 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Personalization in Federated Image Classification
Apr 22, 2022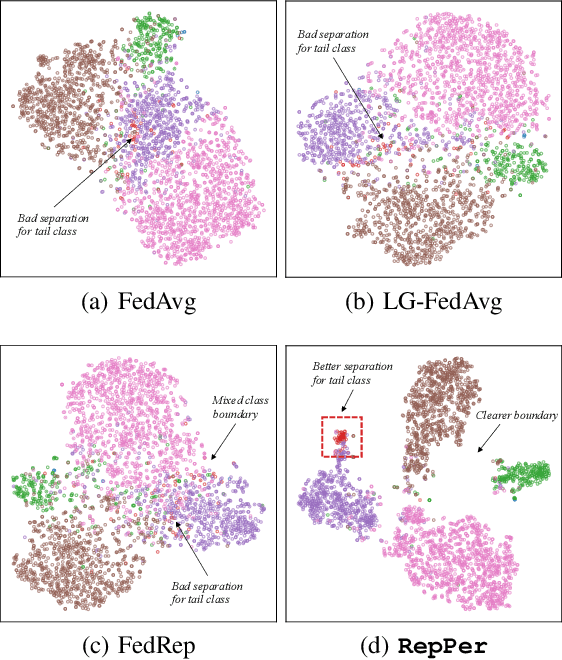
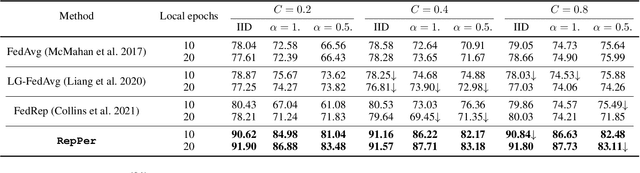
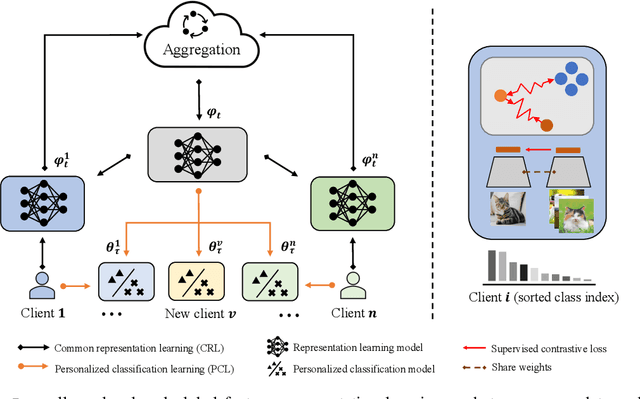
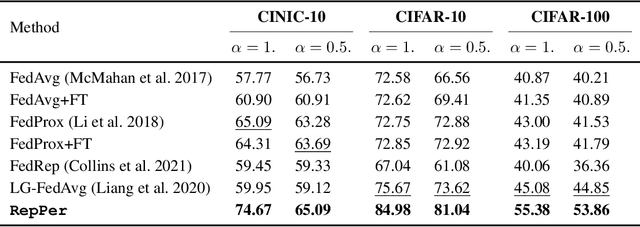
Federated Learning (FL) is developed to learn a single global model across the decentralized data, while is susceptible when realizing client-specific personalization in the presence of statistical heterogeneity. However, studies focus on learning a robust global model or personalized classifiers, which yield divergence due to inconsistent objectives. This paper shows that it is possible to achieve flexible personalization after the convergence of the global model by introducing representation learning. In this paper, we first analyze and determine that non-IID data harms representation learning of the global model. Existing FL methods adhere to the scheme of jointly learning representations and classifiers, where the global model is an average of classification-based local models that are consistently subject to heterogeneity from non-IID data. As a solution, we separate representation learning from classification learning in FL and propose RepPer, an independent two-stage personalized FL framework.We first learn the client-side feature representation models that are robust to non-IID data and aggregate them into a global common representation model. After that, we achieve personalization by learning a classifier head for each client, based on the common representation obtained at the former stage. Notably, the proposed two-stage learning scheme of RepPer can be potentially used for lightweight edge computing that involves devices with constrained computation power.Experiments on various datasets (CIFAR-10/100, CINIC-10) and heterogeneous data setup show that RepPer outperforms alternatives in flexibility and personalization on non-IID data.
A^2Net: Adjacent Aggregation Networks for Image Raindrop Removal
Nov 24, 2018

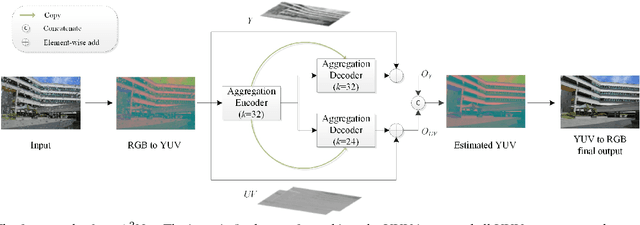

Existing methods for single images raindrop removal either have poor robustness or suffer from parameter burdens. In this paper, we propose a new Adjacent Aggregation Network (A^2Net) with lightweight architectures to remove raindrops from single images. Instead of directly cascading convolutional layers, we design an adjacent aggregation architecture to better fuse features for rich representations generation, which can lead to high quality images reconstruction. To further simplify the learning process, we utilize a problem-specific knowledge to force the network focus on the luminance channel in the YUV color space instead of all RGB channels. By combining adjacent aggregating operation with color space transformation, the proposed A^2Net can achieve state-of-the-art performances on raindrop removal with significant parameters reduction.