 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Direct Preference Optimization
Feb 04, 2025



A major challenge in aligning large language models (LLMs) with human preferences is the issue of distribution shift. LLM alignment algorithms rely on static preference datasets, assuming that they accurately represent real-world user preferences. However, user preferences vary significantly across geographical regions, demographics, linguistic patterns, and evolving cultural trends. This preference distribution shift leads to catastrophic alignment failures in many real-world applications. We address this problem using the principled framework of distributionally robust optimization, and develop two novel distributionally robust direct preference optimization (DPO) algorithms, namely, Wasserstein DPO (WDPO) and Kullback-Leibler DPO (KLDPO). We characterize the sample complexity of learning the optimal policy parameters for WDPO and KLDPO. Moreover, we propose scalable gradient descent-style learning algorithms by developing suitable approximations for the challenging minimax loss functions of WDPO and KLDPO. Our empirical experiments demonstrate the superior performance of WDPO and KLDPO in substantially improving the alignment when there is a preference distribution shift.
Bridging Distributionally Robust Learning and Offline RL: An Approach to Mitigate Distribution Shift and Partial Data Coverage
Oct 27, 2023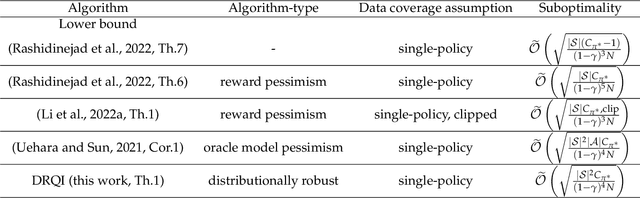
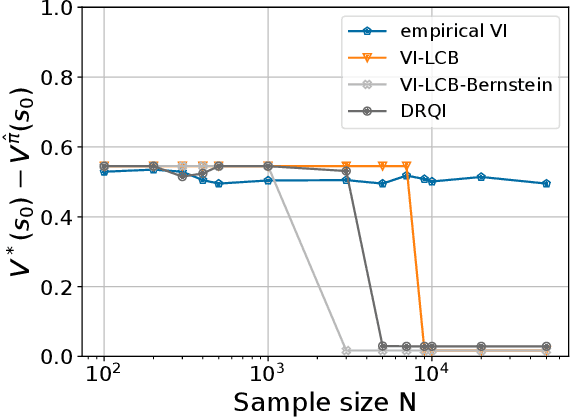

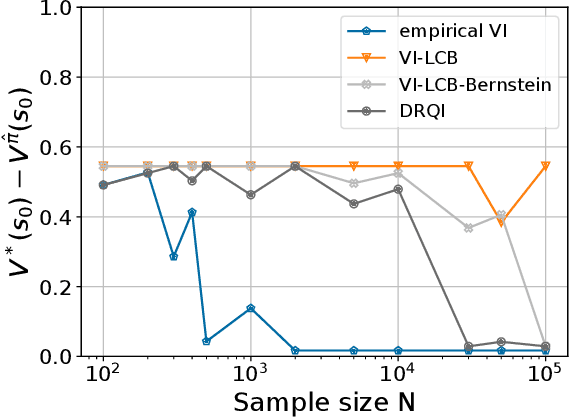
The goal of an offline reinforcement learning (RL) algorithm is to learn optimal polices using historical (offline) data, without access to the environment for online exploration. One of the main challenges in offline RL is the distribution shift which refers to the difference between the state-action visitation distribution of the data generating policy and the learning policy. Many recent works have used the idea of pessimism for developing offline RL algorithms and characterizing their sample complexity under a relatively weak assumption of single policy concentrability. Different from the offline RL literature, the area of distributionally robust learning (DRL) offers a principled framework that uses a minimax formulation to tackle model mismatch between training and testing environments. In this work, we aim to bridge these two areas by showing that the DRL approach can be used to tackle the distributional shift problem in offline RL. In particular, we propose two offline RL algorithms using the DRL framework, for the tabular and linear function approximation settings, and characterize their sample complexity under the single policy concentrability assumption. We also demonstrate the superior performance our proposed algorithm through simulation experiments.
Improved Sample Complexity Bounds for Distributionally Robust Reinforcement Learning
Mar 05, 2023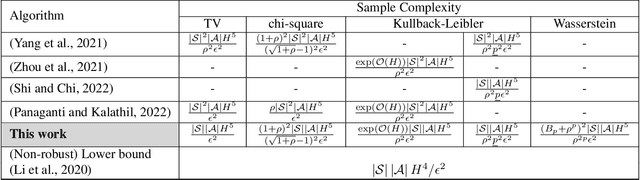
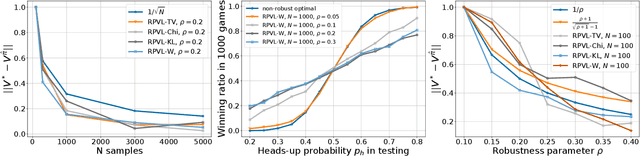
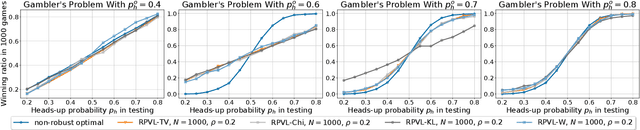
We consider the problem of learning a control policy that is robust against the parameter mismatches between the training environment and testing environment. We formulate this as a distributionally robust reinforcement learning (DR-RL) problem where the objective is to learn the policy which maximizes the value function against the worst possible stochastic model of the environment in an uncertainty set. We focus on the tabular episodic learning setting where the algorithm has access to a generative model of the nominal (training) environment around which the uncertainty set is defined. We propose the Robust Phased Value Learning (RPVL) algorithm to solve this problem for the uncertainty sets specified by four different divergences: total variation, chi-square, Kullback-Leibler, and Wasserstein. We show that our algorithm achieves $\tilde{\mathcal{O}}(|\mathcal{S}||\mathcal{A}| H^{5})$ sample complexity, which is uniformly better than the existing results by a factor of $|\mathcal{S}|$, where $|\mathcal{S}|$ is number of states, $|\mathcal{A}|$ is the number of actions, and $H$ is the horizon length. We also provide the first-ever sample complexity result for the Wasserstein uncertainty set. Finally, we demonstrate the performance of our algorithm using simulation experiments.
Robust Reinforcement Learning using Offline Data
Aug 10, 2022
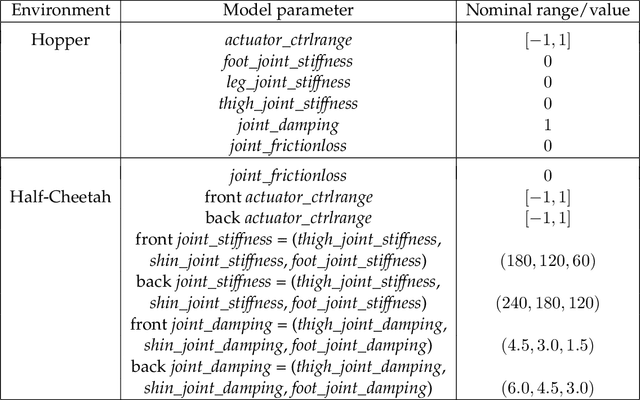


The goal of robust reinforcement learning (RL) is to learn a policy that is robust against the uncertainty in model parameters. Parameter uncertainty commonly occurs in many real-world RL applications due to simulator modeling errors, changes in the real-world system dynamics over time, and adversarial disturbances. Robust RL is typically formulated as a max-min problem, where the objective is to learn the policy that maximizes the value against the worst possible models that lie in an uncertainty set. In this work, we propose a robust RL algorithm called Robust Fitted Q-Iteration (RFQI), which uses only an offline dataset to learn the optimal robust policy. Robust RL with offline data is significantly more challenging than its non-robust counterpart because of the minimization over all models present in the robust Bellman operator. This poses challenges in offline data collection, optimization over the models, and unbiased estimation. In this work, we propose a systematic approach to overcome these challenges, resulting in our RFQI algorithm. We prove that RFQI learns a near-optimal robust policy under standard assumptions and demonstrate its superior performance on standard benchmark problems.