 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Classification of Studies Investigating Social Media Conversations about Long COVID Using a Novel Zero-Shot Transformer Framework
Mar 14, 2025Long COVID continues to challenge public health by affecting a considerable number of individuals who have recovered from acute SARS-CoV-2 infection yet endure prolonged and often debilitating symptoms. Social media has emerged as a vital resource for those seeking real-time information, peer support, and validating their health concerns related to Long COVID. This paper examines recent works focusing on mining, analyzing, and interpreting user-generated content on social media platforms to capture the broader discourse on persistent post-COVID conditions. A novel transformer-based zero-shot learning approach serves as the foundation for classifying research papers in this area into four primary categories: Clinical or Symptom Characterization, Advanced NLP or Computational Methods, Policy Advocacy or Public Health Communication, and Online Communities and Social Support. This methodology achieved an average confidence of 0.7788, with the minimum and maximum confidence being 0.1566 and 0.9928, respectively. This model showcases the ability of advanced language models to categorize research papers without any training data or predefined classification labels, thus enabling a more rapid and scalable assessment of existing literature. This paper also highlights the multifaceted nature of Long COVID research by demonstrating how advanced computational techniques applied to social media conversations can reveal deeper insights into the experiences, symptoms, and narratives of individuals affected by Long COVID.
Emoji Retrieval from Gibberish or Garbled Social Media Text: A Novel Methodology and A Case Study
Dec 23, 2024Emojis are widely used across social media platforms but are often lost in noisy or garbled text, posing challenges for data analysis and machine learning. Conventional preprocessing approaches recommend removing such text, risking the loss of emojis and their contextual meaning. This paper proposes a three-step reverse-engineering methodology to retrieve emojis from garbled text in social media posts. The methodology also identifies reasons for the generation of such text during social media data mining. To evaluate its effectiveness, the approach was applied to 509,248 Tweets about the Mpox outbreak, a dataset referenced in about 30 prior works that failed to retrieve emojis from garbled text. Our method retrieved 157,748 emojis from 76,914 Tweets. Improvements in text readability and coherence were demonstrated through metrics such as Flesch Reading Ease, Flesch-Kincaid Grade Level, Coleman-Liau Index, Automated Readability Index, Dale-Chall Readability Score, Text Standard, and Reading Time. Additionally, the frequency of individual emojis and their patterns of usage in these Tweets were analyzed, and the results are presented.
Quantifying Public Response to COVID-19 Events: Introducing the Community Sentiment and Engagement Index
Dec 22, 2024
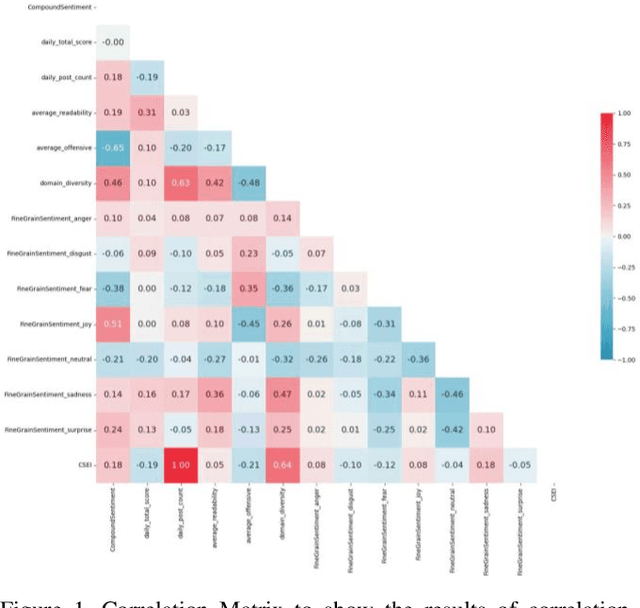
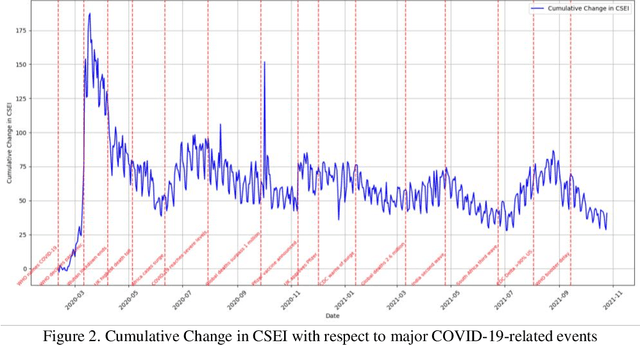
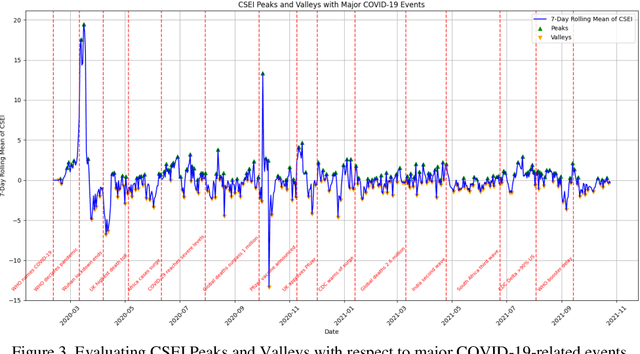
This study introduces the Community Sentiment and Engagement Index (CSEI), developed to capture nuanced public sentiment and engagement variations on social media, particularly in response to major events related to COVID-19. Constructed with diverse sentiment indicators, CSEI integrates features like engagement, daily post count, compound sentiment, fine-grain sentiments (fear, surprise, joy, sadness, anger, disgust, and neutral), readability, offensiveness, and domain diversity. Each component is systematically weighted through a multi-step Principal Component Analysis (PCA)-based framework, prioritizing features according to their variance contributions across temporal sentiment shifts. This approach dynamically adjusts component importance, enabling CSEI to precisely capture high-sensitivity shifts in public sentiment. The development of CSEI showed statistically significant correlations with its constituent features, underscoring internal consistency and sensitivity to specific sentiment dimensions. CSEI's responsiveness was validated using a dataset of 4,510,178 Reddit posts about COVID-19. The analysis focused on 15 major events, including the WHO's declaration of COVID-19 as a pandemic, the first reported cases of COVID-19 across different countries, national lockdowns, vaccine developments, and crucial public health measures. Cumulative changes in CSEI revealed prominent peaks and valleys aligned with these events, indicating significant patterns in public sentiment across different phases of the pandemic. Pearson correlation analysis further confirmed a statistically significant relationship between CSEI daily fluctuations and these events (p = 0.0428), highlighting the capacity of CSEI to infer and interpret shifts in public sentiment and engagement in response to major events related to COVID-19.
COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations
Dec 22, 2024



This study presents a data-driven analysis of COVID-19 discourse on YouTube, examining the sentiment, toxicity, and thematic patterns of video content published between January 2023 and October 2024. The analysis involved applying advanced natural language processing (NLP) techniques: sentiment analysis with VADER, toxicity detection with Detoxify, and topic modeling using Latent Dirichlet Allocation (LDA). The sentiment analysis revealed that 49.32% of video descriptions were positive, 36.63% were neutral, and 14.05% were negative, indicating a generally informative and supportive tone in pandemic-related content. Toxicity analysis identified only 0.91% of content as toxic, suggesting minimal exposure to toxic content. Topic modeling revealed two main themes, with 66.74% of the videos covering general health information and pandemic-related impacts and 33.26% focused on news and real-time updates, highlighting the dual informational role of YouTube. A recommendation system was also developed using TF-IDF vectorization and cosine similarity, refined by sentiment, toxicity, and topic filters to ensure relevant and context-aligned video recommendations. This system achieved 69% aggregate coverage, with monthly coverage rates consistently above 85%, demonstrating robust performance and adaptability over time. Evaluation across recommendation sizes showed coverage reaching 69% for five video recommendations and 79% for ten video recommendations per video. In summary, this work presents a framework for understanding COVID-19 discourse on YouTube and a recommendation system that supports user engagement while promoting responsible and relevant content related to COVID-19.
Five Years of COVID-19 Discourse on Instagram: A Labeled Instagram Dataset of Over Half a Million Posts for Multilingual Sentiment Analysis
Oct 04, 2024The work presented in this paper makes three scientific contributions with a specific focus on mining and analysis of COVID-19-related posts on Instagram. First, it presents a multilingual dataset of 500,153 Instagram posts about COVID-19 published between January 2020 and September 2024. This dataset, available at https://dx.doi.org/10.21227/d46p-v480, contains Instagram posts in 161 different languages as well as 535,021 distinct hashtags. After the development of this dataset, multilingual sentiment analysis was performed, which involved classifying each post as positive, negative, or neutral. The results of sentiment analysis are presented as a separate attribute in this dataset. Second, it presents the results of performing sentiment analysis per year from 2020 to 2024. The findings revealed the trends in sentiment related to COVID-19 on Instagram since the beginning of the pandemic. For instance, between 2020 and 2024, the sentiment trends show a notable shift, with positive sentiment decreasing from 38.35% to 28.69%, while neutral sentiment rising from 44.19% to 58.34%. Finally, the paper also presents findings of language-specific sentiment analysis. This analysis highlighted similar and contrasting trends of sentiment across posts published in different languages on Instagram. For instance, out of all English posts, 49.68% were positive, 14.84% were negative, and 35.48% were neutral. In contrast, among Hindi posts, 4.40% were positive, 57.04% were negative, and 38.56% were neutral, reflecting distinct differences in the sentiment distribution between these two languages.
Mpox Narrative on Instagram: A Labeled Multilingual Dataset of Instagram Posts on Mpox for Sentiment, Hate Speech, and Anxiety Analysis
Sep 10, 2024The world is currently experiencing an outbreak of mpox, which has been declared a Public Health Emergency of International Concern by WHO. No prior work related to social media mining has focused on the development of a dataset of Instagram posts about the mpox outbreak. The work presented in this paper aims to address this research gap and makes two scientific contributions to this field. First, it presents a multilingual dataset of 60,127 Instagram posts about mpox, published between July 23, 2022, and September 5, 2024. The dataset, available at https://dx.doi.org/10.21227/7fvc-y093, contains Instagram posts about mpox in 52 languages. For each of these posts, the Post ID, Post Description, Date of publication, language, and translated version of the post (translation to English was performed using the Google Translate API) are presented as separate attributes in the dataset. After developing this dataset, sentiment analysis, hate speech detection, and anxiety or stress detection were performed. This process included classifying each post into (i) one of the sentiment classes, i.e., fear, surprise, joy, sadness, anger, disgust, or neutral, (ii) hate or not hate, and (iii) anxiety/stress detected or no anxiety/stress detected. These results are presented as separate attributes in the dataset. Second, this paper presents the results of performing sentiment analysis, hate speech analysis, and anxiety or stress analysis. The variation of the sentiment classes - fear, surprise, joy, sadness, anger, disgust, and neutral were observed to be 27.95%, 2.57%, 8.69%, 5.94%, 2.69%, 1.53%, and 50.64%, respectively. In terms of hate speech detection, 95.75% of the posts did not contain hate and the remaining 4.25% of the posts contained hate. Finally, 72.05% of the posts did not indicate any anxiety/stress, and the remaining 27.95% of the posts represented some form of anxiety/stress.
A Labelled Dataset for Sentiment Analysis of Videos on YouTube, TikTok, and Other Sources about the 2024 Outbreak of Measles
Jun 11, 2024



The work of this paper presents a dataset that contains the data of 4011 videos about the ongoing outbreak of measles published on 264 websites on the internet between January 1, 2024, and May 31, 2024. The dataset is available at https://dx.doi.org/10.21227/40s8-xf63. These websites primarily include YouTube and TikTok, which account for 48.6% and 15.2% of the videos, respectively. The remainder of the websites include Instagram and Facebook as well as the websites of various global and local news organizations. For each of these videos, the URL of the video, title of the post, description of the post, and the date of publication of the video are presented as separate attributes in the dataset. After developing this dataset, sentiment analysis (using VADER), subjectivity analysis (using TextBlob), and fine-grain sentiment analysis (using DistilRoBERTa-base) of the video titles and video descriptions were performed. This included classifying each video title and video description into (i) one of the sentiment classes i.e. positive, negative, or neutral, (ii) one of the subjectivity classes i.e. highly opinionated, neutral opinionated, or least opinionated, and (iii) one of the fine-grain sentiment classes i.e. fear, surprise, joy, sadness, anger, disgust, or neutral. These results are presented as separate attributes in the dataset for the training and testing of machine learning algorithms for performing sentiment analysis or subjectivity analysis in this field as well as for other applications. Finally, this paper also presents a list of open research questions that may be investigated using this dataset.
Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets
Dec 19, 2023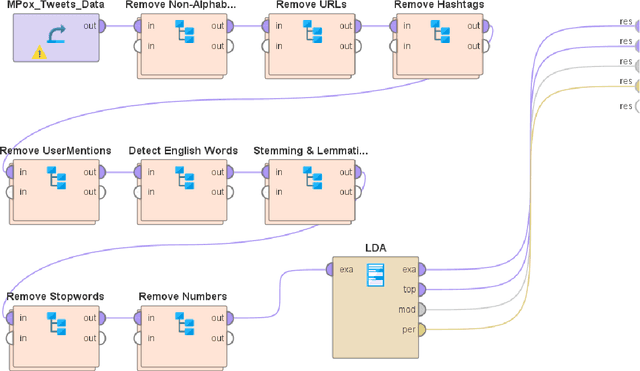

The recent outbreak of the MPox virus has resulted in a tremendous increase in the usage of Twitter. Prior works in this area of research have primarily focused on the sentiment analysis and content analysis of these Tweets, and the few works that have focused on topic modeling have multiple limitations. This paper aims to address this research gap and makes two scientific contributions to this field. First, it presents the results of performing Topic Modeling on 601,432 Tweets about the 2022 Mpox outbreak that were posted on Twitter between 7 May 2022 and 3 March 2023. The results indicate that the conversations on Twitter related to Mpox during this time range may be broadly categorized into four distinct themes - Views and Perspectives about Mpox, Updates on Cases and Investigations about Mpox, Mpox and the LGBTQIA+ Community, and Mpox and COVID-19. Second, the paper presents the findings from the analysis of these Tweets. The results show that the theme that was most popular on Twitter (in terms of the number of Tweets posted) during this time range was Views and Perspectives about Mpox. This was followed by the theme of Mpox and the LGBTQIA+ Community, which was followed by the themes of Mpox and COVID-19 and Updates on Cases and Investigations about Mpox, respectively. Finally, a comparison with related studies in this area of research is also presented to highlight the novelty and significance of this research work.
Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox
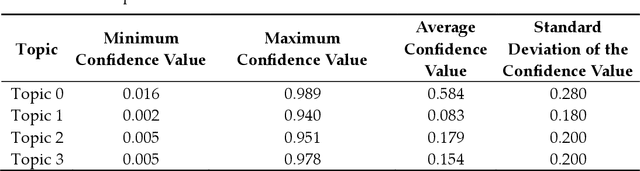
Dec 17, 2023
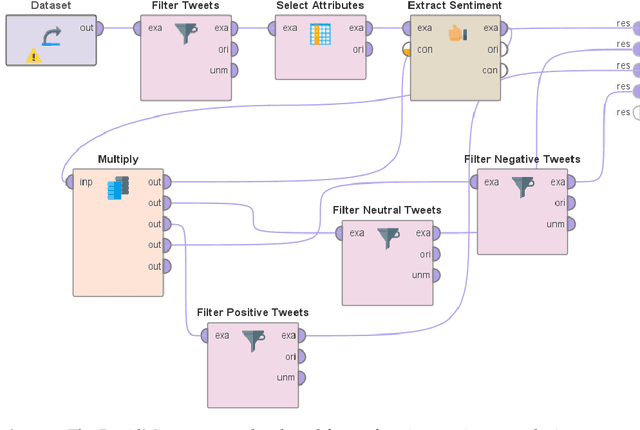

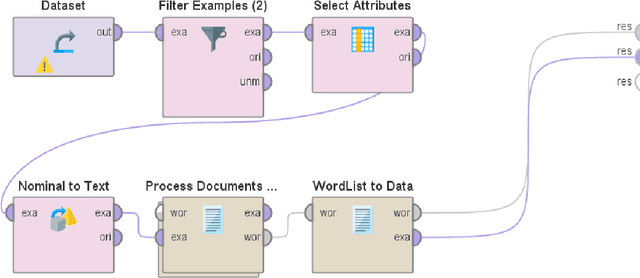
Mining and analysis of the big data of Twitter conversations have been of significant interest to the scientific community in the fields of healthcare, epidemiology, big data, data science, computer science, and their related areas, as can be seen from several works in the last few years that focused on sentiment analysis and other forms of text analysis of tweets related to Ebola, E-Coli, Dengue, Human Papillomavirus, Middle East Respiratory Syndrome, Measles, Zika virus, H1N1, influenza like illness, swine flu, flu, Cholera, Listeriosis, cancer, Liver Disease, Inflammatory Bowel Disease, kidney disease, lupus, Parkinsons, Diphtheria, and West Nile virus. The recent outbreaks of COVID-19 and MPox have served as catalysts for Twitter usage related to seeking and sharing information, views, opinions, and sentiments involving both of these viruses. None of the prior works in this field analyzed tweets focusing on both COVID-19 and MPox simultaneously. To address this research gap, a total of 61,862 tweets that focused on MPox and COVID-19 simultaneously, posted between 7 May 2022 and 3 March 2023, were studied. The findings and contributions of this study are manifold. First, the results of sentiment analysis using the VADER approach show that nearly half the tweets had a negative sentiment. It was followed by tweets that had a positive sentiment and tweets that had a neutral sentiment, respectively. Second, this paper presents the top 50 hashtags used in these tweets. Third, it presents the top 100 most frequently used words in these tweets after performing tokenization, removal of stopwords, and word frequency analysis. Finally, a comprehensive comparative study that compares the contributions of this paper with 49 prior works in this field is presented to further uphold the relevance and novelty of this work.
A Simplistic and Cost-Effective Design for Real-World Development of an Ambient Assisted Living System for Fall Detection and Indoor Localization: Proof of Concept
Jul 24, 2022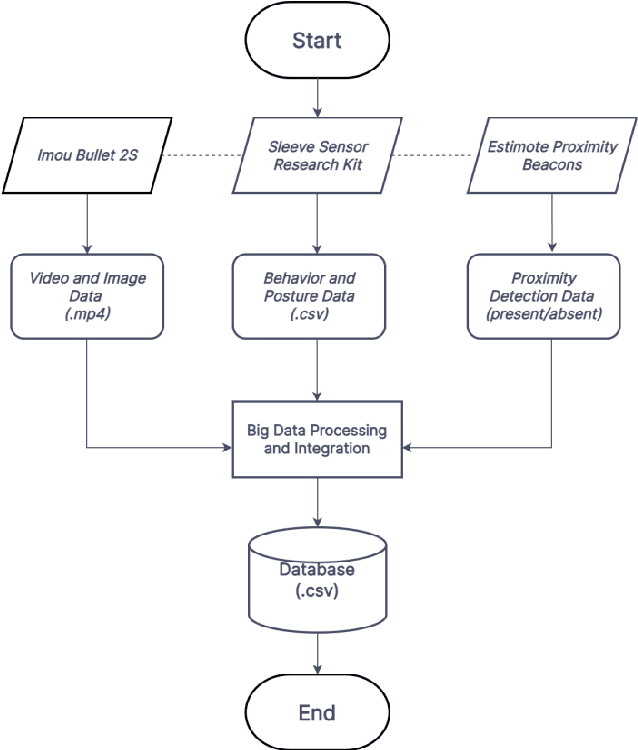
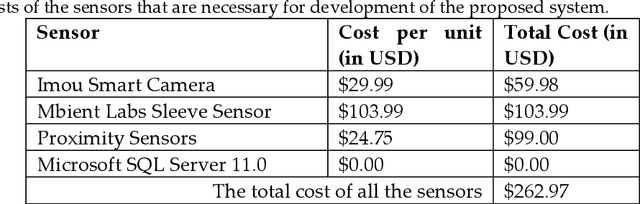

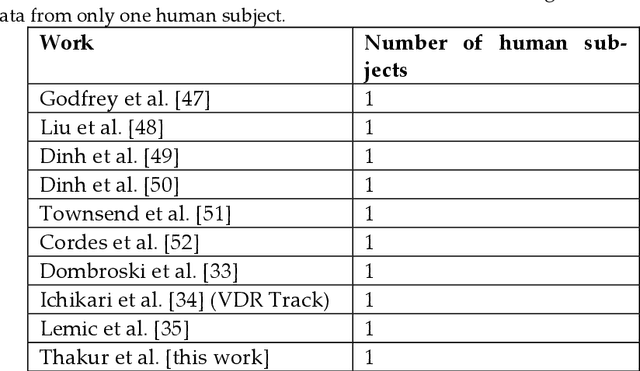
Falls, highly common in the constantly increasing global aging population, can have a variety of negative effects on their health, well-being, and quality of life, including restricting their capabilities to conduct Activities of Daily Living (ADLs), which are crucial for one's sustenance. Timely assistance during falls is highly necessary, which involves tracking the indoor location of the elderly during their diverse navigational patterns associated with ADLs to detect the precise location of a fall. With the decreasing caregiver population on a global scale, it is important that the future of intelligent living environments can detect falls during ADLs while being able to track the indoor location of the elderly in the real world. To address these challenges, this work proposes a cost-effective and simplistic design paradigm for an Ambient Assisted Living system that can capture multimodal components of user behaviors during ADLs that are necessary for performing fall detection and indoor localization in a simultaneous manner in the real world. Proof of concept results from real-world experiments are presented to uphold the effective working of the system. The findings from two comparison studies with prior works in this field are also presented to uphold the novelty of this work. The first comparison study shows how the proposed system outperforms prior works in the areas of indoor localization and fall detection in terms of the effectiveness of its software design and hardware design. The second comparison study shows that the cost for the development of this system is the least as compared to prior works in these fields, which involved real-world development of the underlining systems, thereby upholding its cost-effective nature.