 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Visualizing Droplet Distributions in Simulations of Shallow Clouds
Oct 31, 2023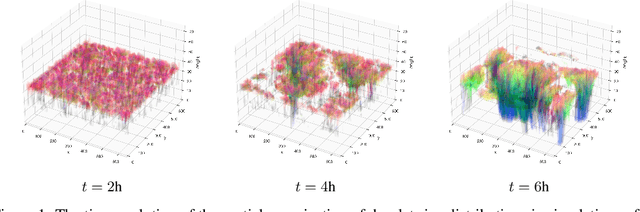
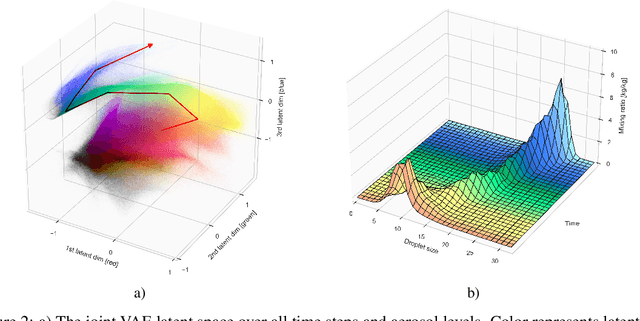
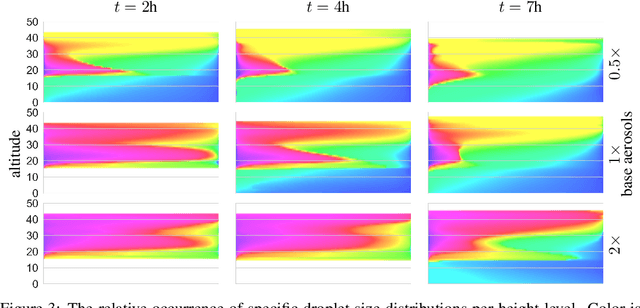
Thorough analysis of local droplet-level interactions is crucial to better understand the microphysical processes in clouds and their effect on the global climate. High-accuracy simulations of relevant droplet size distributions from Large Eddy Simulations (LES) of bin microphysics challenge current analysis techniques due to their high dimensionality involving three spatial dimensions, time, and a continuous range of droplet sizes. Utilizing the compact latent representations from Variational Autoencoders (VAEs), we produce novel and intuitive visualizations for the organization of droplet sizes and their evolution over time beyond what is possible with clustering techniques. This greatly improves interpretation and allows us to examine aerosol-cloud interactions by contrasting simulations with different aerosol concentrations. We find that the evolution of the droplet spectrum is similar across aerosol levels but occurs at different paces. This similarity suggests that precipitation initiation processes are alike despite variations in onset times.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Two-step hyperparameter optimization method: Accelerating hyperparameter search by using a fraction of a training dataset
Feb 08, 2023


Hyperparameter optimization (HPO) can be an important step in machine learning model development, but our common practice is archaic -- primarily using a manual or grid search. This is partly because adopting an advanced HPO algorithm entails extra complexity to workflow and longer computation time. This imposes a significant hurdle to machine learning (ML) applications since the choice of suboptimal hyperparameters limits the performance of ML models, ultimately failing to harness the full potential of ML techniques. In this article, we present a two-step HPO method as a strategy to minimize compute and wait time as a lesson learned during applied ML parameterization work. A preliminary evaluation of hyperparameters is first conducted on a small subset of a training dataset, then top-performing candidate models are re-evaluated after retraining with an entire training dataset. This two-step HPO method can be applied to any HPO search algorithm, and we argue it has attractive efficiencies. As a case study, we present our recent application of the two-step HPO method to the development of neural network emulators of aerosol activation. Using only 5% of a training dataset in the initial step is sufficient to find optimal hyperparameter configurations from much more extensive sampling. The benefits of HPO are then revealed by analysis of hyperparameters and model performance, revealing a minimal model complexity required to achieve the best performance, and the diversity of top-performing models harvested from the HPO process allows us to choose a high-performing model with a low inference cost for efficient use in GCMs.