 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and Application of Self-Supervised Machine Learning for Smoke Plume and Active Fire Identification from the FIREX-AQ Datasets
Jan 25, 2025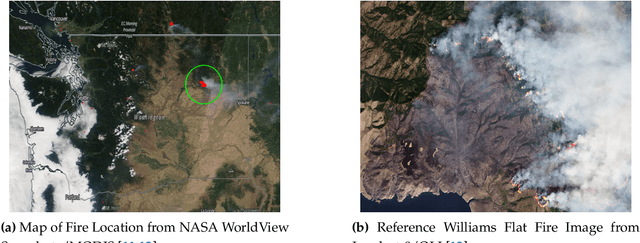
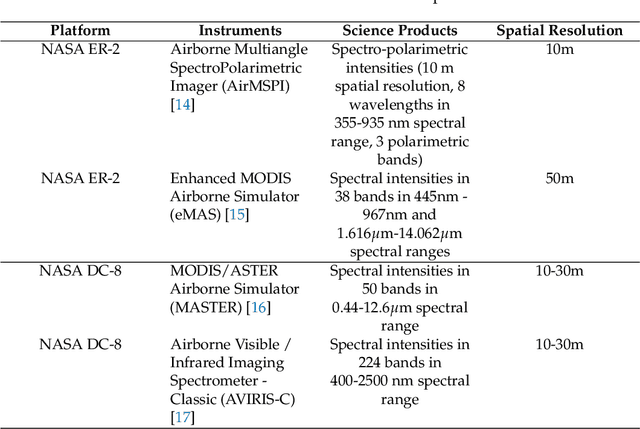
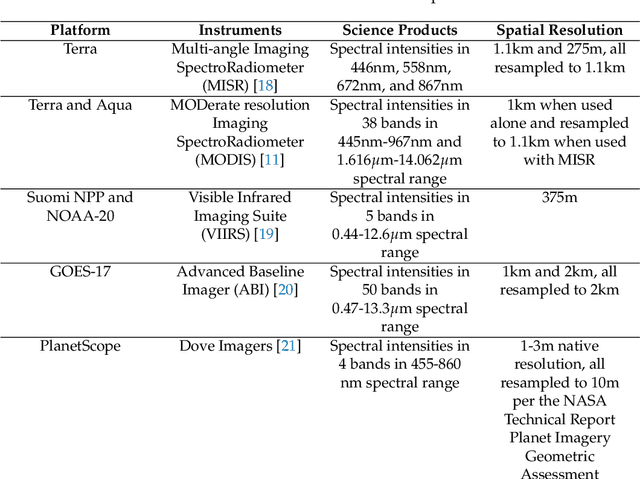

Fire Influence on Regional to Global Environments and Air Quality (FIREX-AQ) was a field campaign aimed at better understanding the impact of wildfires and agricultural fires on air quality and climate. The FIREX-AQ campaign took place in August 2019 and involved two aircraft and multiple coordinated satellite observations. This study applied and evaluated a self-supervised machine learning (ML) method for the active fire and smoke plume identification and tracking in the satellite and sub-orbital remote sensing datasets collected during the campaign. Our unique methodology combines remote sensing observations with different spatial and spectral resolutions. The demonstrated approach successfully differentiates fire pixels and smoke plumes from background imagery, enabling the generation of a per-instrument smoke and fire mask product, as well as smoke and fire masks created from the fusion of selected data from independent instruments. This ML approach has a potential to enhance operational wildfire monitoring systems and improve decision-making in air quality management through fast smoke plume identification12 and tracking and could improve climate impact studies through fusion data from independent instruments.
A Fortran-Keras Deep Learning Bridge for Scientific Computing
Apr 14, 2020

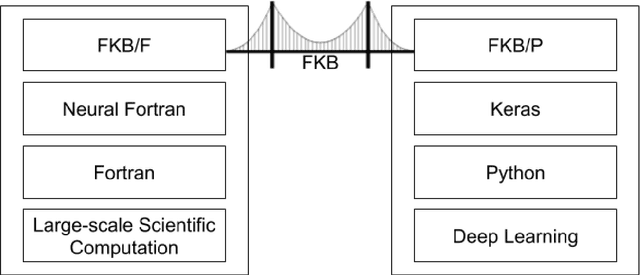
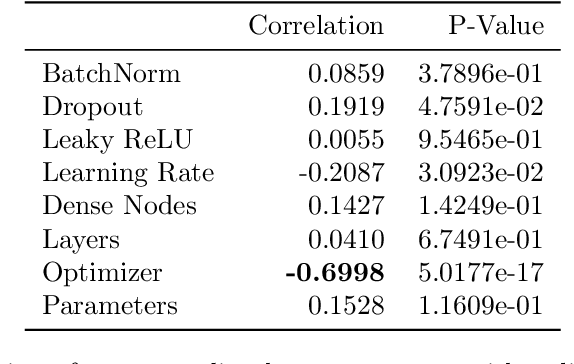
Implementing artificial neural networks is commonly achieved via high-level programming languages like Python, and easy-to-use deep learning libraries like Keras. These software libraries come pre-loaded with a variety of network architectures, provide autodifferentiation, and support GPUs for fast and efficient computation. As a result, a deep learning practitioner will favor training a neural network model in Python where these tools are readily available. However, many large-scale scientific computation projects are written in Fortran, which makes them difficult to integrate with modern deep learning methods. To alleviate this problem, we introduce a software library, the Fortran-Keras Bridge (FKB). This two-way bridge connects environments where deep learning resources are plentiful, with those where they are scarce. The paper describes a number of unique features offered by FKB, such as customizable layers, loss functions, and network ensembles. The paper concludes with a case study that applies FKB to address open questions about the robustness of an experimental approach to global climate simulation, in which subgrid physics are outsourced to deep neural network emulators. In this context, FKB enables a hyperparameter search of one hundred plus candidate models of subgrid cloud and radiation physics, initially implemented in Keras, to then be transferred and used in Fortran to assess their emergent behavior, i.e. when fit imperfections are coupled to explicit planetary scale fluid dynamics. The results reveal a previously unrecognized strong relationship between offline validation error and online performance, in which the choice of optimizer proves unexpectedly critical; this in turn helps identify a new optimized NN that demonstrates a 500 fold improvement of model stability compared to previously published results for this application.
Exploring the Efficacy of Transfer Learning in Mining Image-Based Software Artifacts
Mar 03, 2020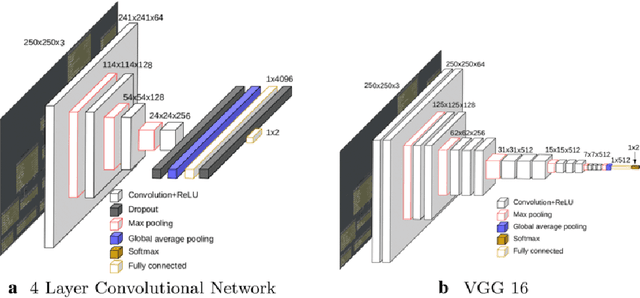
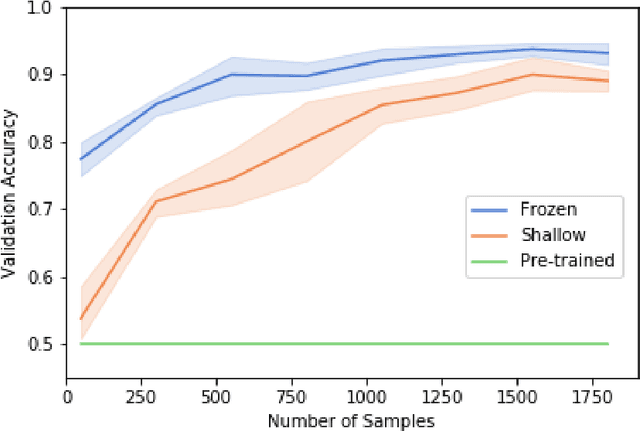
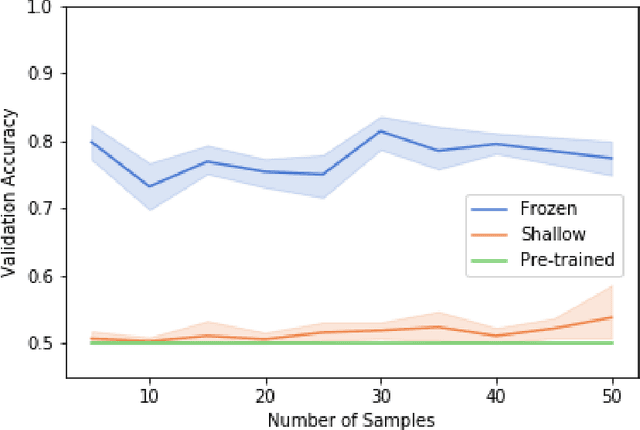
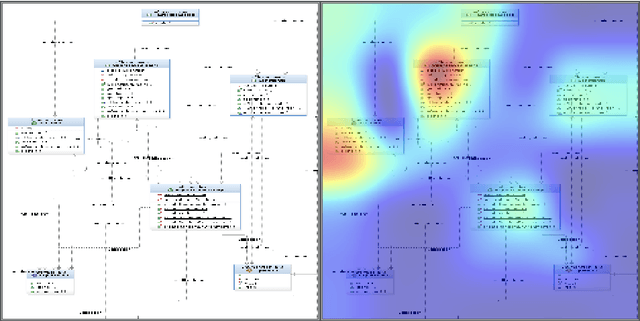
Transfer learning allows us to train deep architectures requiring a large number of learned parameters, even if the amount of available data is limited, by leveraging existing models previously trained for another task. Here we explore the applicability of transfer learning utilizing models pre-trained on non-software engineering data applied to the problem of classifying software UML diagrams. Our experimental results show training reacts positively to transfer learning as related to sample size, even though the pre-trained model was not exposed to training instances from the software domain. We contrast the transferred network with other networks to show its advantage on different sized training sets, which indicates that transfer learning is equally effective to custom deep architectures when large amounts of training data is not available.
Learning in the Machine: To Share or Not to Share?
Oct 04, 2019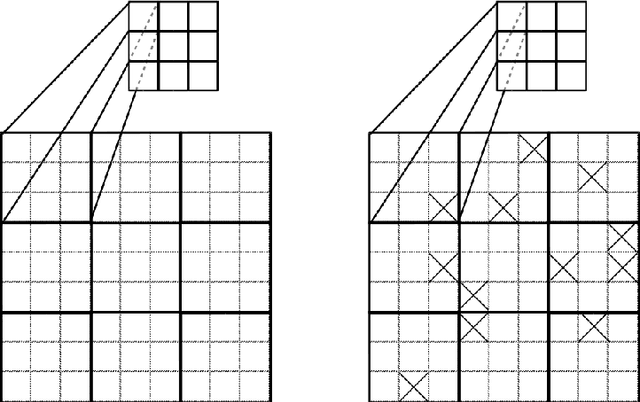
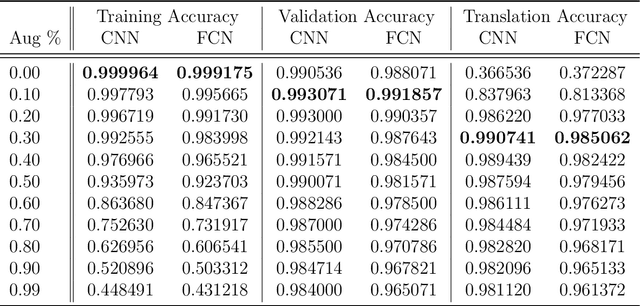
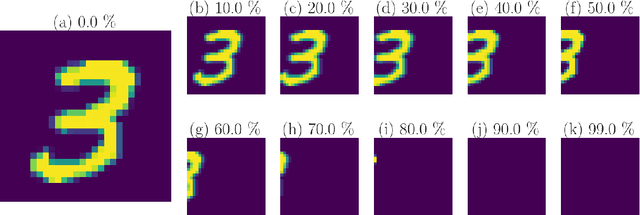
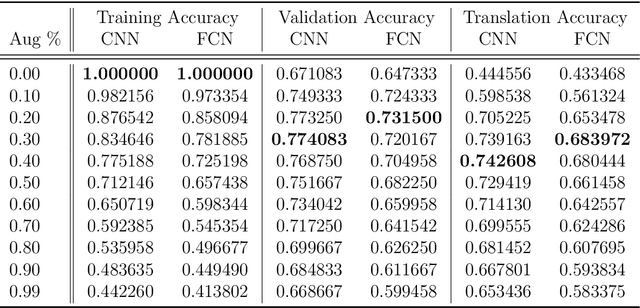
Weight-sharing is one of the pillars behind Convolutional Neural Networks and their successes. However, in physical neural systems such as the brain, weight-sharing is implausible. This discrepancy raises the fundamental question of whether weight-sharing is necessary. If so, to which degree of precision? If not, what are the alternatives? The goal of this study is to investigate these questions, primarily through simulations where the weight-sharing assumption is relaxed. Taking inspiration from neural circuitry, we explore the use of Free Convolutional Networks and neurons with variable connection patterns. Using Free Convolutional Networks, we show that while weight-sharing is a pragmatic optimization approach, it is not a necessity in computer vision applications. Furthermore, Free Convolutional Networks match the performance observed in standard architectures when trained using properly translated data (akin to video). Under the assumption of translationally augmented data, Free Convolutional Networks learn translationally invariant representations that yield an approximate form of weight sharing.