 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Off-Policy and On-Policy Policy Gradient Methods Align?
Feb 19, 2024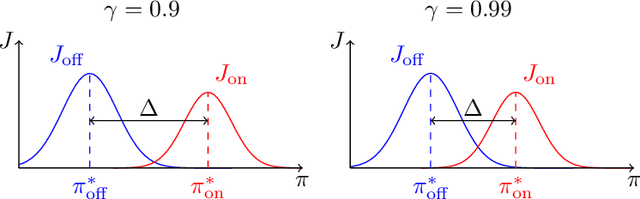
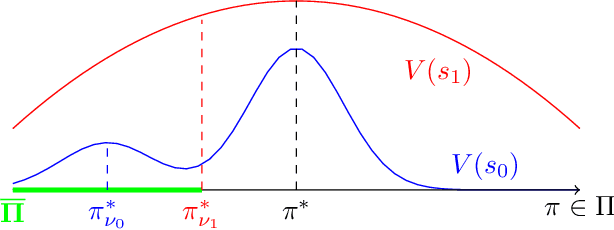
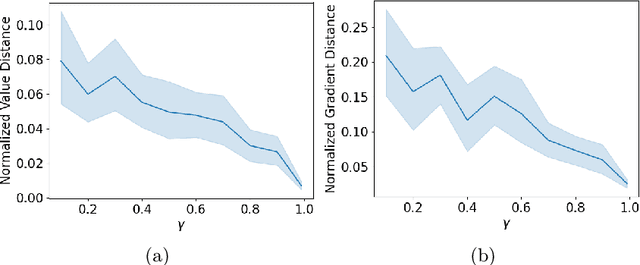
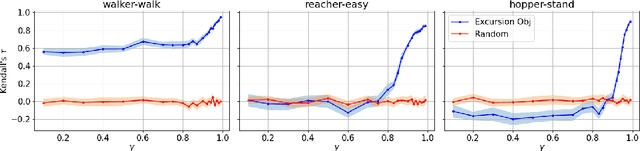
Policy gradient methods are widely adopted reinforcement learning algorithms for tasks with continuous action spaces. These methods succeeded in many application domains, however, because of their notorious sample inefficiency their use remains limited to problems where fast and accurate simulations are available. A common way to improve sample efficiency is to modify their objective function to be computable from off-policy samples without importance sampling. A well-established off-policy objective is the excursion objective. This work studies the difference between the excursion objective and the traditional on-policy objective, which we refer to as the on-off gap. We provide the first theoretical analysis showing conditions to reduce the on-off gap while establishing empirical evidence of shortfalls arising when these conditions are not met.
Compositional Multi-Object Reinforcement Learning with Linear Relation Networks
Jan 31, 2022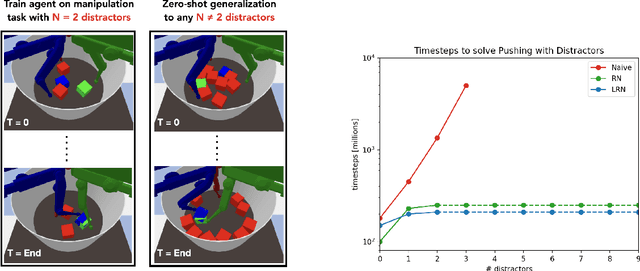

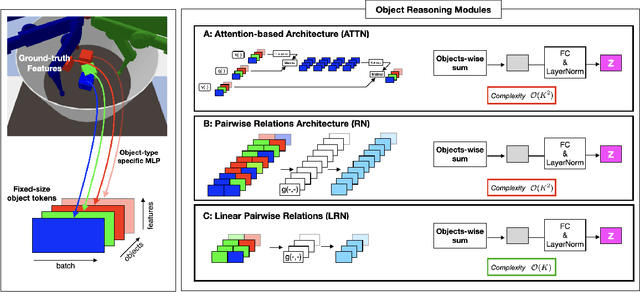
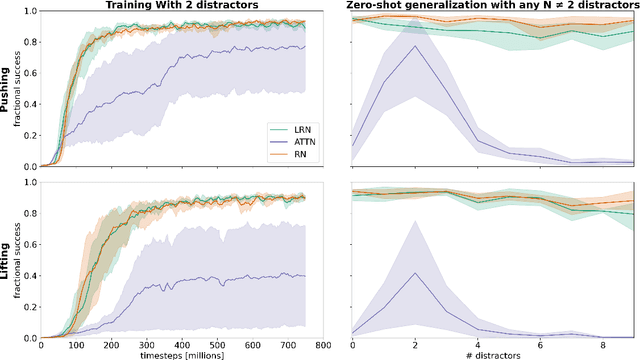
Although reinforcement learning has seen remarkable progress over the last years, solving robust dexterous object-manipulation tasks in multi-object settings remains a challenge. In this paper, we focus on models that can learn manipulation tasks in fixed multi-object settings and extrapolate this skill zero-shot without any drop in performance when the number of objects changes. We consider the generic task of bringing a specific cube out of a set to a goal position. We find that previous approaches, which primarily leverage attention and graph neural network-based architectures, do not generalize their skills when the number of input objects changes while scaling as $K^2$. We propose an alternative plug-and-play module based on relational inductive biases to overcome these limitations. Besides exceeding performances in their training environment, we show that our approach, which scales linearly in $K$, allows agents to extrapolate and generalize zero-shot to any new object number.