 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient-Specific Autoregressive Models for Organ Motion Prediction in Radiotherapy
May 17, 2025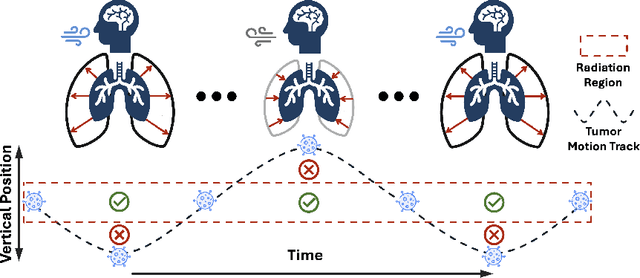
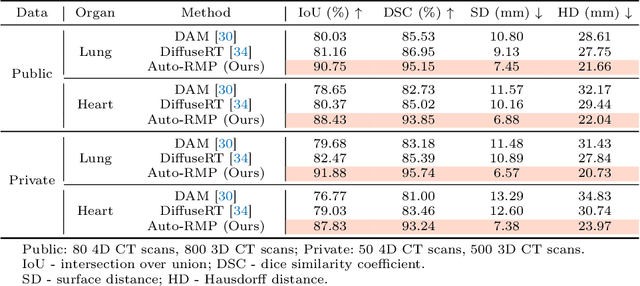
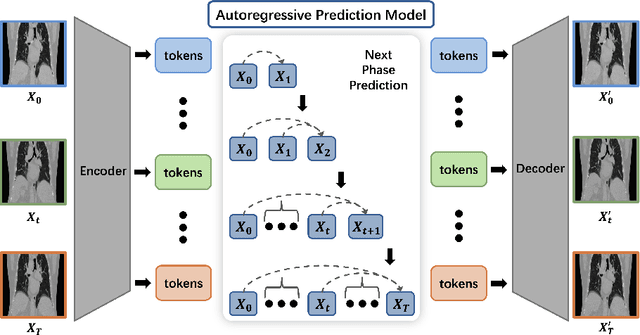
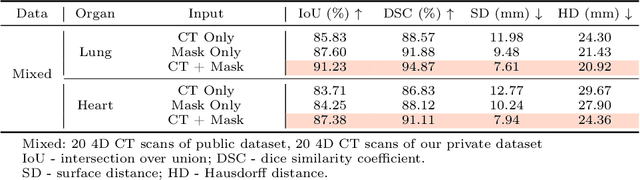
Radiotherapy often involves a prolonged treatment period. During this time, patients may experience organ motion due to breathing and other physiological factors. Predicting and modeling this motion before treatment is crucial for ensuring precise radiation delivery. However, existing pre-treatment organ motion prediction methods primarily rely on deformation analysis using principal component analysis (PCA), which is highly dependent on registration quality and struggles to capture periodic temporal dynamics for motion modeling.In this paper, we observe that organ motion prediction closely resembles an autoregressive process, a technique widely used in natural language processing (NLP). Autoregressive models predict the next token based on previous inputs, naturally aligning with our objective of predicting future organ motion phases. Building on this insight, we reformulate organ motion prediction as an autoregressive process to better capture patient-specific motion patterns. Specifically, we acquire 4D CT scans for each patient before treatment, with each sequence comprising multiple 3D CT phases. These phases are fed into the autoregressive model to predict future phases based on prior phase motion patterns. We evaluate our method on a real-world test set of 4D CT scans from 50 patients who underwent radiotherapy at our institution and a public dataset containing 4D CT scans from 20 patients (some with multiple scans), totaling over 1,300 3D CT phases. The performance in predicting the motion of the lung and heart surpasses existing benchmarks, demonstrating its effectiveness in capturing motion dynamics from CT images. These results highlight the potential of our method to improve pre-treatment planning in radiotherapy, enabling more precise and adaptive radiation delivery.
COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations
Dec 22, 2024



This study presents a data-driven analysis of COVID-19 discourse on YouTube, examining the sentiment, toxicity, and thematic patterns of video content published between January 2023 and October 2024. The analysis involved applying advanced natural language processing (NLP) techniques: sentiment analysis with VADER, toxicity detection with Detoxify, and topic modeling using Latent Dirichlet Allocation (LDA). The sentiment analysis revealed that 49.32% of video descriptions were positive, 36.63% were neutral, and 14.05% were negative, indicating a generally informative and supportive tone in pandemic-related content. Toxicity analysis identified only 0.91% of content as toxic, suggesting minimal exposure to toxic content. Topic modeling revealed two main themes, with 66.74% of the videos covering general health information and pandemic-related impacts and 33.26% focused on news and real-time updates, highlighting the dual informational role of YouTube. A recommendation system was also developed using TF-IDF vectorization and cosine similarity, refined by sentiment, toxicity, and topic filters to ensure relevant and context-aligned video recommendations. This system achieved 69% aggregate coverage, with monthly coverage rates consistently above 85%, demonstrating robust performance and adaptability over time. Evaluation across recommendation sizes showed coverage reaching 69% for five video recommendations and 79% for ten video recommendations per video. In summary, this work presents a framework for understanding COVID-19 discourse on YouTube and a recommendation system that supports user engagement while promoting responsible and relevant content related to COVID-19.
A Labelled Dataset for Sentiment Analysis of Videos on YouTube, TikTok, and Other Sources about the 2024 Outbreak of Measles
Jun 11, 2024



The work of this paper presents a dataset that contains the data of 4011 videos about the ongoing outbreak of measles published on 264 websites on the internet between January 1, 2024, and May 31, 2024. The dataset is available at https://dx.doi.org/10.21227/40s8-xf63. These websites primarily include YouTube and TikTok, which account for 48.6% and 15.2% of the videos, respectively. The remainder of the websites include Instagram and Facebook as well as the websites of various global and local news organizations. For each of these videos, the URL of the video, title of the post, description of the post, and the date of publication of the video are presented as separate attributes in the dataset. After developing this dataset, sentiment analysis (using VADER), subjectivity analysis (using TextBlob), and fine-grain sentiment analysis (using DistilRoBERTa-base) of the video titles and video descriptions were performed. This included classifying each video title and video description into (i) one of the sentiment classes i.e. positive, negative, or neutral, (ii) one of the subjectivity classes i.e. highly opinionated, neutral opinionated, or least opinionated, and (iii) one of the fine-grain sentiment classes i.e. fear, surprise, joy, sadness, anger, disgust, or neutral. These results are presented as separate attributes in the dataset for the training and testing of machine learning algorithms for performing sentiment analysis or subjectivity analysis in this field as well as for other applications. Finally, this paper also presents a list of open research questions that may be investigated using this dataset.