 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering New Interpretable Conservation Laws as Sparse Invariants
Jun 06, 2023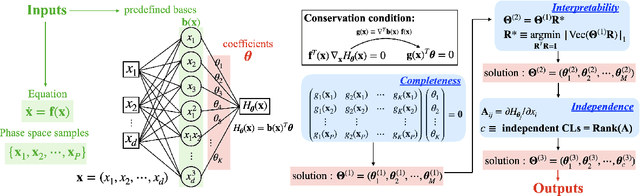
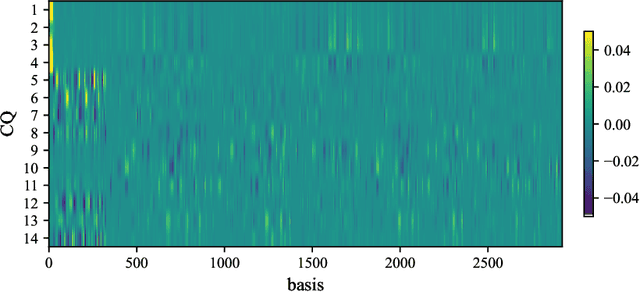
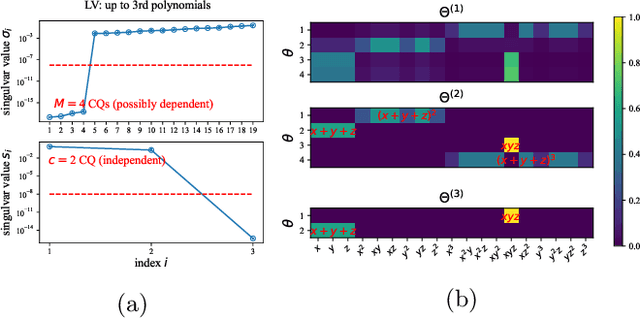

Discovering conservation laws for a given dynamical system is important but challenging. In a theorist setup (differential equations and basis functions are both known), we propose the Sparse Invariant Detector (SID), an algorithm that auto-discovers conservation laws from differential equations. Its algorithmic simplicity allows robustness and interpretability of the discovered conserved quantities. We show that SID is able to rediscover known and even discover new conservation laws in a variety of systems. For two examples in fluid mechanics and atmospheric chemistry, SID discovers 14 and 3 conserved quantities, respectively, where only 12 and 2 were previously known to domain experts.
Two-step hyperparameter optimization method: Accelerating hyperparameter search by using a fraction of a training dataset
Feb 08, 2023


Hyperparameter optimization (HPO) can be an important step in machine learning model development, but our common practice is archaic -- primarily using a manual or grid search. This is partly because adopting an advanced HPO algorithm entails extra complexity to workflow and longer computation time. This imposes a significant hurdle to machine learning (ML) applications since the choice of suboptimal hyperparameters limits the performance of ML models, ultimately failing to harness the full potential of ML techniques. In this article, we present a two-step HPO method as a strategy to minimize compute and wait time as a lesson learned during applied ML parameterization work. A preliminary evaluation of hyperparameters is first conducted on a small subset of a training dataset, then top-performing candidate models are re-evaluated after retraining with an entire training dataset. This two-step HPO method can be applied to any HPO search algorithm, and we argue it has attractive efficiencies. As a case study, we present our recent application of the two-step HPO method to the development of neural network emulators of aerosol activation. Using only 5% of a training dataset in the initial step is sufficient to find optimal hyperparameter configurations from much more extensive sampling. The benefits of HPO are then revealed by analysis of hyperparameters and model performance, revealing a minimal model complexity required to achieve the best performance, and the diversity of top-performing models harvested from the HPO process allows us to choose a high-performing model with a low inference cost for efficient use in GCMs.