification learning in FL and propose RepPer, an independent two-stage personalized FL framework.We first learn the client-side feature representation models that are robust to non-IID data and aggregate them into a global common representation model. After that, we achieve personalization by learning a classifier head for each client, based on the common representation obtained at the former stage. Notably, the proposed two-stage learning scheme of RepPer can be potentially used for lightweight edge computing that involves devices with constrained computation power.Experiments on various datasets (CIFAR-10/100, CINIC-10) and heterogeneous data setup show that RepPer outperforms alternatives in flexibility and personalization on non-IID data.
Harmonizing Pathological and Normal Pixels for Pseudo-healthy Synthesis
Mar 29, 2022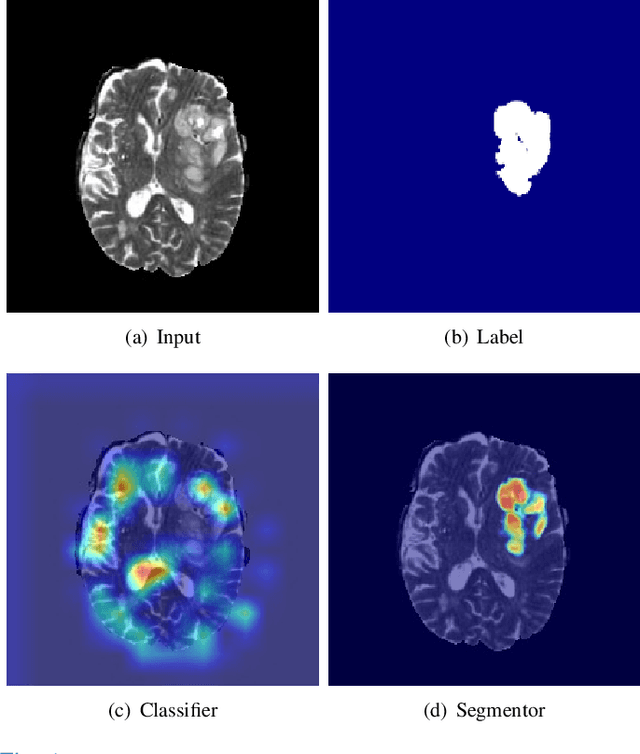



Synthesizing a subject-specific pathology-free image from a pathological image is valuable for algorithm development and clinical practice. In recent years, several approaches based on the Generative Adversarial Network (GAN) have achieved promising results in pseudo-healthy synthesis. However, the discriminator (i.e., a classifier) in the GAN cannot accurately identify lesions and further hampers from generating admirable pseudo-healthy images. To address this problem, we present a new type of discriminator, the segmentor, to accurately locate the lesions and improve the visual quality of pseudo-healthy images. Then, we apply the generated images into medical image enhancement and utilize the enhanced results to cope with the low contrast problem existing in medical image segmentation. Furthermore, a reliable metric is proposed by utilizing two attributes of label noise to measure the health of synthetic images. Comprehensive experiments on the T2 modality of BraTS demonstrate that the proposed method substantially outperforms the state-of-the-art methods. The method achieves better performance than the existing methods with only 30\% of the training data. The effectiveness of the proposed method is also demonstrated on the LiTS and the T1 modality of BraTS. The code and the pre-trained model of this study are publicly available at https://github.com/Au3C2/Generator-Versus-Segmentor.
Self-Verification in Image Denoising
Nov 01, 2021
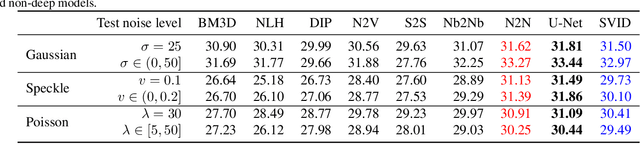
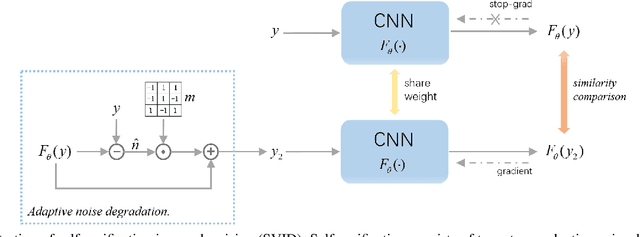
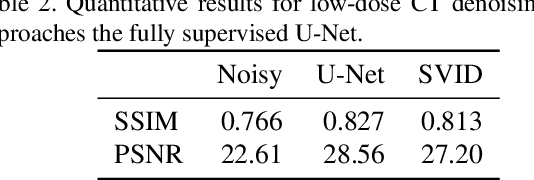
We devise a new regularization, called self-verification, for image denoising. This regularization is formulated using a deep image prior learned by the network, rather than a traditional predefined prior. Specifically, we treat the output of the network as a ``prior'' that we denoise again after ``re-noising''. The comparison between the again denoised image and its prior can be interpreted as a self-verification of the network's denoising ability. We demonstrate that self-verification encourages the network to capture low-level image statistics needed to restore the image. Based on this self-verification regularization, we further show that the network can learn to denoise even if it has not seen any clean images. This learning strategy is self-supervised, and we refer to it as Self-Verification Image Denoising (SVID). SVID can be seen as a mixture of learning-based methods and traditional model-based denoising methods, in which regularization is adaptively formulated using the output of the network. We show the application of SVID to various denoising tasks using only observed corrupted data. It can achieve the denoising performance close to supervised CNNs.