 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Off-Policy and On-Policy Policy Gradient Methods Align?
Paper and Code
Feb 19, 2024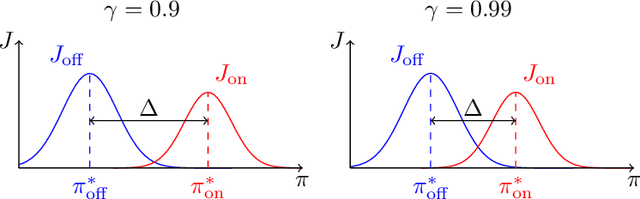
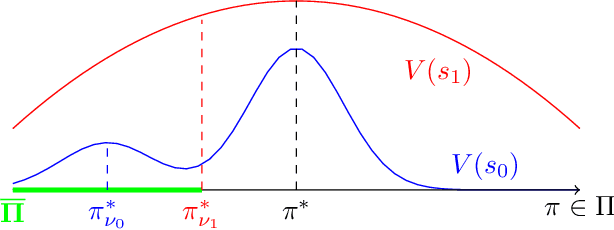
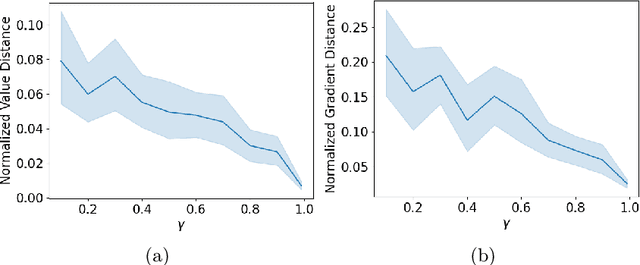
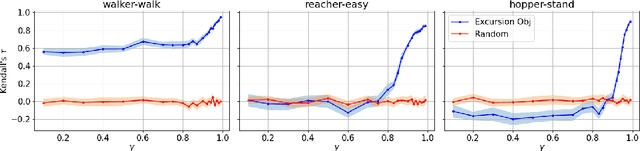
Policy gradient methods are widely adopted reinforcement learning algorithms for tasks with continuous action spaces. These methods succeeded in many application domains, however, because of their notorious sample inefficiency their use remains limited to problems where fast and accurate simulations are available. A common way to improve sample efficiency is to modify their objective function to be computable from off-policy samples without importance sampling. A well-established off-policy objective is the excursion objective. This work studies the difference between the excursion objective and the traditional on-policy objective, which we refer to as the on-off gap. We provide the first theoretical analysis showing conditions to reduce the on-off gap while establishing empirical evidence of shortfalls arising when these conditions are not met.